 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATWL: A Formal Language for Representing, Comparing, and Reusing Visual Analytics Workflows
May 25, 2026Visual analytics (VA) workflows are inherently complex, involving data transformation, feature engineering, visual representation, and human interpretation. They are typically described in unstructured prose, hindering systematic comparison, reuse of proven strategies, and training of novices. We present Artifact-Transform Workflow Language (ATWL), a domain-agnostic, declarative language that formally represents VA workflows by capturing their structure and underlying analytical intent. ATWL is built upon a modular ontology of eight artifact types (entities, features, arrangements, visualisations, patterns, models, knowledge, specifications) and transforms characterised by standardised intents (e.g., define-unit, characterise, contextualise, abstract). To show that formalisation effort need not impede adoption, we extract workflows from research papers through supervised interaction with LLM agents, reducing the human role to review and refinement. Using this process, we constructed a library of seventeen ATWL workflows from published VA papers. Cross-workflow analysis reveals structural regularities -- a recurrent meta-structure, recurring motifs, reusable building blocks, diverse iterative strategies, and cross-domain equivalences -- that remain invisible in prose. We further evaluate practical utility through a controlled experiment in which the same LLM addressed two analytical problems with the library supplied either as original papers or as ATWL representations. Both forms enabled useful recommendations, but the formal representation systematically added explicit iteration structure, typed data flow, fragment-level adaptation provenance, and compactness supporting scaling beyond what prose libraries can fit in an LLM's context. ATWL enables a transition from narrative descriptions to formally represented, comparable, and reusable analytical knowledge.
The Human-Data-Model Interaction Canvas for Visual Analytics
May 12, 2025Visual Analytics (VA) integrates humans, data, and models as key actors in insight generation and data-driven decision-making. This position paper values and reflects on 16 VA process models and frameworks and makes nine high-level observations that motivate a fresh perspective on VA. The contribution is the HDMI Canvas, a perspective to VA that complements the strengths of existing VA process models and frameworks. It systematically characterizes diverse roles of humans, data, and models, and how these actors benefit from and contribute to VA processes. The descriptive power of the HDMI Canvas eases the differentiation between a series of VA building blocks, rather than describing general VA principles only. The canvas includes modern human-centered methodologies, including human knowledge externalization and forms of feedback loops, while interpretable and explainable AI highlight model contributions beyond their conventional outputs. The HDMI Canvas has generative power, guiding the design of new VA processes and is optimized for external stakeholders, improving VA outreach, interdisciplinary collaboration, and user-centered design. The utility of the HDMI Canvas is demonstrated through two preliminary case studies.
Visualizing Graph Neural Networks with CorGIE: Corresponding a Graph to Its Embedding
Jun 24, 2021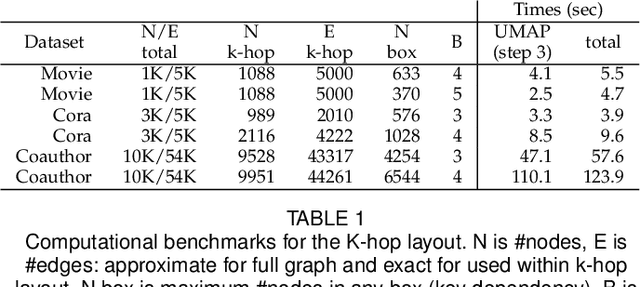

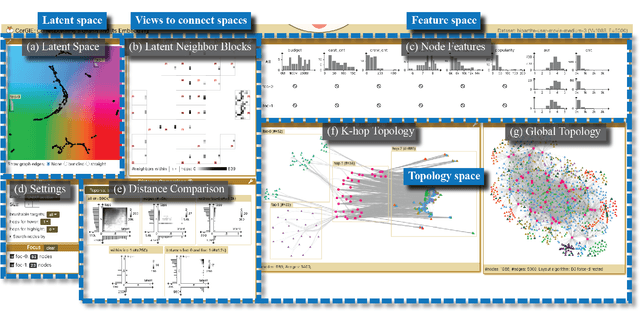

Graph neural networks (GNNs) are a class of powerful machine learning tools that model node relations for making predictions of nodes or links. GNN developers rely on quantitative metrics of the predictions to evaluate a GNN, but similar to many other neural networks, it is difficult for them to understand if the GNN truly learns characteristics of a graph as expected. We propose an approach to corresponding an input graph to its node embedding (aka latent space), a common component of GNNs that is later used for prediction. We abstract the data and tasks, and develop an interactive multi-view interface called CorGIE to instantiate the abstraction. As the key function in CorGIE, we propose the K-hop graph layout to show topological neighbors in hops and their clustering structure. To evaluate the functionality and usability of CorGIE, we present how to use CorGIE in two usage scenarios, and conduct a case study with two GNN experts.
