 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Channel Distance-Based Source Separation for Mobile GPU in Outdoor and Indoor Environments
Jan 06, 2025



This study emphasizes the significance of exploring distance-based source separation (DSS) in outdoor environments. Unlike existing studies that primarily focus on indoor settings, the proposed model is designed to capture the unique characteristics of outdoor audio sources. It incorporates advanced techniques, including a two-stage conformer block, a linear relation-aware self-attention (RSA), and a TensorFlow Lite GPU delegate. While the linear RSA may not capture physical cues as explicitly as the quadratic RSA, the linear RSA enhances the model's context awareness, leading to improved performance on the DSS that requires an understanding of physical cues in outdoor and indoor environments. The experimental results demonstrated that the proposed model overcomes the limitations of existing approaches and considerably enhances energy efficiency and real-time inference speed on mobile devices.
FINALLY: fast and universal speech enhancement with studio-like quality
Oct 08, 2024



In this paper, we address the challenge of speech enhancement in real-world recordings, which often contain various forms of distortion, such as background noise, reverberation, and microphone artifacts. We revisit the use of Generative Adversarial Networks (GANs) for speech enhancement and theoretically show that GANs are naturally inclined to seek the point of maximum density within the conditional clean speech distribution, which, as we argue, is essential for the speech enhancement task. We study various feature extractors for perceptual loss to facilitate the stability of adversarial training, developing a methodology for probing the structure of the feature space. This leads us to integrate WavLM-based perceptual loss into MS-STFT adversarial training pipeline, creating an effective and stable