 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgram Synthesis with Large Language Models
Aug 16, 2021



This paper explores the limits of the current generation of large language models for program synthesis in general purpose programming languages. We evaluate a collection of such models (with between 244M and 137B parameters) on two new benchmarks, MBPP and MathQA-Python, in both the few-shot and fine-tuning regimes. Our benchmarks are designed to measure the ability of these models to synthesize short Python programs from natural language descriptions. The Mostly Basic Programming Problems (MBPP) dataset contains 974 programming tasks, designed to be solvable by entry-level programmers. The MathQA-Python dataset, a Python version of the MathQA benchmark, contains 23914 problems that evaluate the ability of the models to synthesize code from more complex text. On both datasets, we find that synthesis performance scales log-linearly with model size. Our largest models, even without finetuning on a code dataset, can synthesize solutions to 59.6 percent of the problems from MBPP using few-shot learning with a well-designed prompt. Fine-tuning on a held-out portion of the dataset improves performance by about 10 percentage points across most model sizes. On the MathQA-Python dataset, the largest fine-tuned model achieves 83.8 percent accuracy. Going further, we study the model's ability to engage in dialog about code, incorporating human feedback to improve its solutions. We find that natural language feedback from a human halves the error rate compared to the model's initial prediction. Additionally, we conduct an error analysis to shed light on where these models fall short and what types of programs are most difficult to generate. Finally, we explore the semantic grounding of these models by fine-tuning them to predict the results of program execution. We find that even our best models are generally unable to predict the output of a program given a specific input.
Beyond In-Place Corruption: Insertion and Deletion In Denoising Probabilistic Models
Jul 16, 2021
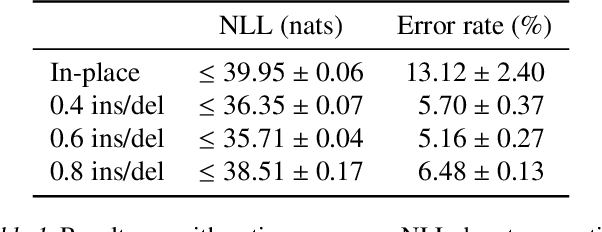
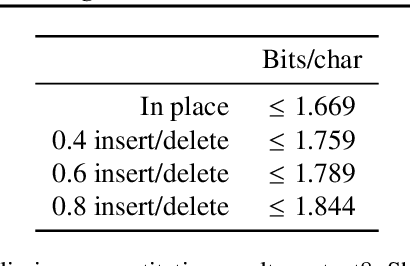
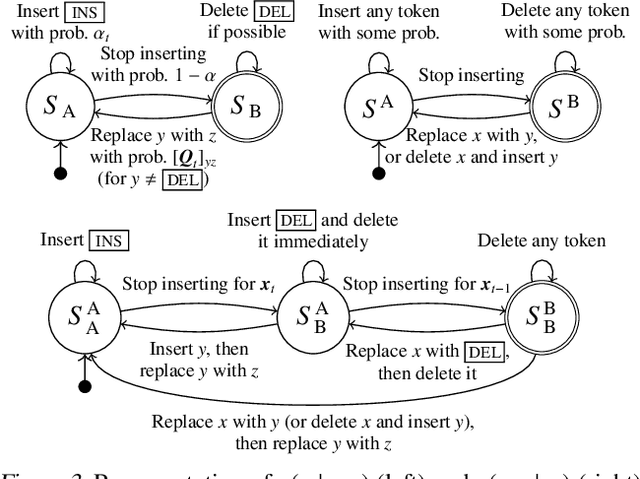
Denoising diffusion probabilistic models (DDPMs) have shown impressive results on sequence generation by iteratively corrupting each example and then learning to map corrupted versions back to the original. However, previous work has largely focused on in-place corruption, adding noise to each pixel or token individually while keeping their locations the same. In this work, we consider a broader class of corruption processes and denoising models over sequence data that can insert and delete elements, while still being efficient to train and sample from. We demonstrate that these models outperform standard in-place models on an arithmetic sequence task, and that when trained on the text8 dataset they can be used to fix spelling errors without any fine-tuning.
