 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of Instrument-Tissue Interactions in Endoscopic Videos via Action Triplets
Jul 10, 2020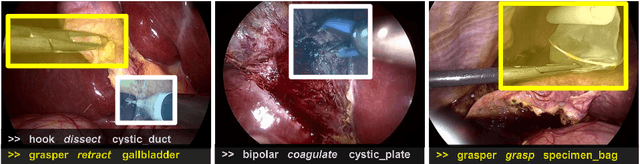
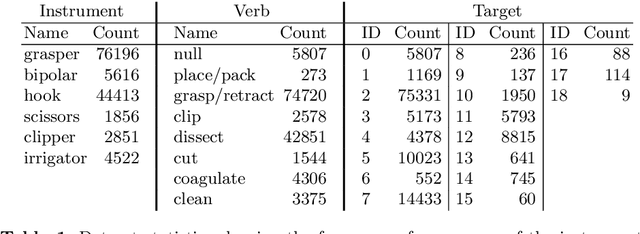
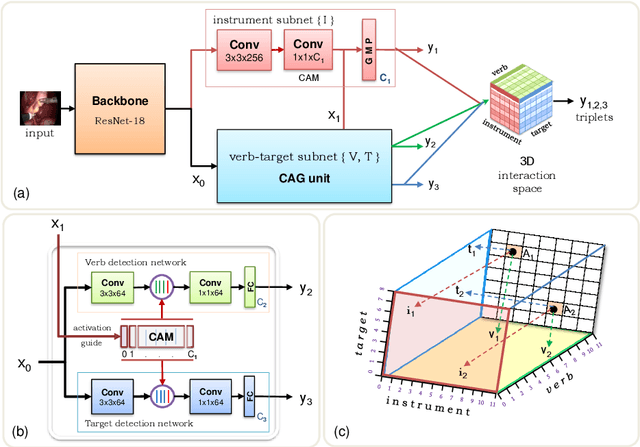
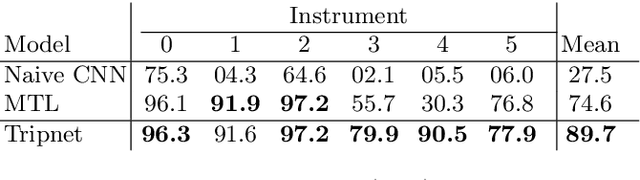
Recognition of surgical activity is an essential component to develop context-aware decision support for the operating room. In this work, we tackle the recognition of fine-grained activities, modeled as action triplets <instrument, verb, target> representing the tool activity. To this end, we introduce a new laparoscopic dataset, CholecT40, consisting of 40 videos from the public dataset Cholec80 in which all frames have been annotated using 128 triplet classes. Furthermore, we present an approach to recognize these triplets directly from the video data. It relies on a module called Class Activation Guide (CAG), which uses the instrument activation maps to guide the verb and target recognition. To model the recognition of multiple triplets in the same frame, we also propose a trainable 3D Interaction Space, which captures the associations between the triplet components. Finally, we demonstrate the significance of these contributions via several ablation studies and comparisons to baselines on CholecT40.
