 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Teaching with Shared Classifier for Knowledge Distillation
Jun 14, 2024



Knowledge distillation (KD) is a technique used to transfer knowledge from an overparameterized teacher network to a less-parameterized student network, thereby minimizing the incurred performance loss. KD methods can be categorized into offline and online approaches. Offline KD leverages a powerful pretrained teacher network, while online KD allows the teacher network to be adjusted dynamically to enhance the learning effectiveness of the student network. Recently, it has been discovered that sharing the classifier of the teacher network can significantly boost the performance of the student network with only a minimal increase in the number of network parameters. Building on these insights, we propose adaptive teaching with a shared classifier (ATSC). In ATSC, the pretrained teacher network self-adjusts to better align with the learning needs of the student network based on its capabilities, and the student network benefits from the shared classifier, enhancing its performance. Additionally, we extend ATSC to environments with multiple teachers. We conduct extensive experiments, demonstrating the effectiveness of the proposed KD method. Our approach achieves state-of-the-art results on the CIFAR-100 and ImageNet datasets in both single-teacher and multiteacher scenarios, with only a modest increase in the number of required model parameters. The source code is publicly available at https://github.com/random2314235/ATSC.
N-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement
Jun 29, 2021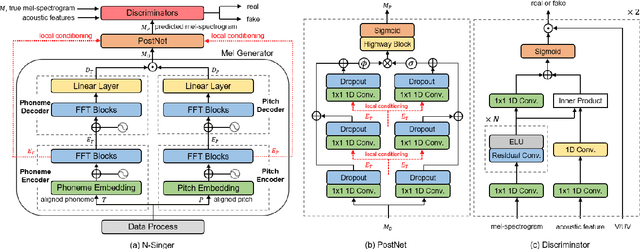
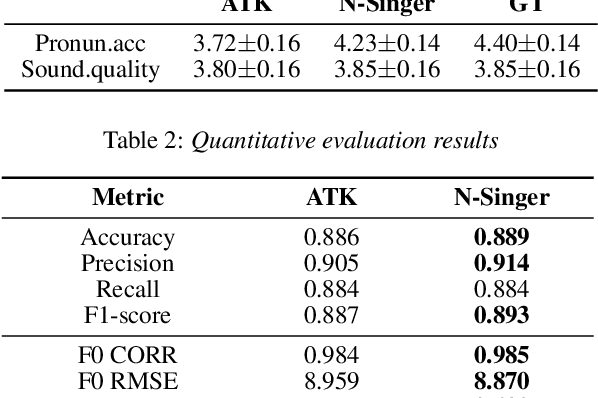
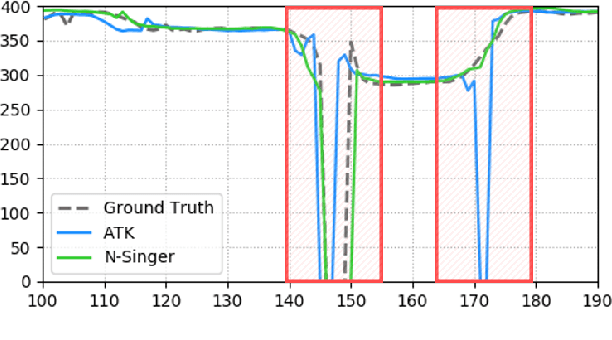
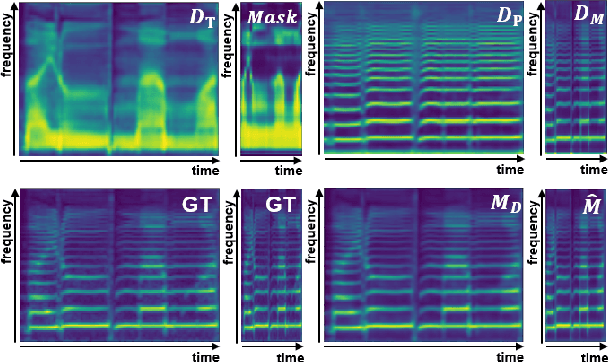
Recently, end-to-end Korean singing voice systems have been designed to generate realistic singing voices. However, these systems still suffer from a lack of robustness in terms of pronunciation accuracy. In this paper, we propose N-Singer, a non-autoregressive Korean singing voice system, to synthesize accurate and pronounced Korean singing voices in parallel. N-Singer consists of a Transformer-based mel-generator, a convolutional network-based postnet, and voicing-aware discriminators. It can contribute in the following ways. First, for accurate pronunciation, N-Singer separately models linguistic and pitch information without other acoustic features. Second, to achieve improved mel-spectrograms, N-Singer uses a combination of Transformer-based modules and convolutional network-based modules. Third, in adversarial training, voicing-aware conditional discriminators are used to capture the harmonic features of voiced segments and noise components of unvoiced segments. The experimental results prove that N-Singer can synthesize a natural singing voice in parallel with a more accurate pronunciation than the baseline model.
