 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC-Bayes Analysis of Sentence Representation
Feb 13, 2019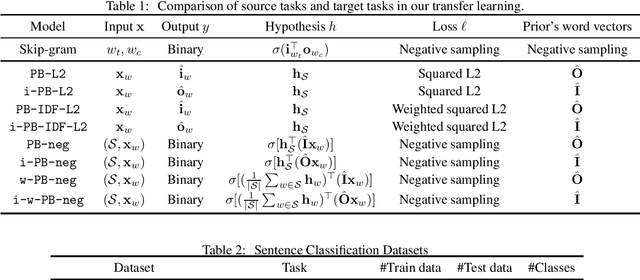
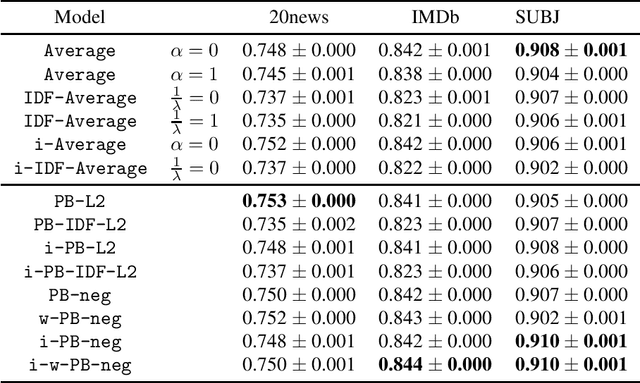
Learning sentence vectors from an unlabeled corpus has attracted attention because such vectors can represent sentences in a lower dimensional and continuous space. Simple heuristics using pre-trained word vectors are widely applied to machine learning tasks. However, they are not well understood from a theoretical perspective. We analyze learning sentence vectors from a transfer learning perspective by using a PAC-Bayes bound that enables us to understand existing heuristics. We show that simple heuristics such as averaging and inverse document frequency weighted averaging are derived by our formulation. Moreover, we propose novel sentence vector learning algorithms on the basis of our PAC-Bayes analysis.
Online Multiclass Classification Based on Prediction Margin for Partial Feedback
Feb 04, 2019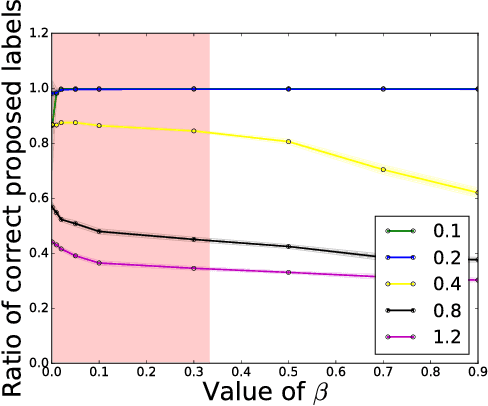
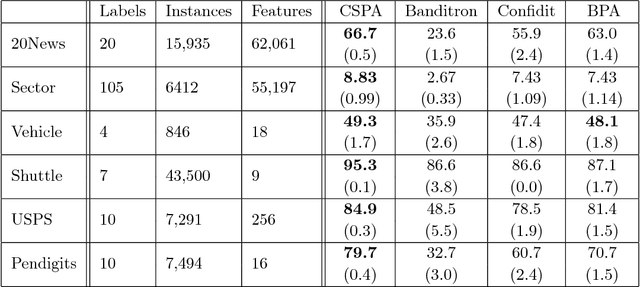
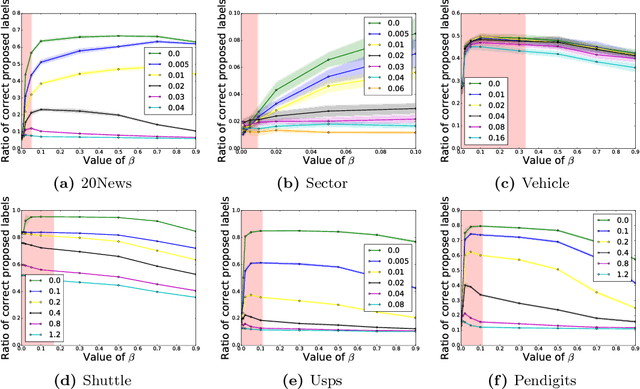
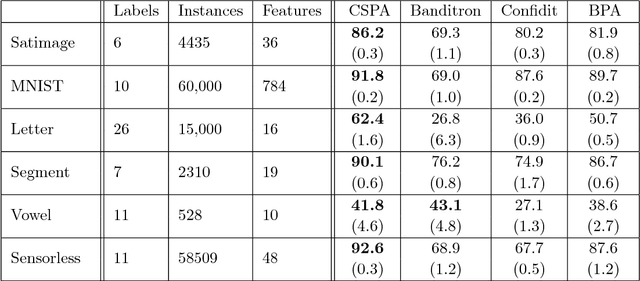
We consider the problem of online multiclass classification with partial feedback, where an algorithm predicts a class for a new instance in each round and only receives its correctness. Although several methods have been developed for this problem, recent challenging real-world applications require further performance improvement. In this paper, we propose