Weakly Supervised Convolutional LSTM Approach for Tool Tracking in Laparoscopic Videos
Dec 04, 2018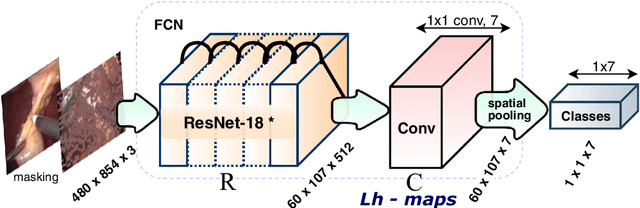
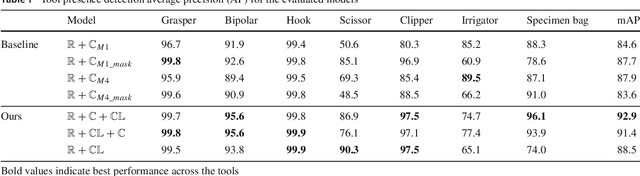
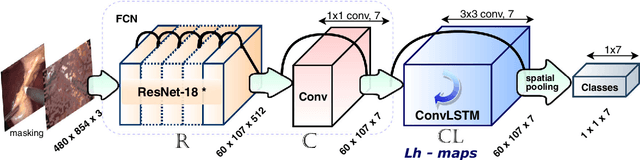
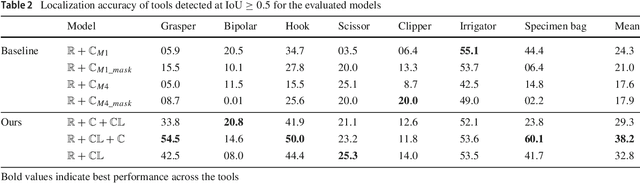
Purpose: Real-time surgical tool tracking is a core component of the future intelligent operating room (OR), because it is highly instrumental to analyze and understand the surgical activities. Current methods for surgical tool tracking in videos need to be trained on data in which the spatial position of the tools is manually annotated. Generating such training data is difficult and time-consuming. Instead, we propose to use solely binary presence annotations to train a tool tracker for laparoscopic videos. Methods: The proposed approach is composed of a CNN + Convolutional LSTM (ConvLSTM) neural network trained end-to-end, but weakly supervised on tool binary presence labels only. We use the ConvLSTM to model the temporal dependencies in the motion of the surgical tools and leverage its spatio-temporal ability to smooth the class peak activations in the localization heat maps (Lh-maps). Results: We build a baseline tracker on top of the CNN model and demonstrate that our approach based on the ConvLSTM outperforms the baseline in tool presence detection, spatial localization, and motion tracking by over 5.0%, 13.9%, and 12.6%, respectively. Conclusions: In this paper, we demonstrate that binary presence labels are sufficient for training a deep learning tracking model using our proposed method. We also show that the ConvLSTM can leverage the spatio-temporal coherence of consecutive image frames across a surgical video to improve tool presence detection, spatial localization, and motion tracking.
Learning from a tiny dataset of manual annotations: a teacher/student approach for surgical phase recognition
Nov 30, 2018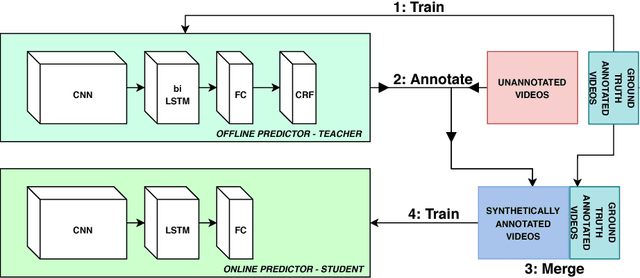
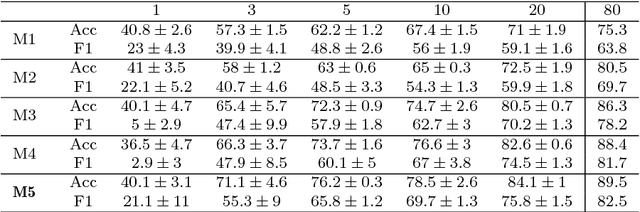
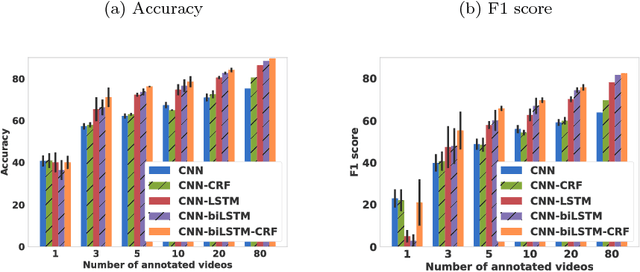
Vision algorithms capable of interpreting scenes from a real-time video stream are necessary for computer-assisted surgery systems to achieve context-aware behavior. In laparoscopic procedures one particular algorithm needed for such systems is the identification of surgical phases, for which the current state of the art is a model based on a CNN-LSTM. A number of previous works using models of this kind have trained them in a fully supervised manner, requiring a fully annotated dataset. Instead, our work confronts the problem of learning surgical phase recognition in scenarios presenting scarce amounts of annotated data (under 25% of all available video recordings). We propose a teacher/student type of approach, where a strong predictor called the teacher, trained beforehand on a small dataset of ground truth-annotated videos, generates synthetic annotations for a larger dataset, which another model - the student - learns from. In our case, the teacher features a novel CNN-biLSTM-CRF architecture, designed for offline inference only. The student, on the other hand, is a CNN-LSTM capable of making real-time predictions. Results for various amounts of manually annotated videos demonstrate the superiority of the new CNN-biLSTM-CRF predictor as well as improved performance from the CNN-LSTM trained using synthetic labels generated for unannotated videos. For both offline and online surgical phase recognition with very few annotated recordings available, this new teacher/student strategy provides a valuable performance improvement by efficiently leveraging the unannotated data.