FastPitchFormant: Source-filter based Decomposed Modeling for Speech Synthesis
Jun 29, 2021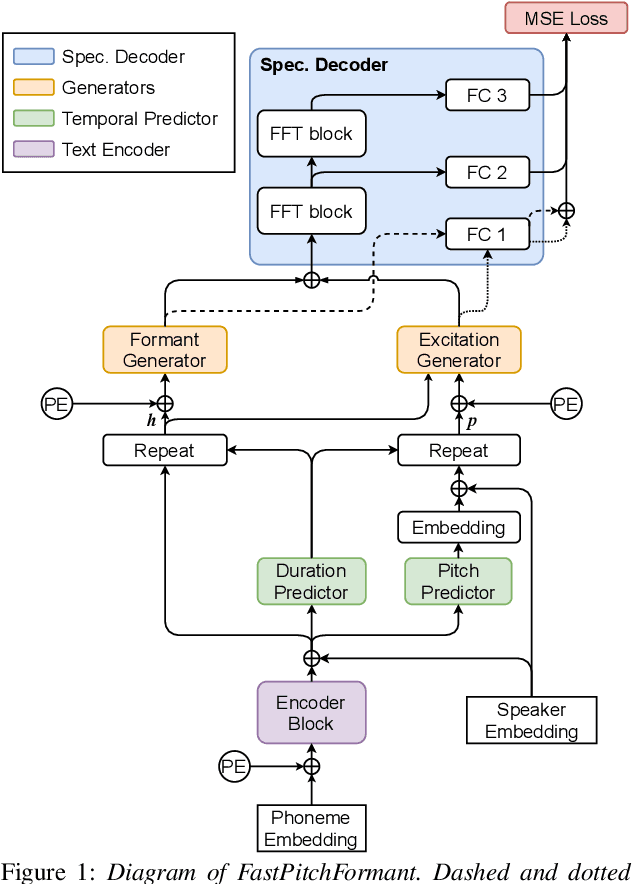
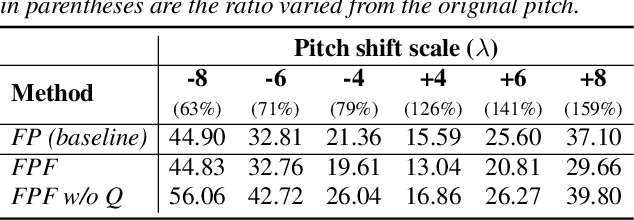
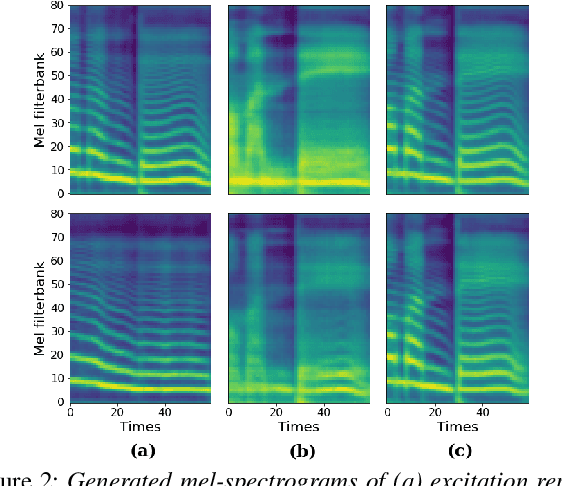
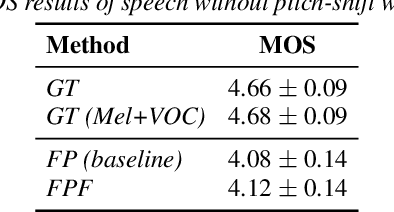
Methods for modeling and controlling prosody with acoustic features have been proposed for neural text-to-speech (TTS) models. Prosodic speech can be generated by conditioning acoustic features. However, synthesized speech with a large pitch-shift scale suffers from audio quality degradation, and speaker characteristics deformation. To address this problem, we propose a feed-forward Transformer based TTS model that is designed based on the source-filter theory. This model, called FastPitchFormant, has a unique structure that handles text and acoustic features in parallel. With modeling each feature separately, the tendency that the model learns the relationship between two features can be mitigated.
A Neural Text-to-Speech Model Utilizing Broadcast Data Mixed with Background Music
Mar 04, 2021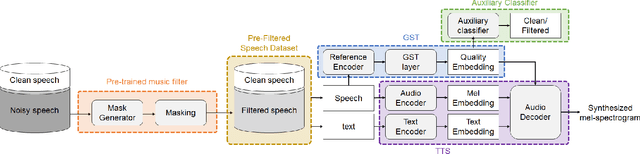
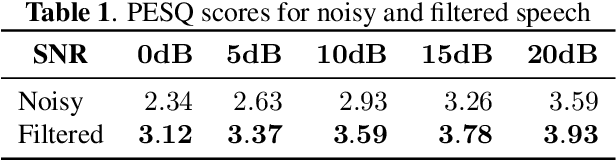
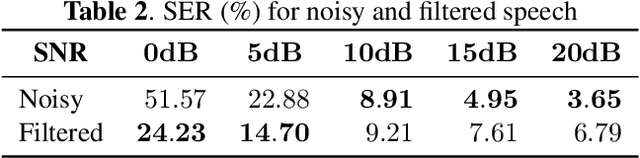
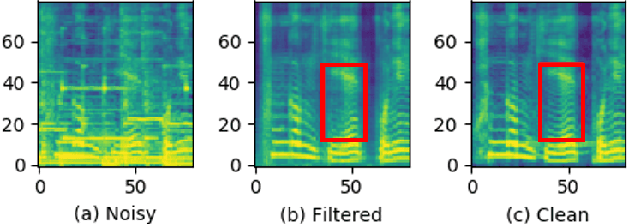
Recently, it has become easier to obtain speech data from various media such as the internet or YouTube, but directly utilizing them to train a neural text-to-speech (TTS) model is difficult. The proportion of clean speech is insufficient and the remainder includes background music. Even with the global style token (GST). Therefore, we propose the following method to successfully train an end-to-end TTS model with limited broadcast data. First, the background music is removed from the speech by introducing a music filter. Second, the GST-TTS model with an auxiliary quality classifier is trained with the filtered speech and a small amount of clean speech. In particular, the quality classifier makes the embedding vector of the GST layer focus on representing the speech quality (filtered or clean) of the input speech. The experimental results verified that the proposed method synthesized much more high-quality speech than conventional methods.