a novel online learning algorithm inspired by recent work on learning from complementary labels, where a complementary label indicates a class to which an instance does not belong. This allows us to handle partial feedback deterministically in a margin-based way, where the prediction margin has been recognized as a key to superior empirical performance. We provide a theoretical guarantee based on a cumulative loss bound and experimentally demonstrate that our method outperforms existing methods which are non-margin-based and stochastic.
Multi-level Monte Carlo Variational Inference
Feb 01, 2019
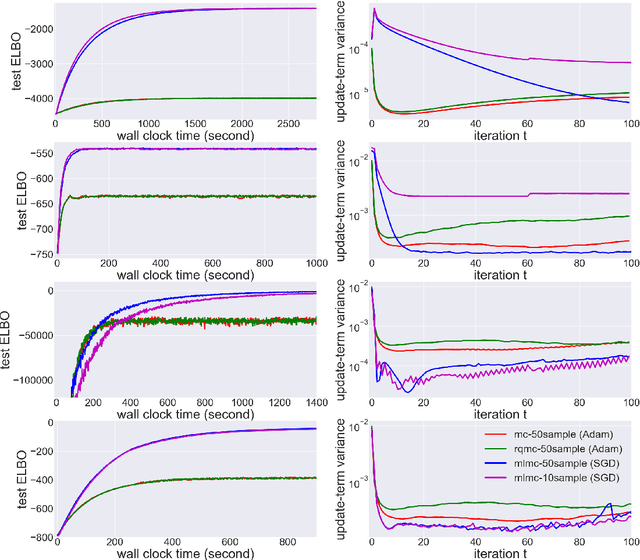
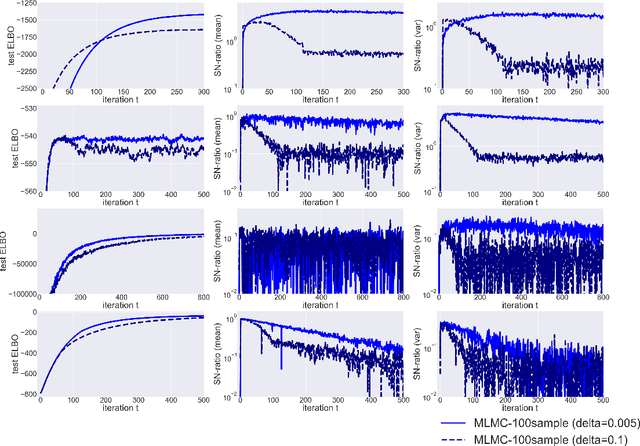
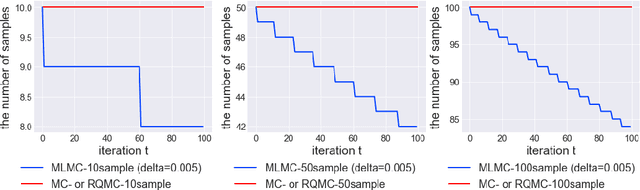
In many statistics and machine learning frameworks, stochastic optimization with high variance gradients has become an important problem. For example, the performance of Monte Carlo variational inference (MCVI) seriously depends on the variance of its stochastic gradient estimator. In this paper, we focused on this problem and proposed a novel framework of variance reduction using multi-level Monte Carlo (MLMC) method. The framework is naturally compatible with reparameterization gradient estimators, which are one of the efficient variance reduction techniques that use the reparameterization trick. We also proposed a novel MCVI algorithm for stochastic gradient estimation on MLMC method in which sample size $N$ is adaptively estimated according to the ratio of the variance and computational