training procedure for the speech enhancement model. The resulting speech enhancement model, which we refer to as FINALLY, builds upon the HiFi++ architecture, augmented with a WavLM encoder and a novel training pipeline. Empirical results on various datasets confirm our model's ability to produce clear, high-quality speech at 48 kHz, achieving state-of-the-art performance in the field of speech enhancement.
Speech Boosting: Low-Latency Live Speech Enhancement for TWS Earbuds
Sep 27, 2024



This paper introduces a speech enhancement solution tailored for true wireless stereo (TWS) earbuds on-device usage. The solution was specifically designed to support conversations in noisy environments, with active noise cancellation (ANC) activated. The primary challenges for speech enhancement models in this context arise from computational complexity that limits on-device usage and latency that must be less than 3 ms to preserve a live conversation. To address these issues, we evaluated several crucial design elements, including the network architecture and domain, design of loss functions, pruning method, and hardware-specific optimization. Consequently, we demonstrated substantial improvements in speech enhancement quality compared with that in baseline models, while simultaneously reducing the computational complexity and algorithmic latency.
Avocodo: Generative Adversarial Network for Artifact-free Vocoder
Jun 28, 2022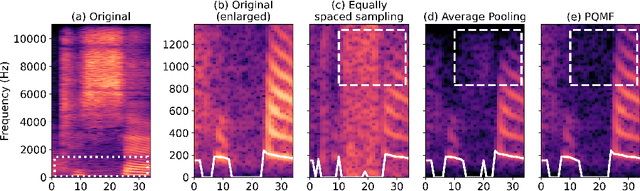
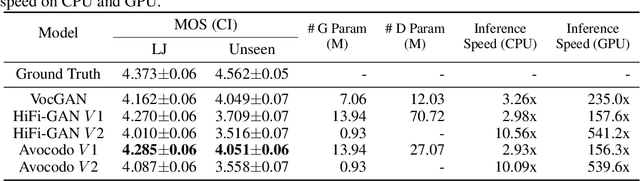
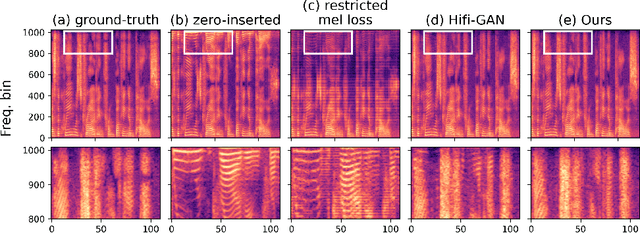
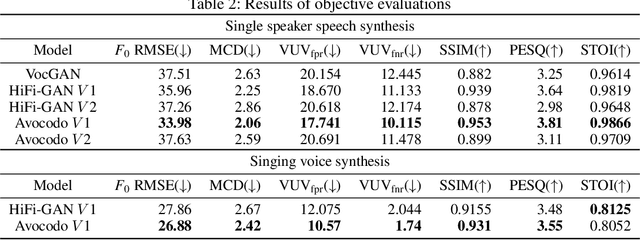
Neural vocoders based on the generative adversarial neural network (GAN) have been widely used due to their fast inference speed and lightweight networks while generating high-quality speech waveforms. Since the perceptually important speech components are primarily concentrated in the low-frequency band, most of the GAN-based neural vocoders perform multi-scale