 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Operational Automated Greenhouse Gas Plume Detection
May 27, 2025Operational deployment of a fully automated greenhouse gas (GHG) plume detection system remains an elusive goal for imaging spectroscopy missions, despite recent advances in deep learning approaches. With the dramatic increase in data availability, however, automation continues to increase in importance for natural and anthropogenic emissions monitoring. This work reviews and addresses several key obstacles in the field: data and label quality control, prevention of spatiotemporal biases, and correctly aligned modeling objectives. We demonstrate through rigorous experiments using multicampaign data from airborne and spaceborne instruments that convolutional neural networks (CNNs) are able to achieve operational detection performance when these obstacles are alleviated. We demonstrate that a multitask model that learns both instance detection and pixelwise segmentation simultaneously can successfully lead towards an operational pathway. We evaluate the model's plume detectability across emission source types and regions, identifying thresholds for operational deployment. Finally, we provide analysis-ready data, models, and source code for reproducibility, and work to define a set of best practices and validation standards to facilitate future contributions to the field.
SpecTf: Transformers Enable Data-Driven Imaging Spectroscopy Cloud Detection
Jan 09, 2025



Current and upcoming generations of visible-shortwave infrared (VSWIR) imaging spectrometers promise unprecedented capacity to quantify Earth System processes across the globe. However, reliable cloud screening remains a fundamental challenge for these instruments, where traditional spatial and temporal approaches are limited by cloud variability and limited temporal coverage. The Spectroscopic Transformer (SpecTf) addresses these challenges with a spectroscopy-specific deep learning architecture that performs cloud detection using only spectral information (no spatial or temporal data are required). By treating spectral measurements as sequences rather than image channels, SpecTf learns fundamental physical relationships without relying on spatial context. Our experiments demonstrate that SpecTf significantly outperforms the current baseline approach implemented for the EMIT instrument, and performs comparably with other machine learning methods with orders of magnitude fewer learned parameters. Critically, we demonstrate SpecTf's inherent interpretability through its attention mechanism, revealing physically meaningful spectral features the model has learned. Finally, we present SpecTf's potential for cross-instrument generalization by applying it to a different instrument on a different platform without modifications, opening the door to instrument agnostic data driven algorithms for future imaging spectroscopy tasks.
K-textures, a self supervised hard clustering deep learning algorithm for satellite images segmentation
May 18, 2022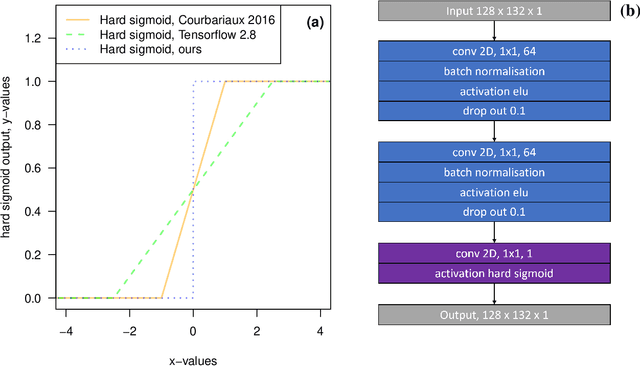
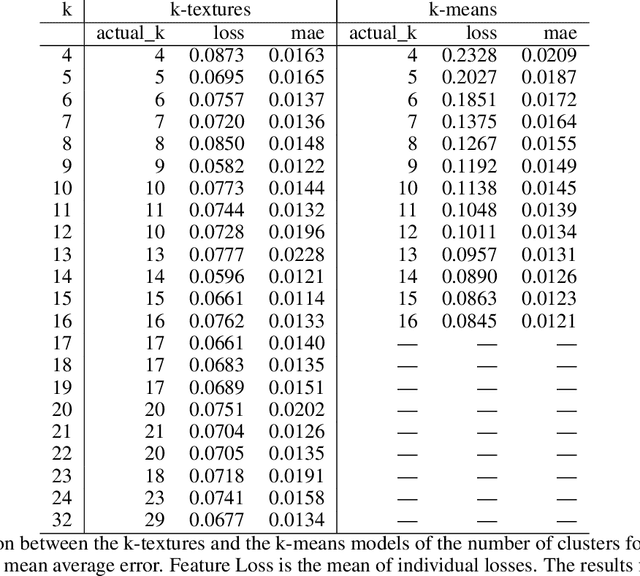
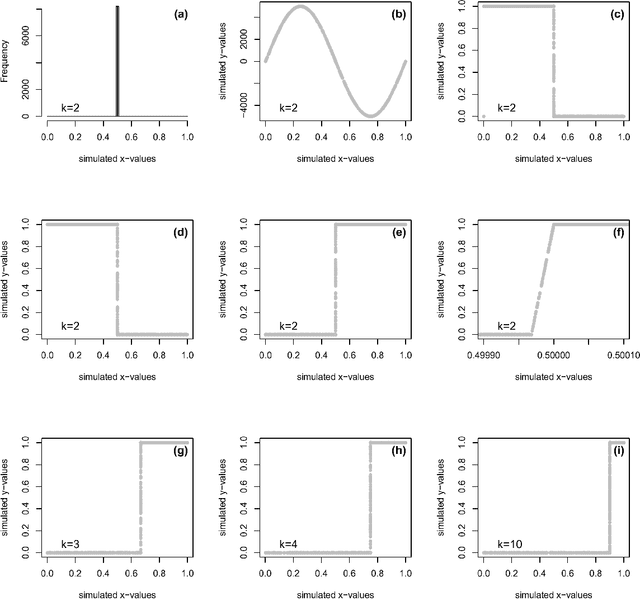
