 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelightable and Dynamic Gaussian Avatar Reconstruction from Monocular Video
Dec 11, 2025Modeling relightable and animatable human avatars from monocular video is a long-standing and challenging task. Recently, Neural Radiance Field (NeRF) and 3D Gaussian Splatting (3DGS) methods have been employed to reconstruct the avatars. However, they often produce unsatisfactory photo-realistic results because of insufficient geometrical details related to body motion, such as clothing wrinkles. In this paper, we propose a 3DGS-based human avatar modeling framework, termed as Relightable and Dynamic Gaussian Avatar (RnD-Avatar), that presents accurate pose-variant deformation for high-fidelity geometrical details. To achieve this, we introduce dynamic skinning weights that define the human avatar's articulation based on pose while also learning additional deformations induced by body motion. We also introduce a novel regularization to capture fine geometric details under sparse visual cues. Furthermore, we present a new multi-view dataset with varied lighting conditions to evaluate relight. Our framework enables realistic rendering of novel poses and views while supporting photo-realistic lighting effects under arbitrary lighting conditions. Our method achieves state-of-the-art performance in novel view synthesis, novel pose rendering, and relighting.
* 8 pages, 9 figures, published in ACM MM 2025
TRAVEL: Traversable Ground and Above-Ground Object Segmentation Using Graph Representation of 3D LiDAR Scans
Jun 07, 2022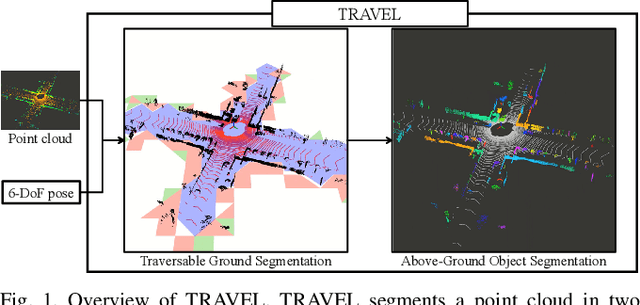
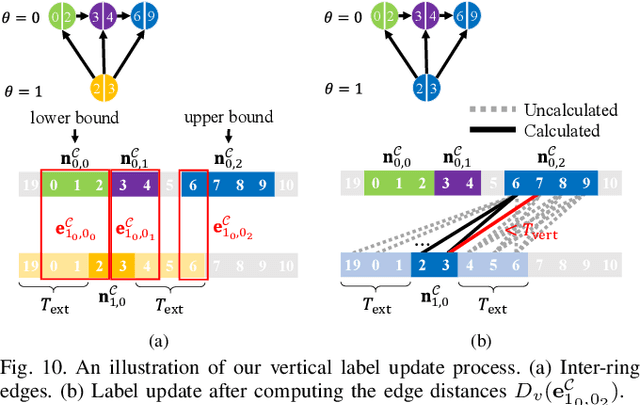
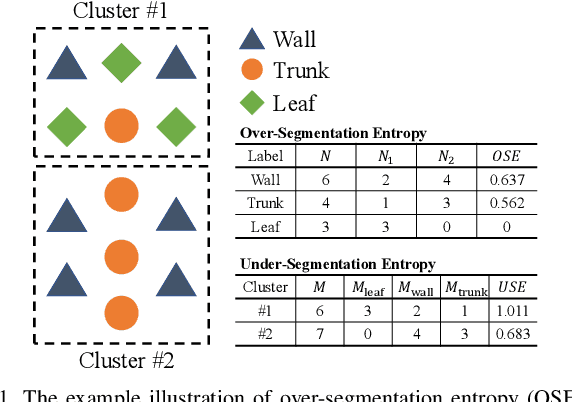
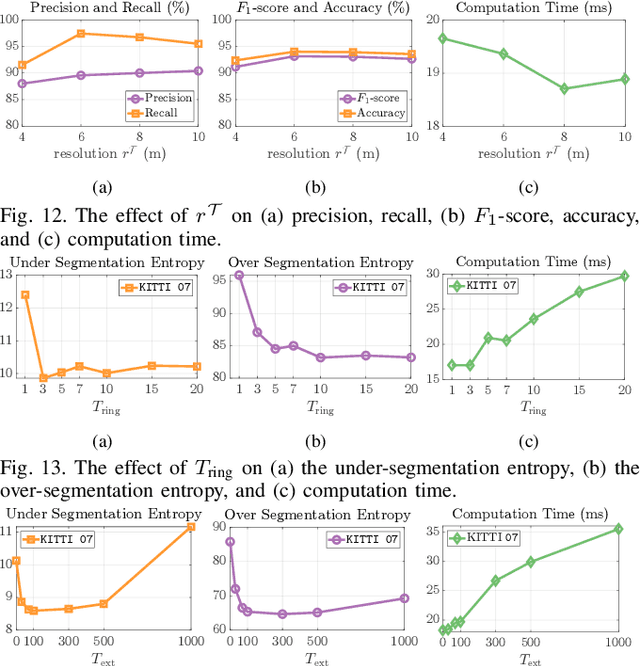
Perception of traversable regions and objects of interest from a 3D point cloud is one of the critical tasks in autonomous navigation. A ground vehicle needs to look for traversable terrains that are explorable by wheels. Then, to make safe navigation decisions, the segmentation of objects positioned on those terrains has to be followed up. However, over-segmentation and under-segmentation can negatively influence such navigation decisions. To that end, we propose TRAVEL, which performs traversable ground detection and object clustering simultaneously using the graph representation of a 3D point cloud. To segment the traversable ground, a point cloud is encoded into a graph structure, tri-grid field, which treats each tri-grid as a node. Then, the traversable regions are searched and redefined by examining local convexity and concavity of edges that connect nodes. On the other hand, our above-ground object segmentation employs a graph structure by representing a group of horizontally neighboring 3D points in a spherical-projection space as a node and vertical/horizontal relationship between nodes as an edge. Fully leveraging the node-edge structure, the above-ground segmentation ensures real-time operation and mitigates over-segmentation. Through experiments using simulations, urban scenes, and our own datasets, we have demonstrated that our proposed traversable ground segmentation algorithm outperforms other state-of-the-art methods in terms of the conventional metrics and that our newly proposed evaluation metrics are meaningful for assessing the above-ground segmentation. We will make the code and our own dataset available to public at https://github.com/url-kaist/TRAVEL.