ConfusionFlow: A model-agnostic visualization for temporal analysis of classifier confusion
Oct 02, 2019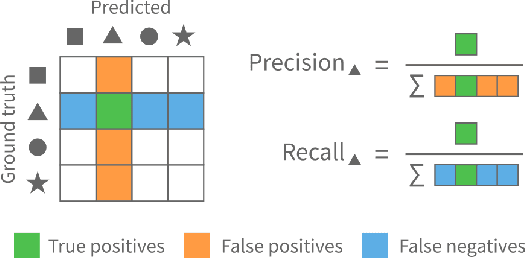
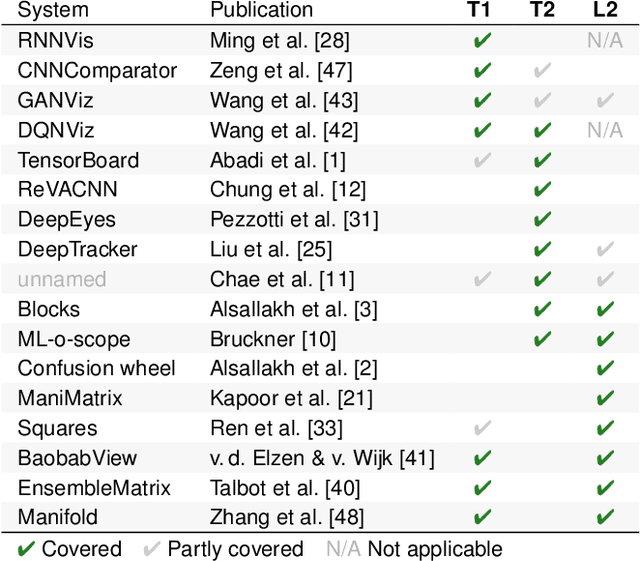
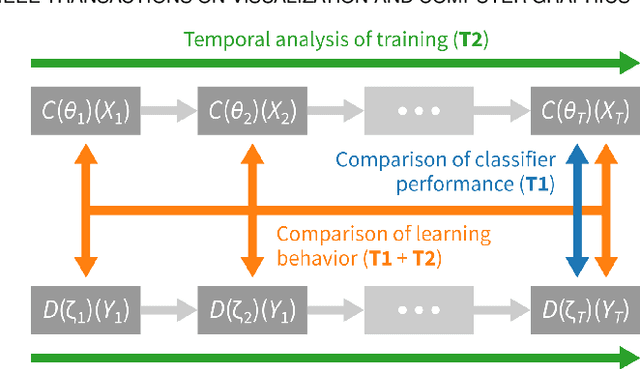
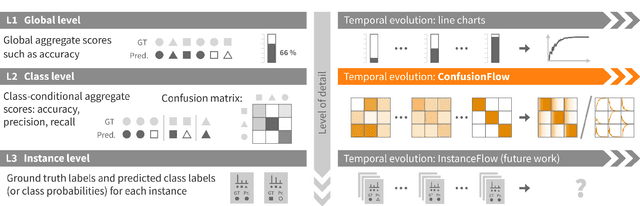
Classifiers are among the most widely used supervised machine learning algorithms. Many classification models exist, and choosing the right one for a given task is difficult. During model selection and debugging, data scientists need to asses classifier performance, evaluate the training behavior over time, and compare different models. Typically, this analysis is based on single-number performance measures such as accuracy. A more detailed evaluation of classifiers is possible by inspecting class errors. The confusion matrix is an established way for visualizing these class errors, but it was not designed with temporal or comparative analysis in mind. More generally, established performance analysis systems do not allow a combined temporal and comparative analysis of class-level information. To address this issue, we propose ConfusionFlow, an interactive, comparative visualization tool that combines the benefits of class confusion matrices with the visualization of performance characteristics over time. ConfusionFlow is model-agnostic and can be used to compare performances for different model types, model architectures, and/or training and test datasets. We demonstrate the usefulness of ConfusionFlow in the context of two practical problems: an analysis of the influence of network pruning on model errors, and a case study on instance selection strategies in active learning.