Future-State Predicting LSTM for Early Surgery Type Recognition
Nov 28, 2018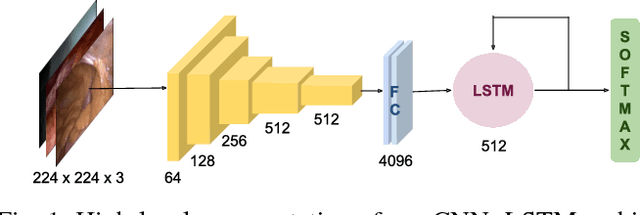
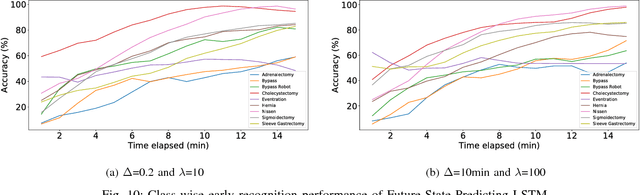
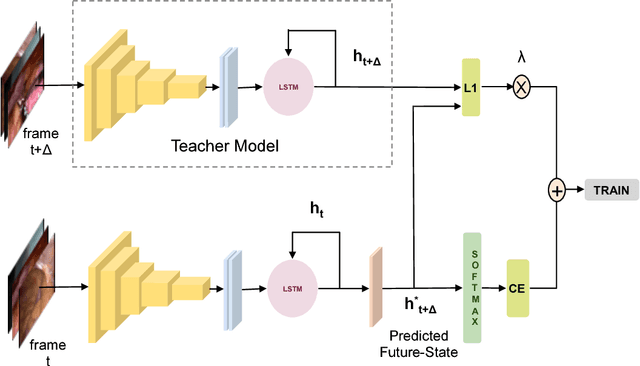
This work presents a novel approach for the early recognition of the type of a laparoscopic surgery from its video. Early recognition algorithms can be beneficial to the development of 'smart' OR systems that can provide automatic context-aware assistance, and also enable quick database indexing. The task is however ridden with challenges specific to videos belonging to the domain of laparoscopy, such as high visual similarity across surgeries and large variations in video durations. To capture the spatio-temporal dependencies in these videos, we choose as our model a combination of a Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) network. We then propose two complementary approaches for improving early recognition performance. The first approach is a CNN fine-tuning method that encourages surgeries to be distinguished based on the initial frames of laparoscopic videos. The second approach, referred to as 'Future-State Predicting LSTM', trains an LSTM to predict information related to future frames, which helps in distinguishing between the different types of surgeries. We evaluate our approaches on a large dataset of 425 laparoscopic videos containing 9 types of surgeries (Laparo425), and achieve on average an accuracy of 75% having observed only the first 10 minutes of a surgery. These results are quite promising from a practical standpoint and also encouraging for other types of image-guided surgeries.
