 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCELOT 2023: Cell Detection from Cell-Tissue Interaction Challenge
Sep 11, 2025Pathologists routinely alternate between different magnifications when examining Whole-Slide Images, allowing them to evaluate both broad tissue morphology and intricate cellular details to form comprehensive diagnoses. However, existing deep learning-based cell detection models struggle to replicate these behaviors and learn the interdependent semantics between structures at different magnifications. A key barrier in the field is the lack of datasets with multi-scale overlapping cell and tissue annotations. The OCELOT 2023 challenge was initiated to gather insights from the community to validate the hypothesis that understanding cell and tissue (cell-tissue) interactions is crucial for achieving human-level performance, and to accelerate the research in this field. The challenge dataset includes overlapping cell detection and tissue segmentation annotations from six organs, comprising 673 pairs sourced from 306 The Cancer Genome Atlas (TCGA) Whole-Slide Images with hematoxylin and eosin staining, divided into training, validation, and test subsets. Participants presented models that significantly enhanced the understanding of cell-tissue relationships. Top entries achieved up to a 7.99 increase in F1-score on the test set compared to the baseline cell-only model that did not incorporate cell-tissue relationships. This is a substantial improvement in performance over traditional cell-only detection methods, demonstrating the need for incorporating multi-scale semantics into the models. This paper provides a comparative analysis of the methods used by participants, highlighting innovative strategies implemented in the OCELOT 2023 challenge.
* This is the accepted manuscript of an article published in Medical Image Analysis (Elsevier). The final version is available at: https://doi.org/10.1016/j.media.2025.103751
ELVIS: Empowering Locality of Vision Language Pre-training with Intra-modal Similarity
Apr 11, 2023



Deep learning has shown great potential in assisting radiologists in reading chest X-ray (CXR) images, but its need for expensive annotations for improving performance prevents widespread clinical application. Visual language pre-training (VLP) can alleviate the burden and cost of annotation by leveraging routinely generated reports for radiographs, which exist in large quantities as well as in paired form (imagetext pairs). Additionally, extensions to localization-aware VLPs are being proposed to address the needs of accurate localization of abnormalities for CAD in CXR. However, we find that the formulation proposed by locality-aware VLP literatures actually leads to loss in spatial relationships required for downstream localization tasks. Therefore, we propose Empowering Locality of VLP with Intra-modal Similarity, ELVIS, a VLP aware of intra-modal locality, to better preserve the locality within radiographs or reports, which enhances the ability to comprehend location references in text reports. Our locality-aware VLP method significantly outperforms state-of-the art baselines in multiple segmentation tasks and the MS-CXR phrase grounding task. Qualitatively, ELVIS is able to focus well on regions of interest described in the report text compared to prior approaches, allowing for enhanced interpretability.
OCELOT: Overlapped Cell on Tissue Dataset for Histopathology
Mar 24, 2023



Cell detection is a fundamental task in computational pathology that can be used for extracting high-level medical information from whole-slide images. For accurate cell detection, pathologists often zoom out to understand the tissue-level structures and zoom in to classify cells based on their morphology and the surrounding context. However, there is a lack of efforts to reflect such behaviors by pathologists in the cell detection models, mainly due to the lack of datasets containing both cell and tissue annotations with overlapping regions. To overcome this limitation, we propose and publicly release OCELOT, a dataset purposely dedicated to the study of cell-tissue relationships for cell detection in histopathology. OCELOT provides overlapping cell and tissue annotations on images acquired from multiple organs. Within this setting, we also propose multi-task learning approaches that benefit from learning both cell and tissue tasks simultaneously. When compared against a model trained only for the cell detection task, our proposed approaches improve cell detection performance on 3 datasets: proposed OCELOT, public TIGER, and internal CARP datasets. On the OCELOT test set in particular, we show up to 6.79 improvement in F1-score. We believe the contributions of this paper, including the release of the OCELOT dataset at https://lunit-io.github.io/research/publications/ocelot are a crucial starting point toward the important research direction of incorporating cell-tissue relationships in computation pathology.