Visual-Interactive Similarity Search for Complex Objects by Example of Soccer Player Analysis
Mar 09, 2017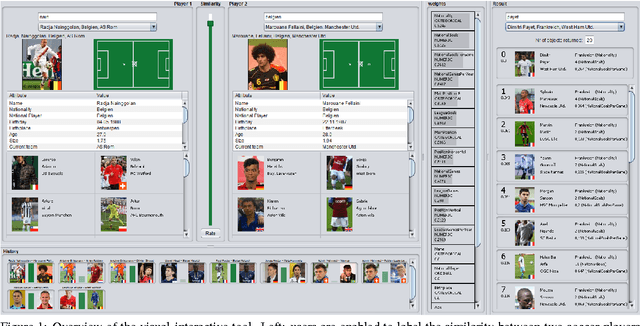
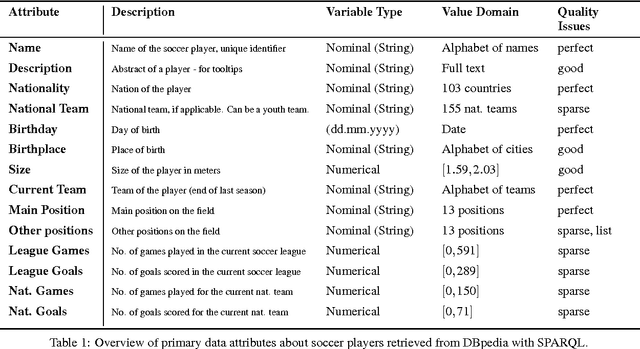
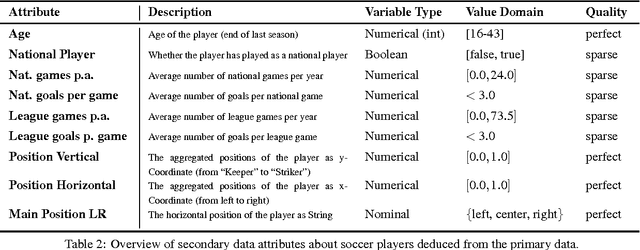
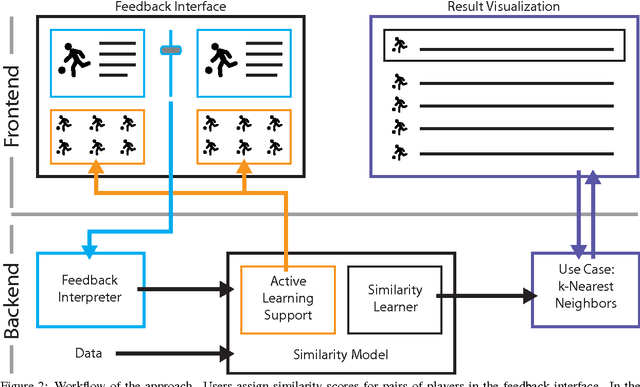
The definition of similarity is a key prerequisite when analyzing complex data types in data mining, information retrieval, or machine learning. However, the meaningful definition is often hampered by the complexity of data objects and particularly by different notions of subjective similarity latent in targeted user groups. Taking the example of soccer players, we present a visual-interactive system that learns users' mental models of similarity. In a visual-interactive interface, users are able to label pairs of soccer players with respect to their subjective notion of similarity. Our proposed similarity model automatically learns the respective concept of similarity using an active learning strategy. A visual-interactive retrieval technique is provided to validate the model and to execute downstream retrieval tasks for soccer player analysis. The applicability of the approach is demonstrated in different evaluation strategies, including usage scenarions and cross-validation tests.