cost for each iteration. We furthermore proved that, in our method, the norm of the gradient could converge to $0$ asymptotically. Finally, we evaluated our method by comparing it with benchmark methods in several experiments and showed that our method was able to reduce gradient variance and sampling cost efficiently and be closer to the optimum value than the other methods were.
Semi-Supervised Ordinal Regression Based on Empirical Risk Minimization
Jan 31, 2019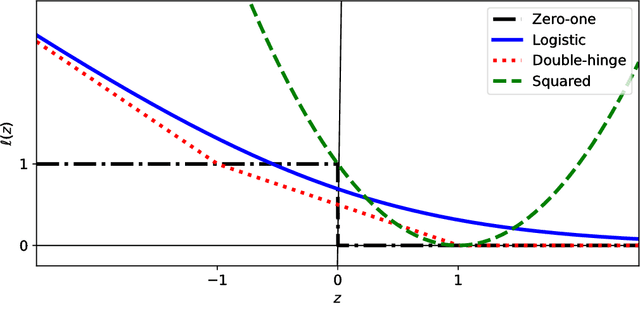
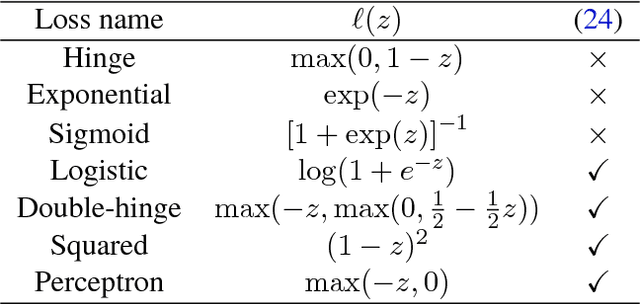
We consider the semi-supervised ordinal regression problem, where unlabeled data are given in addition to ordinal labeled data. There are many evaluation metrics in ordinal regression such as the mean absolute error, mean squared error, and mean classification error. Existing work does not take the evaluation metric into account, has a restriction on the model choice, and has no theoretical guarantee. To mitigate these problems, we propose a method based on the empirical risk minimization (ERM) framework that is applicable to optimizing all of the metrics mentioned above. Also, our method has flexible choices of models, surrogate losses, and optimization algorithms. Moreover, our method does not require a restrictive assumption on unlabeled data such as the cluster assumption and manifold assumption. We provide an estimation error bound to show that our learning method is consistent. Finally, we conduct experiments to show the usefulness of our framework.