analysis that evaluates downsampled speech waveforms. This multi-scale analysis helps the generator improve speech intelligibility. However, in preliminary experiments, we observed that the multi-scale analysis which focuses on the low-frequency band causes unintended artifacts, e.g., aliasing and imaging artifacts, and these artifacts degrade the synthesized speech waveform quality. Therefore, in this paper, we investigate the relationship between these artifacts and GAN-based neural vocoders and propose a GAN-based neural vocoder, called Avocodo, that allows the synthesis of high-fidelity speech with reduced artifacts. We introduce two kinds of discriminators to evaluate waveforms in various perspectives: a collaborative multi-band discriminator and a sub-band discriminator. We also utilize a pseudo quadrature mirror filter bank to obtain downsampled multi-band waveforms while avoiding aliasing. The experimental results show that Avocodo outperforms conventional GAN-based neural vocoders in both speech and singing voice synthesis tasks and can synthesize artifact-free speech. Especially, Avocodo is even capable to reproduce high-quality waveforms of unseen speakers.
Enhancement of Pitch Controllability using Timbre-Preserving Pitch Augmentation in FastPitch
Apr 12, 2022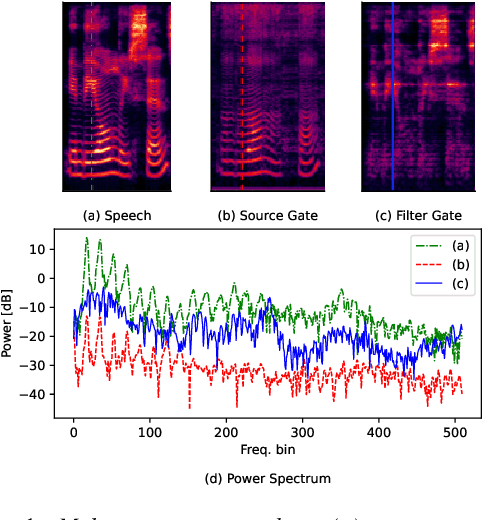
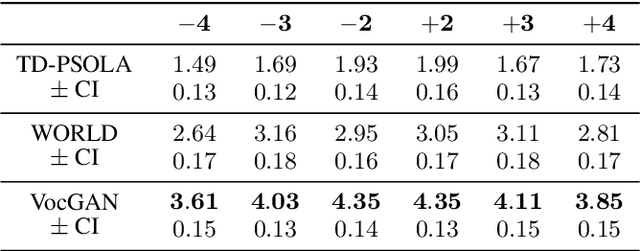
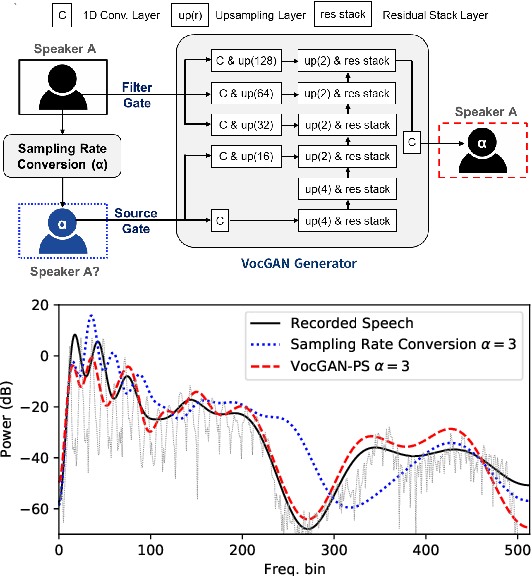
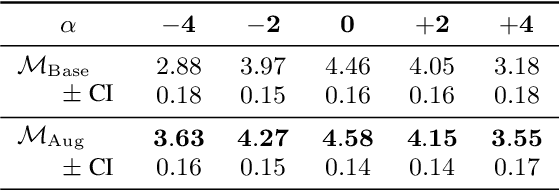
The recently developed pitch-controllable text-to-speech (TTS) model, i.e. FastPitch, was conditioned for the pitch contours. However, the quality of the synthesized speech degraded considerably for pitch values that deviated significantly from the average pitch; i.e. the ability to control pitch was limited. To address this issue, we propose two algorithms to improve the robustness of FastPitch. First, we propose a novel timbre-preserving pitch-shifting algorithm for natural pitch augmentation. Pitch-shifted