Weakly-Supervised Learning for Tool Localization in Laparoscopic Videos
Jul 18, 2018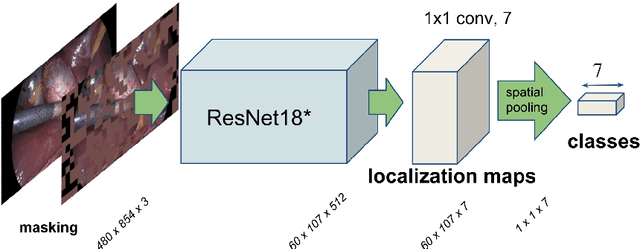

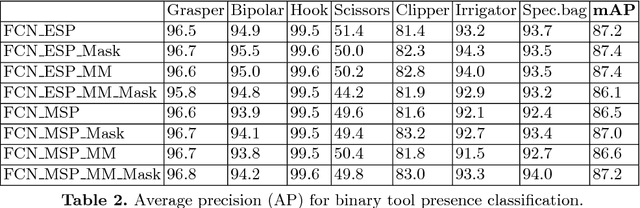
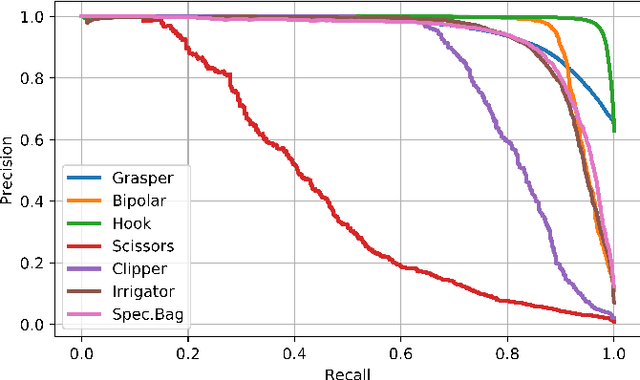
Surgical tool localization is an essential task for the automatic analysis of endoscopic videos. In the literature, existing methods for tool localization, tracking and segmentation require training data that is fully annotated, thereby limiting the size of the datasets that can be used and the generalization of the approaches. In this work, we propose to circumvent the lack of annotated data with weak supervision. We propose a deep architecture, trained solely on image level annotations, that can be used for both tool presence detection and localization in surgical videos. Our architecture relies on a fully convolutional neural network, trained end-to-end, enabling us to localize surgical tools without explicit spatial annotations. We demonstrate the benefits of our approach on a large public dataset, Cholec80, which is fully annotated with binary tool presence information and of which 5 videos have been fully annotated with bounding boxes and tool centers for the evaluation.
Less is More: Surgical Phase Recognition with Less Annotations through Self-Supervised Pre-training of CNN-LSTM Networks
May 22, 2018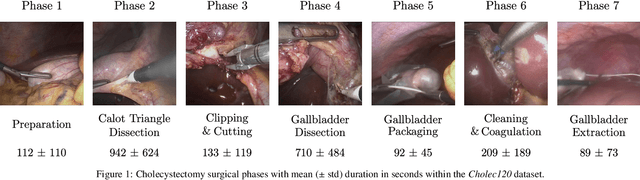


Real-time algorithms for automatically recognizing surgical phases are needed to develop systems that can provide assistance to surgeons, enable better management of operating room (OR) resources and consequently improve safety within the OR. State-of-the-art surgical phase recognition algorithms using laparoscopic videos are based on fully supervised training. This limits their potential for widespread application, since creation of manual annotations is an expensive process considering the numerous types of existing surgeries and the vast amount of laparoscopic videos available. In this work, we propose a new self-supervised pre-training approach based on the prediction of remaining surgery duration (RSD) from laparoscopic videos. The RSD prediction task is used to pre-train a convolutional neural network (CNN) and long short-term memory (LSTM) network in an end-to-end manner. Our proposed approach utilizes all available data and reduces the reliance on annotated data, thereby facilitating the scaling up of surgical phase recognition algorithms to different kinds of surgeries. Additionally, we present EndoN2N, an end-to-end trained CNN-LSTM model for surgical phase recognition and evaluate the performance of our approach on a dataset of 120 Cholecystectomy laparoscopic videos (Cholec120). This work also presents the first systematic study of self-supervised pre-training approaches to understand the amount of annotations required for surgical phase recognition. Interestingly, the proposed RSD pre-training approach leads to performance improvement even when all the training data is manually annotated and outperforms the single pre-training approach for surgical phase recognition presently published in the literature. It is also observed that end-to-end training of CNN-LSTM networks boosts surgical phase recognition performance.