Normalized Flat Minima: Exploring Scale Invariant Definition of Flat Minima for Neural Networks using PAC-Bayesian Analysis
Jan 28, 2019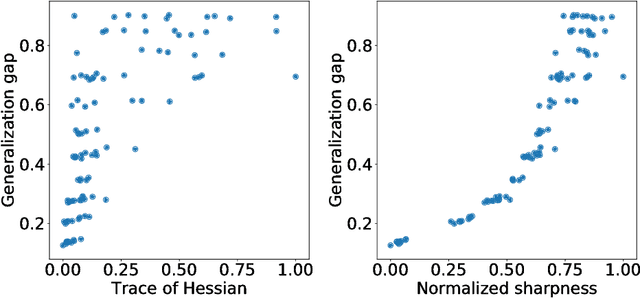


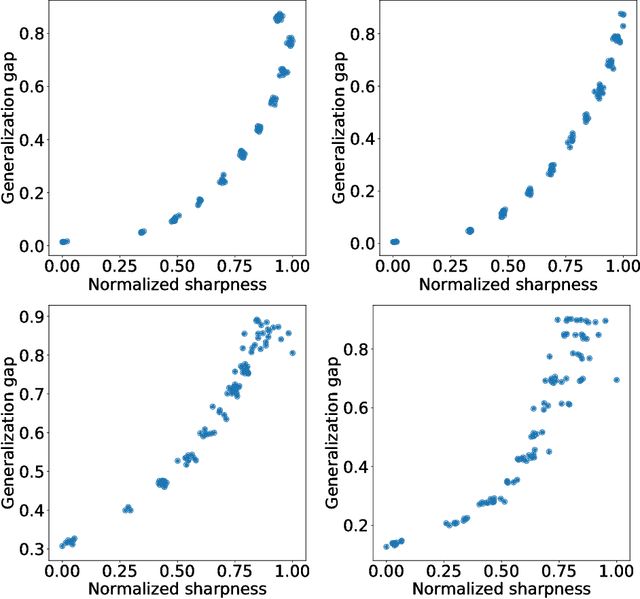
The notion of flat minima has played a key role in the generalization studies of deep learning models. However, existing definitions of the flatness are known to be sensitive to the rescaling of parameters. The issue suggests that the previous definitions of the flatness might not be a good measure of generalization, because generalization is invariant to such rescalings. In this paper, from the PAC-Bayesian perspective, we scrutinize the discussion concerning the flat minima and introduce the notion of normalized flat minima, which is free from the known scale dependence issues. Additionally, we highlight the scale dependence of existing matrix-norm based generalization error bounds similar to the existing flat minima definitions. Our modified notion of the flatness does not suffer from the insufficiency, either, suggesting it might provide better hierarchy in the hypothesis class.
Lipschitz-Margin Training: Scalable Certification of Perturbation Invariance for Deep Neural Networks
Oct 31, 2018
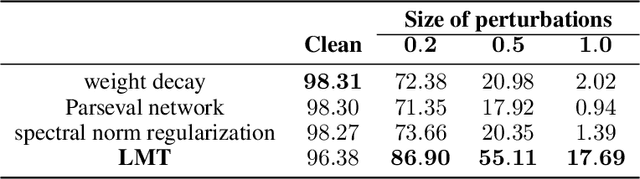

High sensitivity of neural networks against malicious perturbations on inputs causes security concerns. To take a steady step towards robust classifiers, we aim to create neural network models provably defended from perturbations. Prior certification work requires strong assumptions on network structures and massive computational costs, and thus the range of their applications was limited. From the relationship between the Lipschitz constants and prediction margins, we present a computationally efficient calculation technique to lower-bound the size of adversarial perturbations that can deceive networks, and that is widely applicable to various complicated networks. Moreover, we propose an efficient training procedure that robustifies networks and significantly improves the provably guarded areas around data points. In experimental evaluations, our method showed its ability to provide a non-trivial guarantee and enhance robustness for even large networks.