speech samples sound more natural when using the proposed algorithm because the speaker's vocal timbre is maintained. Moreover, we propose a training algorithm that defines FastPitch using pitch-augmented speech datasets with different pitch ranges for the same sentence. The experimental results demonstrate that the proposed algorithms improve the pitch controllability of FastPitch.
N-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement
Jun 29, 2021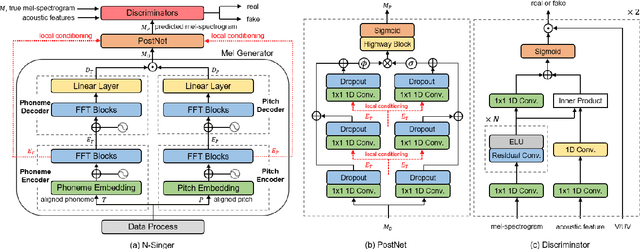
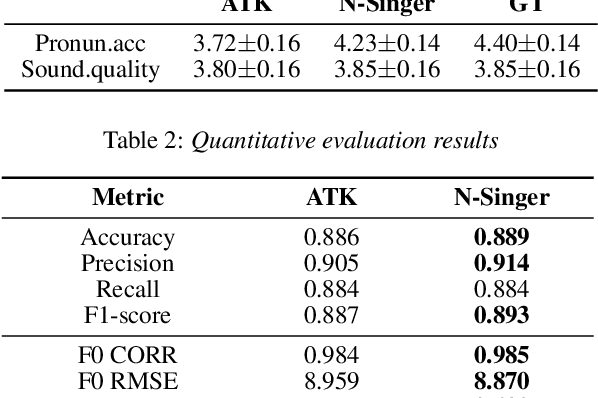
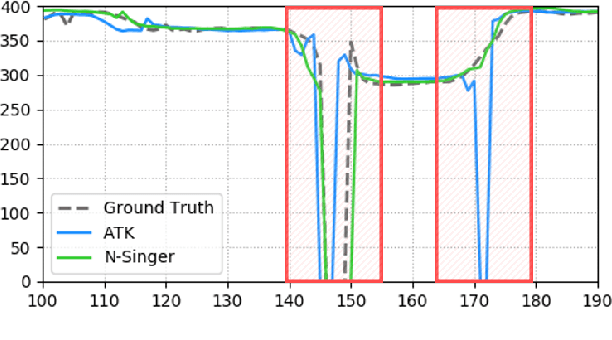
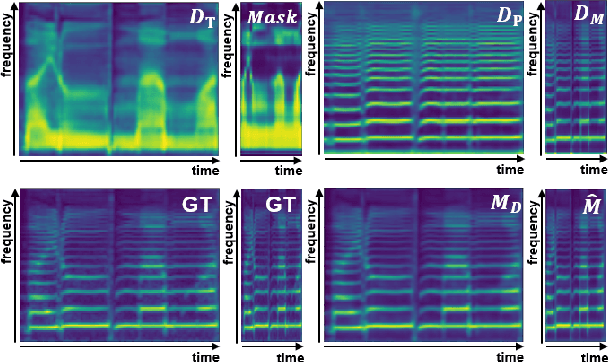
Recently, end-to-end Korean singing voice systems have been designed to generate realistic singing voices. However, these systems still suffer from a lack of robustness in terms of pronunciation accuracy. In this paper, we propose N-Singer, a non-autoregressive Korean singing voice system, to synthesize accurate and pronounced Korean singing voices in parallel. N-Singer consists of a Transformer-based mel-generator, a convolutional network-based postnet, and voicing-aware discriminators. It can contribute in the following ways. First, for accurate pronunciation, N-Singer separately models linguistic and pitch information without other acoustic features. Second, to achieve improved mel-spectrograms, N-Singer uses a combination of Transformer-based modules and convolutional network-based modules. Third, in adversarial training, voicing-aware conditional discriminators are used to capture the harmonic features of voiced segments and noise components of unvoiced segments. The experimental results prove that N-Singer can synthesize a natural singing voice in parallel with a more accurate pronunciation than the baseline model.
FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
Jun 29, 2021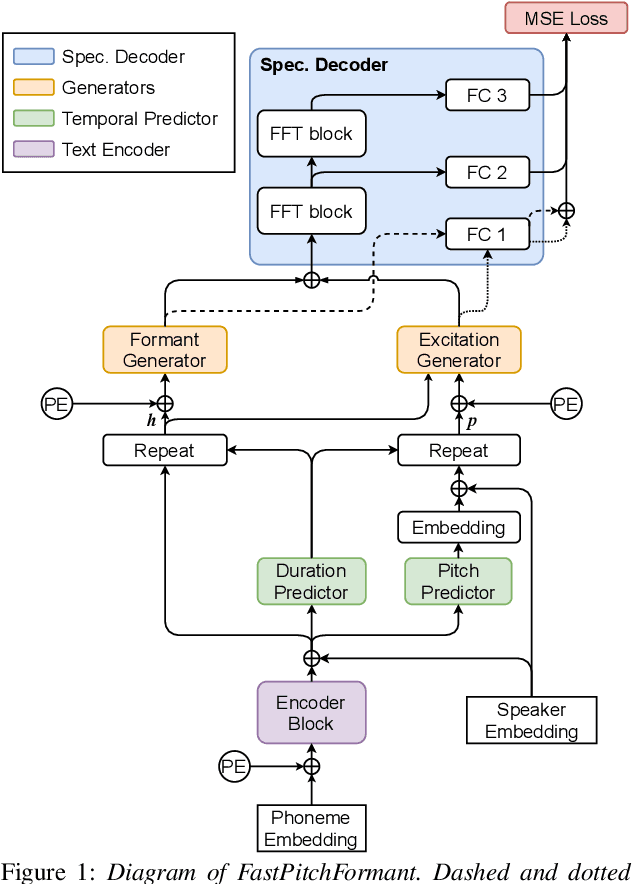
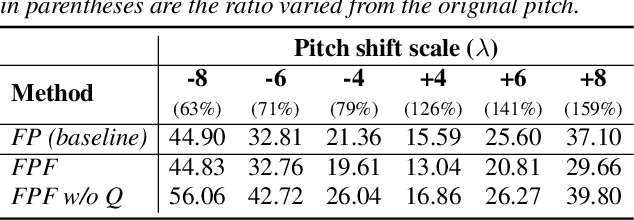
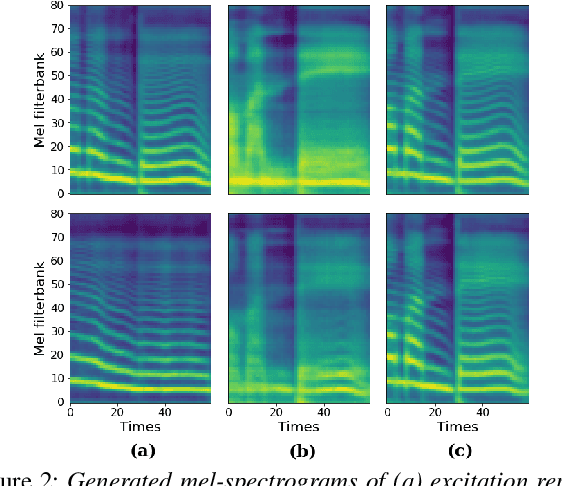