RSDNet: Learning to Predict Remaining Surgery Duration from Laparoscopic Videos Without Manual Annotations
Feb 09, 2018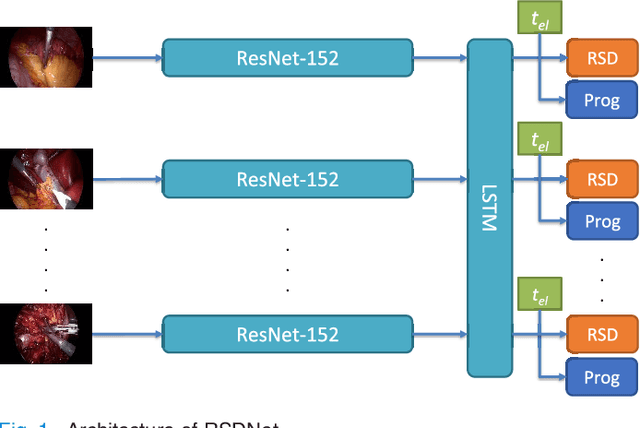
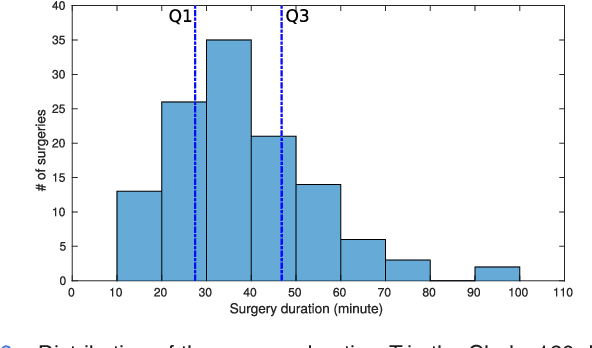
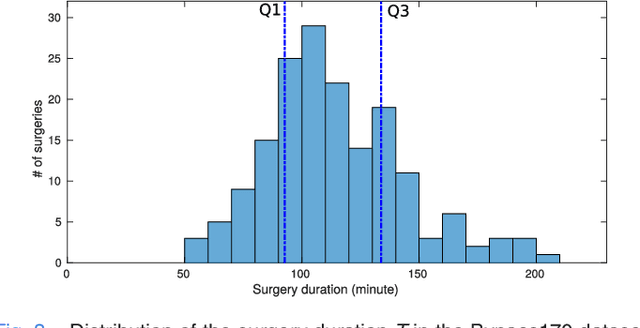
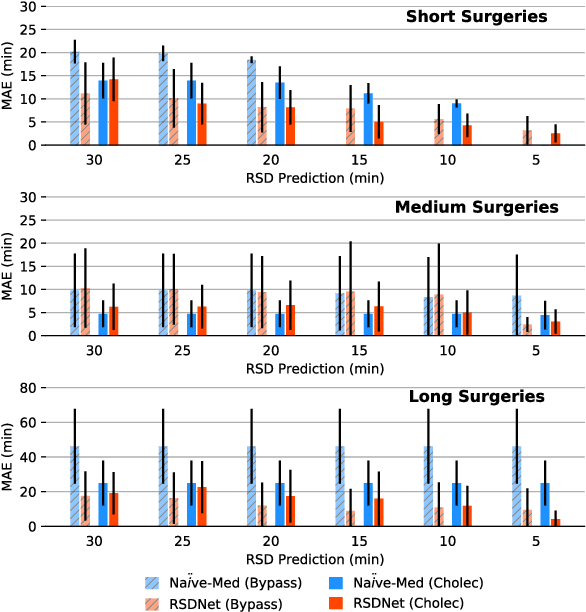
Objective: Accurate surgery duration estimation is necessary for optimal OR planning, which plays an important role for patient comfort and safety as well as resource optimization. It is however challenging to preoperatively predict surgery duration since it varies significantly depending on the patient condition, surgeon skills, and intraoperative situation. We present an approach for intraoperative estimation of remaining surgery duration, which is well suited for deployment in the OR. Methods: We propose a deep learning pipeline, named RSDNet, which automatically estimates the remaining surgery duration intraoperatively by using only visual information from laparoscopic videos. An interesting feature of RSDNet is that it does not depend on any manual annotation during training. Results: The experimental results show that the proposed network significantly outperforms the method that is frequently used in surgical facilities for estimating surgery duration. Further, the generalizability of the approach is demonstrated by testing the pipeline on two large datasets containing different types of surgeries, 120 cholecystectomy and 170 gastric bypass videos. Conclusion: Creation of manual annotations requires expert knowledge and is a time-consuming process, especially considering the numerous types of surgeries performed in a hospital and the large number of laparoscopic videos available. Since the proposed pipeline is not reliant on manual annotation, it is easily scalable to many types of surgeries. Significance: An improved OR management system could be developed with RSDNet as a result of its superior performance and ability to be efficiently scaled up to many kinds of surgeries.