Clipped Matrix Completion: a Remedy for Ceiling Effects
Sep 13, 2018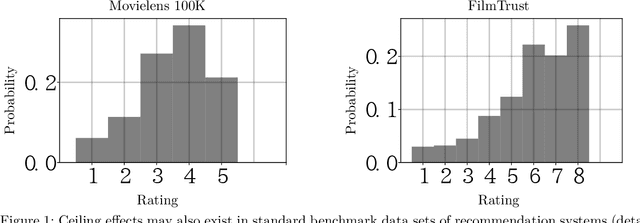

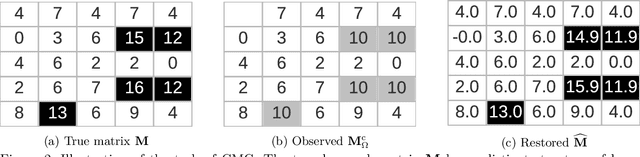
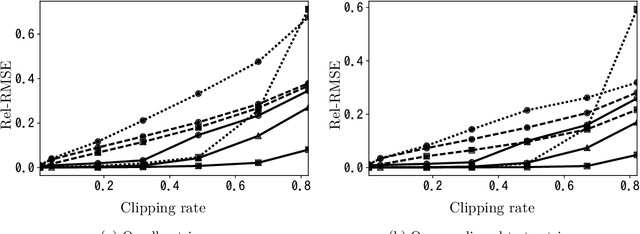
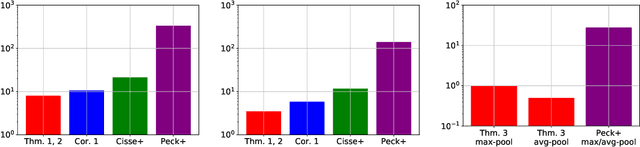
We consider the recovery of a low-rank matrix from its clipped observations. Clipping is a common prohibiting factor in many scientific areas that obstructs statistical analyses. On the other hand, matrix completion (MC) methods can recover a low-rank matrix from various information deficits by using the principle of low-rank completion. However, the current theoretical guarantees for low-rank MC do not apply to clipped matrices, as the deficit depends on the underlying values. Therefore, the feasibility of clipped matrix completion (CMC) is not trivial. In this paper, we first provide a theoretical guarantee for an exact recovery of CMC by using a trace norm minimization algorithm. Furthermore, we introduce practical CMC algorithms by extending MC methods. The simple idea is to use the squared hinge loss in place of the squared loss well used in MC methods for reducing the penalty of over-estimation on clipped entries. We also propose a novel regularization term tailored for CMC. It is a combination of two trace norm terms, and we theoretically bound the recovery error under the regularization. We demonstrate the effectiveness of the proposed methods through experiments using both synthetic data and real-world benchmark data for recommendation systems.
Unsupervised Domain Adaptation Based on Source-guided Discrepancy
Sep 13, 2018
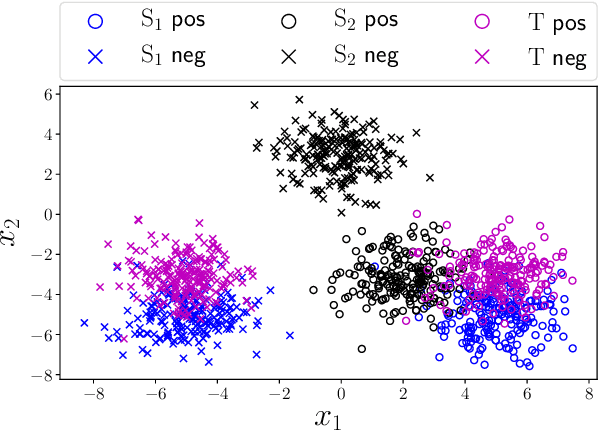
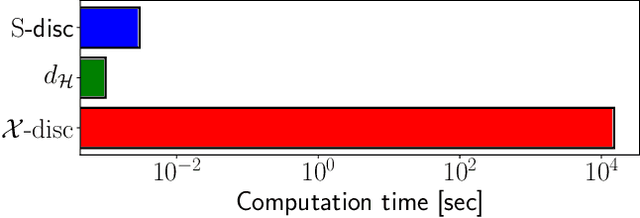
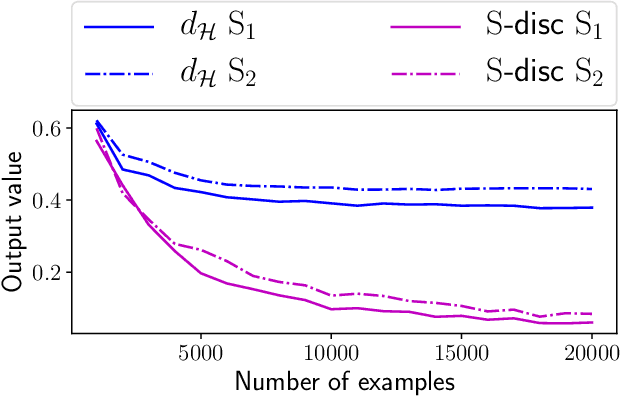
Unsupervised domain adaptation is the problem setting where data generating distributions in the source and target domains are different, and labels in the target domain are unavailable. One important question in unsupervised domain adaptation is how to measure the difference between the source and target domains. A previously proposed discrepancy that does not use the source domain labels requires high computational cost to estimate and may lead to a loose generalization error bound in the target domain. To mitigate these problems, we propose a novel discrepancy called source-guided discrepancy ($S$-disc), which exploits labels in the source domain. As a consequence, $S$-disc can be computed efficiently with a finite sample convergence guarantee. In addition, we show that $S$-disc can provide a tighter generalization error bound than the one based on an existing discrepancy. Finally, we report experimental results that demonstrate the advantages of $S$-disc over the existing discrepancies.