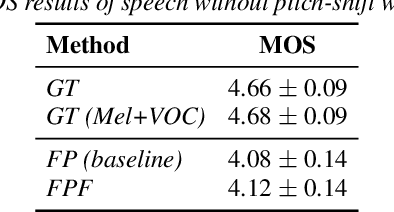
Methods for modeling and controlling prosody with acoustic features have been proposed for neural text-to-speech (TTS) models. Prosodic speech can be generated by conditioning acoustic features. However, synthesized speech with a large pitch-shift scale suffers from audio quality degradation, and speaker characteristics deformation. To address this problem, we propose a feed-forward Transformer based TTS model that is designed based on the source-filter theory. This model, called FastPitchFormant, has a unique structure that handles text and acoustic features in parallel. With modeling each feature separately, the tendency that the model learns the relationship between two features can be mitigated.
A Neural Text-to-Speech Model Utilizing Broadcast Data Mixed with Background Music
Mar 04, 2021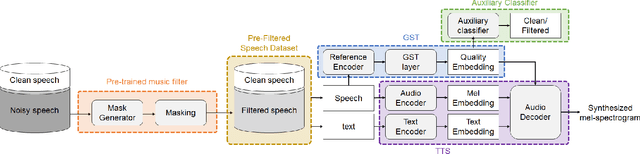
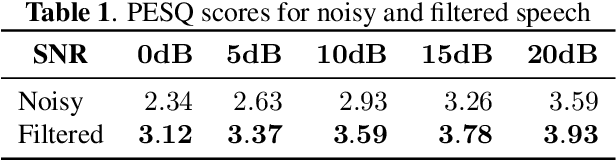
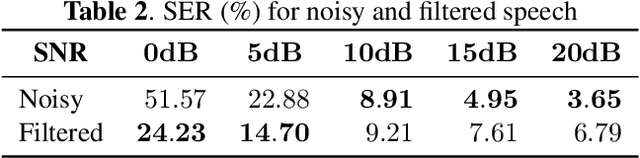
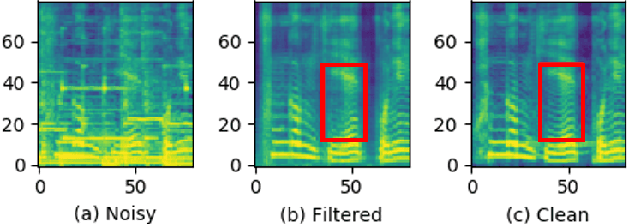
Recently, it has become easier to obtain speech data from various media such as the internet or YouTube, but directly utilizing them to train a neural text-to-speech (TTS) model is difficult. The proportion of clean speech is insufficient and the remainder includes background music. Even with the global style token (GST). Therefore, we propose the following method to successfully train an end-to-end TTS model with limited broadcast data. First, the background music is removed from the speech by introducing a music filter. Second, the GST-TTS model with an auxiliary quality classifier is trained with the filtered speech and a small amount of clean speech. In particular, the quality classifier makes the embedding vector of the GST layer focus on representing the speech quality (filtered or clean) of the input speech. The experimental results verified that the proposed method synthesized much more high-quality speech than conventional methods.