Single- and Multi-Task Architectures for Surgical Workflow Challenge at M2CAI 2016
Oct 28, 2016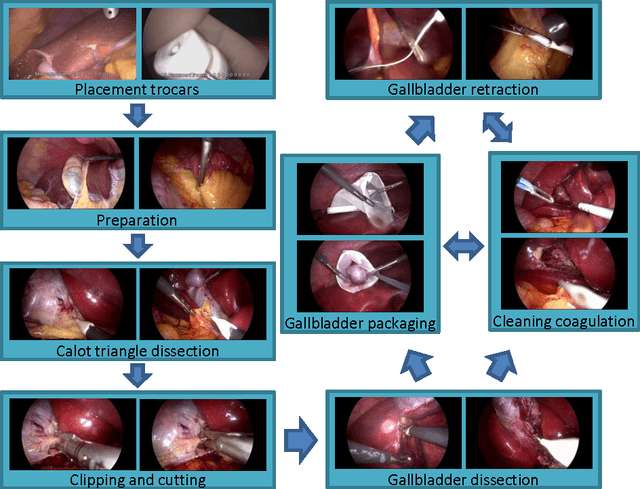

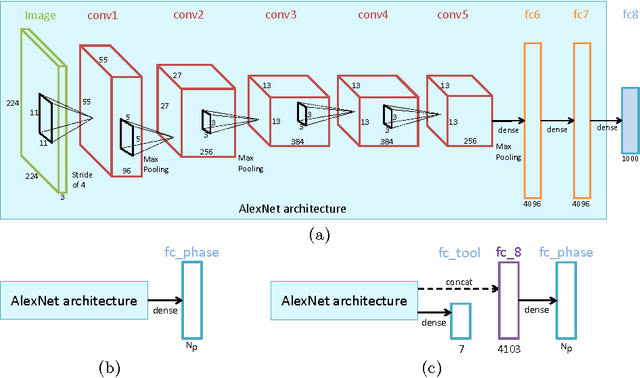
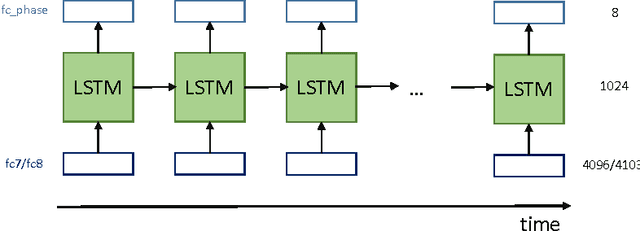
The surgical workflow challenge at M2CAI 2016 consists of identifying 8 surgical phases in cholecystectomy procedures. Here, we propose to use deep architectures that are based on our previous work where we presented several architectures to perform multiple recognition tasks on laparoscopic videos. In this technical report, we present the phase recognition results using two architectures: (1) a single-task architecture designed to perform solely the surgical phase recognition task and (2) a multi-task architecture designed to perform jointly phase recognition and tool presence detection. On top of these architectures we propose to use two different approaches to enforce the temporal constraints of the surgical workflow: (1) HMM-based and (2) LSTM-based pipelines. The results show that the LSTM-based approach is able to outperform the HMM-based approach and also to properly enforce the temporal constraints into the recognition process.