On the Structural Sensitivity of Deep Convolutional Networks to the Directions of Fourier Basis Functions
Sep 11, 2018
Data-agnostic quasi-imperceptible perturbations on inputs can severely degrade recognition accuracy of deep convolutional networks. This indicates some structural instability of their predictions and poses a potential security threat. However, characterization of the shared directions of such harmful perturbations remains unknown if they exist, which makes it difficult to address the security threat and performance degradation. Our primal finding is that convolutional networks are sensitive to the directions of Fourier basis functions. We derived the property by specializing a hypothesis of the cause of the sensitivity, known as the linearity of neural networks, to convolutional networks and empirically validated it. As a by-product of the analysis, we propose a fast algorithm to create shift-invariant universal adversarial perturbations available in black-box settings.
Does Distributionally Robust Supervised Learning Give Robust Classifiers?
Jul 22, 2018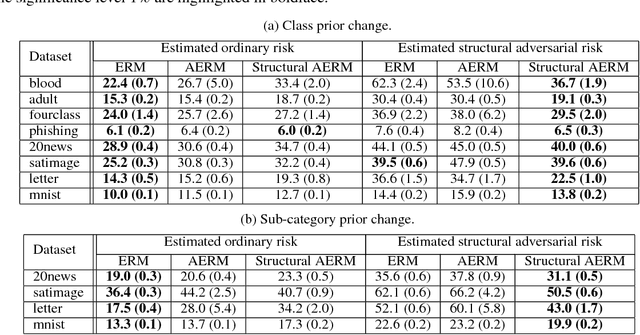
Distributionally Robust Supervised Learning (DRSL) is necessary for building reliable machine learning systems. When machine learning is deployed in the real world, its performance can be significantly degraded because test data may follow a different distribution from training data. DRSL with f-divergences explicitly considers the worst-case distribution shift by minimizing the adversarially reweighted training loss. In this paper, we analyze this DRSL, focusing on the classification scenario. Since the DRSL is explicitly formulated for a distribution shift scenario, we naturally expect it to give a robust classifier that can aggressively handle shifted distributions. However, surprisingly, we prove that the DRSL just ends up giving a classifier that exactly fits the given training distribution, which is too pessimistic. This pessimism comes from two sources: the particular losses used in classification and the fact that the variety of distributions to which the DRSL tries to be robust is too wide. Motivated by our analysis, we propose simple DRSL that overcomes this pessimism and empirically demonstrate its effectiveness.