Structured Denoising Diffusion Models in Discrete State-Spaces
Jul 13, 2021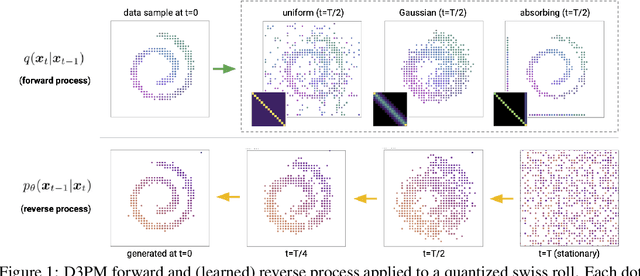
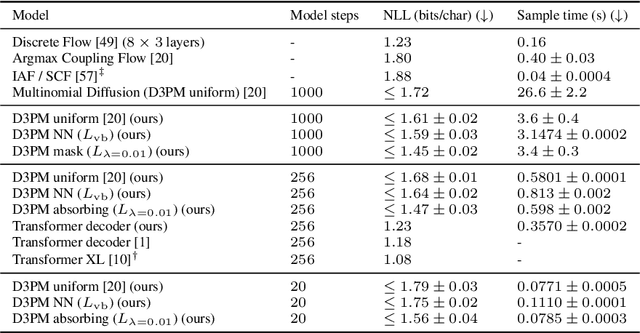

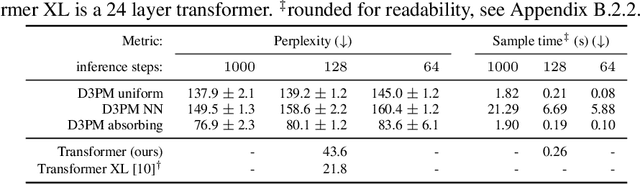
Denoising diffusion probabilistic models (DDPMs) (Ho et al. 2020) have shown impressive results on image and waveform generation in continuous state spaces. Here, we introduce Discrete Denoising Diffusion Probabilistic Models (D3PMs), diffusion-like generative models for discrete data that generalize the multinomial diffusion model of Hoogeboom et al. 2021, by going beyond corruption processes with uniform transition probabilities. This includes corruption with transition matrices that mimic Gaussian kernels in continuous space, matrices based on nearest neighbors in embedding space, and matrices that introduce absorbing states. The third allows us to draw a connection between diffusion models and autoregressive and mask-based generative models. We show that the choice of transition matrix is an important design decision that leads to improved results in image and text domains. We also introduce a new loss function that combines the variational lower bound with an auxiliary cross entropy loss. For text, this model class achieves strong results on character-level text generation while scaling to large vocabularies on LM1B. On the image dataset CIFAR-10, our models approach the sample quality and exceed the log-likelihood of the continuous-space DDPM model.
Titan: A Parallel Asynchronous Library for Multi-Agent and Soft-Body Robotics using NVIDIA CUDA
Nov 22, 2019
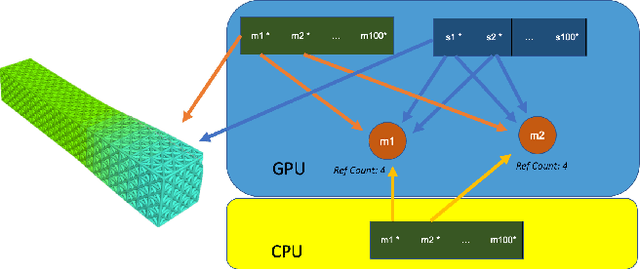
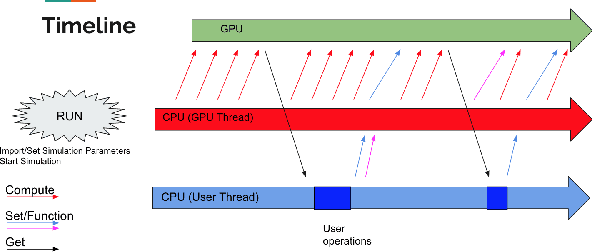
While most robotics simulation libraries are built for low-dimensional and intrinsically serial tasks, soft-body and multi-agent robotics have created a demand for simulation environments that can model many interacting bodies in parallel. Despite the increasing interest in these fields, no existing simulation library addresses the challenge of providing a unified, highly-parallelized, GPU-accelerated interface for simulating large robotic systems. Titan is a versatile CUDA-based C++ robotics simulation library that employs a novel asynchronous computing model for GPU-accelerated simulations of robotics primitives. The innovative GPU architecture design permits simultaneous optimization and control on the CPU while the GPU runs asynchronously, enabling rapid topology optimization and reinforcement learning iterations. Kinematics are solved with a massively parallel integration scheme that incorporates constraints and environmental forces. We report dramatically improved performance over CPU-based baselines, simulating as many as 300 million primitive updates per second, while allowing flexibility for a wide range of research applications. We present several applications of Titan to high-performance simulations of soft-body and multi-agent robots.