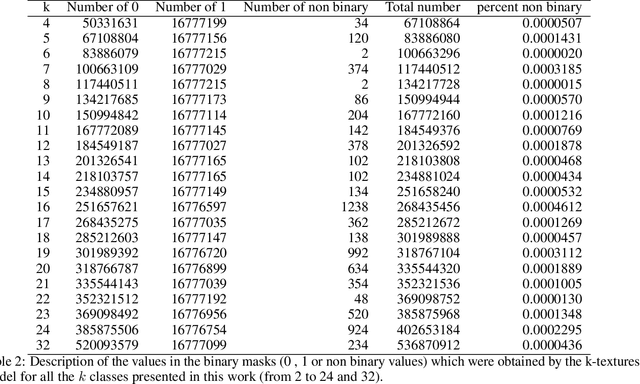
Deep learning self supervised algorithms that can segment an image in a fixed number of hard labels such as the k-means algorithm and only relying only on deep learning techniques are still lacking. Here, we introduce the k-textures algorithm which provides self supervised segmentation of a 4-band image (RGB-NIR) for a $k$ number of classes. An example of its application on high resolution Planet satellite imagery is given. Our algorithm shows that discrete search is feasible using convolutional neural networks (CNN) and gradient descent. The model detects $k$ hard clustering classes represented in the model as $k$ discrete binary masks and their associated $k$ independently generated textures, that combined are a simulation of the original image. The similarity loss is the mean squared error between the features of the original and the simulated image, both extracted from the penultimate convolutional block of Keras 'imagenet' pretrained VGG-16 model and a custom feature extractor made with Planet data. The main advances of the k-textures model are: first, the $k$ discrete binary masks are obtained inside the model using gradient descent. The model allows for the generation of discrete binary masks using a novel method using a hard sigmoid activation function. Second, it provides hard clustering classes -- each pixels has only one class. Finally, in comparison to k-means, where each pixel is considered independently, here, contextual information is also considered and each class is not associated only to a similar values in the color channels but to a texture. Our approach is designed to ease the production of training samples for satellite image segmentation. The model codes and weights are available at https://doi.org/10.5281/zenodo.6359859
Visualizing Image Content to Explain Novel Image Discovery
Aug 14, 2019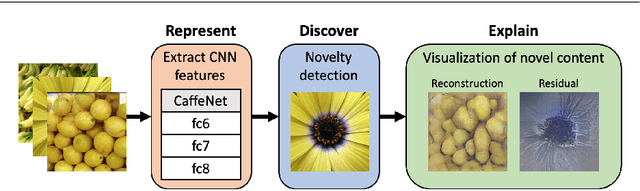
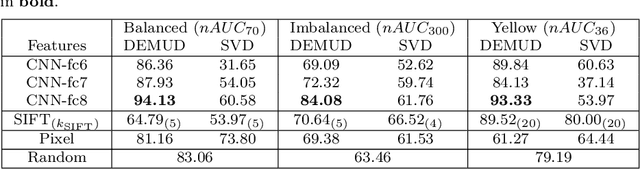

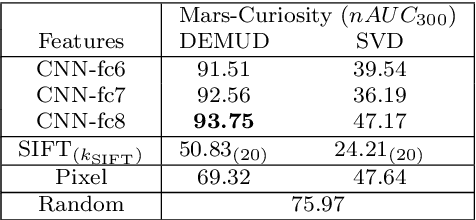
The initial analysis of any large data set can be divided into two phases: (1) the identification of common trends or patterns and (2) the identification of anomalies or outliers that deviate from those trends. We focus on the goal of detecting observations with novel content, which can alert us to artifacts in the data set or, potentially, the discovery of previously unknown phenomena. To aid in interpreting and diagnosing the novel aspect of these selected observations, we recommend the use of novelty detection methods that generate explanations. In the context of large image data sets, these explanations should highlight what aspect of a given image is new (color, shape, texture, content) in a human-comprehensible form. We propose DEMUD-VIS, the first method for providing visual explanations of novel image content by employing a convolutional neural network (CNN) to extract image features, a method that uses reconstruction error to detect novel content, and an up-convolutional network to convert CNN feature representations back into image space. We demonstrate this approach on diverse images from ImageNet, freshwater streams, and the surface of Mars.