Single- and Multi-Task Architectures for Tool Presence Detection Challenge at M2CAI 2016
Oct 27, 2016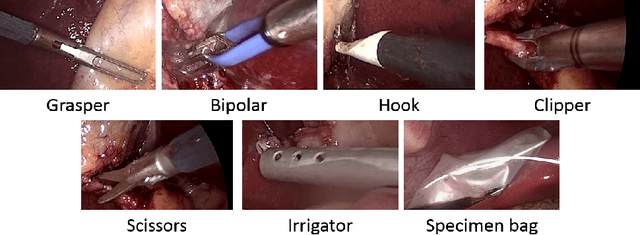
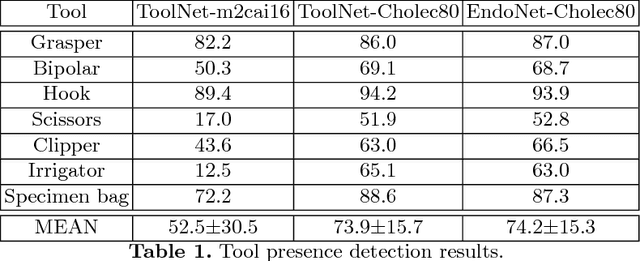
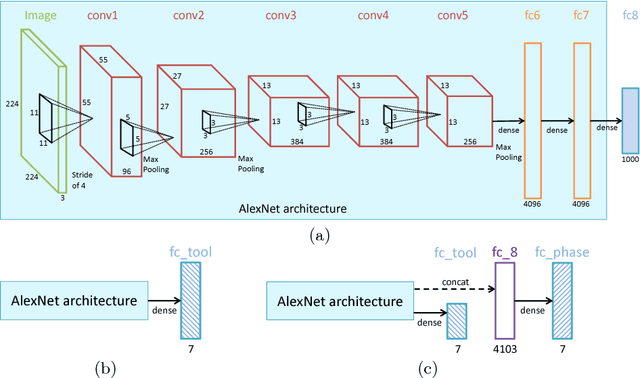
The tool presence detection challenge at M2CAI 2016 consists of identifying the presence/absence of seven surgical tools in the images of cholecystectomy videos. Here, we propose to use deep architectures that are based on our previous work where we presented several architectures to perform multiple recognition tasks on laparoscopic videos. In this technical report, we present the tool presence detection results using two architectures: (1) a single-task architecture designed to perform solely the tool presence detection task and (2) a multi-task architecture designed to perform jointly phase recognition and tool presence detection. The results show that the multi-task network only slightly improves the tool presence detection results. In constrast, a significant improvement is obtained when there are more data available to train the networks. This significant improvement can be regarded as a call for action for other institutions to start working toward publishing more datasets into the community, so that better models could be generated to perform the task.
Automatic View-Point Selection for Inter-Operative Endoscopic Surveillance
Oct 13, 2016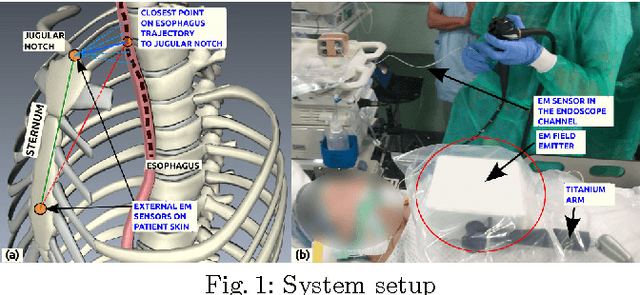

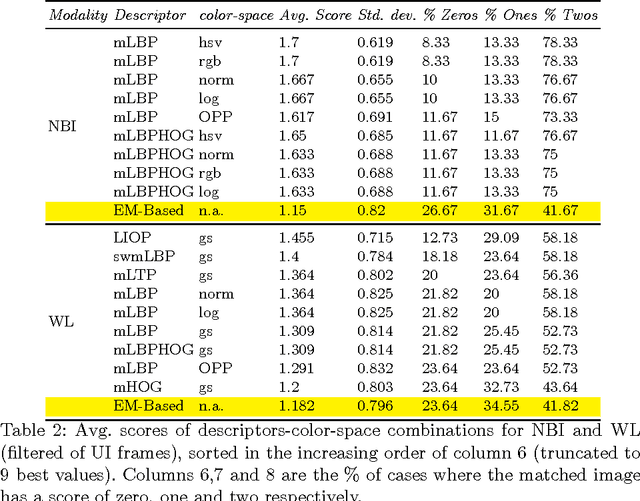
Esophageal adenocarcinoma arises from Barrett's esophagus, which is the most serious complication of gastroesophageal reflux disease. Strategies for screening involve periodic surveillance and tissue biopsies. A major challenge in such regular examinations is to record and track the disease evolution and re-localization of biopsied sites to provide targeted treatments. In this paper, we extend our original inter-operative relocalization framework to provide a constrained image based search for obtaining the best view-point match to the live view. Within this context we investigate the effect of: the choice of feature descriptors and color-space; filtering of uninformative frames and endoscopic modality, for view-point localization. Our experiments indicate an improvement in the best view-point retrieval rate to [92%,87%] from [73%,76%] (in our previous approach) for NBI and WL.