Sparse DETR: Efficient End-to-End Object Detection with Learnable Sparsity
Nov 29, 2021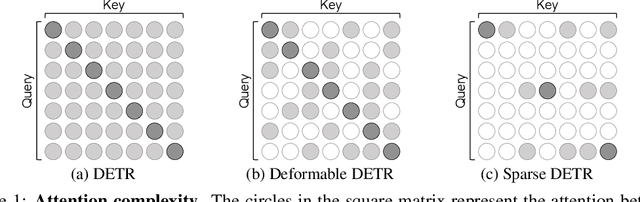
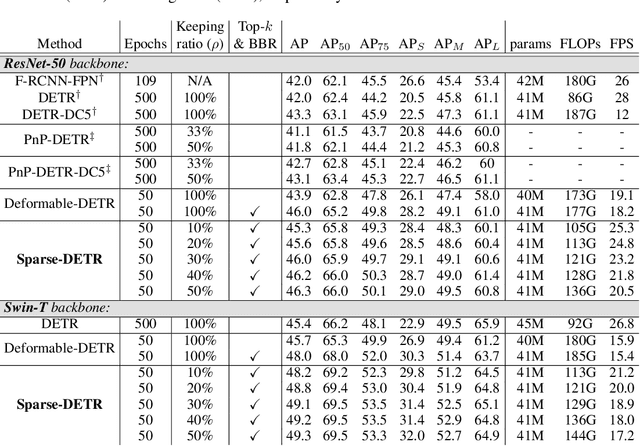
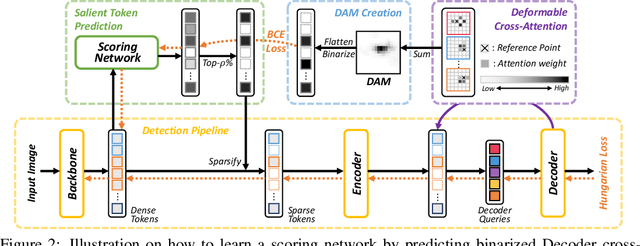
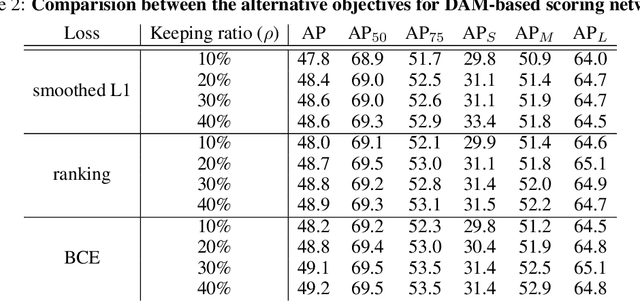
DETR is the first end-to-end object detector using a transformer encoder-decoder architecture and demonstrates competitive performance but low computational efficiency on high resolution feature maps. The subsequent work, Deformable DETR, enhances the efficiency of DETR by replacing dense attention with deformable attention, which achieves 10x faster convergence and improved performance. Deformable DETR uses the multiscale feature to ameliorate performance, however, the number of encoder tokens increases by 20x compared to DETR, and the computation cost of the encoder attention remains a bottleneck. In our preliminary experiment, we observe that the detection performance hardly deteriorates even if only a part of the encoder token is updated. Inspired by this observation, we propose Sparse DETR that selectively updates only the tokens expected to be referenced by the decoder, thus help the model effectively detect objects. In addition, we show that applying an auxiliary detection loss on the selected tokens in the encoder improves the performance while minimizing computational overhead. We validate that Sparse DETR achieves better performance than Deformable DETR even with only 10% encoder tokens on the COCO dataset. Albeit only the encoder tokens are sparsified, the total computation cost decreases by 38% and the frames per second (FPS) increases by 42% compared to Deformable DETR. Code is available at https://github.com/kakaobrain/sparse-detr