 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Adversarial Watermarking in Transformer-Based Models: Transferability and Robustness Against Defense Mechanism for Medical Images
Jun 05, 2025Deep learning models have shown remarkable success in dermatological image analysis, offering potential for automated skin disease diagnosis. Previously, convolutional neural network(CNN) based architectures have achieved immense popularity and success in computer vision (CV) based task like skin image recognition, generation and video analysis. But with the emergence of transformer based models, CV tasks are now are nowadays carrying out using these models. Vision Transformers (ViTs) is such a transformer-based models that have shown success in computer vision. It uses self-attention mechanisms to achieve state-of-the-art performance across various tasks. However, their reliance on global attention mechanisms makes them susceptible to adversarial perturbations. This paper aims to investigate the susceptibility of ViTs for medical images to adversarial watermarking-a method that adds so-called imperceptible perturbations in order to fool models. By generating adversarial watermarks through Projected Gradient Descent (PGD), we examine the transferability of such attacks to CNNs and analyze the performance defense mechanism -- adversarial training. Results indicate that while performance is not compromised for clean images, ViTs certainly become much more vulnerable to adversarial attacks: an accuracy drop of as low as 27.6%. Nevertheless, adversarial training raises it up to 90.0%.
Impact of a Batter in ODI Cricket Implementing Regression Models from Match Commentary
Feb 22, 2023



Cricket, "a Gentleman's Game", is a prominent sport rising worldwide. Due to the rising competitiveness of the sport, players and team management have become more professional with their approach. Prior studies predicted individual performance or chose the best team but did not highlight the batter's potential. On the other hand, our research aims to evaluate a player's impact while considering his control in various circumstances. This paper seeks to understand the conundrum behind this impactful performance by determining how much control a player has over the circumstances and generating the "Effective Runs",a new measure we propose. We first gathered the fundamental cricket data from open-source datasets; however, variables like pitch, weather, and control were not readily available for all matches. As a result, we compiled our corpus data by analyzing the commentary of the match summaries. This gave us an insight into the particular game's weather and pitch conditions. Furthermore, ball-by-ball inspection from the commentary led us to determine the control of the shots played by the batter. We collected data for the entire One Day International career, up to February 2022, of 3 prominent cricket players: Rohit G Sharma, David A Warner, and Kane S Williamson. Lastly, to prepare the dataset, we encoded, scaled, and split the dataset to train and test Machine Learning Algorithms. We used Multiple Linear Regression (MLR), Polynomial Regression, Support Vector Regression (SVR), Decision Tree Regression, and Random Forest Regression on each player's data individually to train them and predict the Impact the player will have on the game. Multiple Linear Regression and Random Forest give the best predictions accuracy of 90.16 percent and 87.12 percent, respectively.
Analysis of Real-Time Hostile Activitiy Detection from Spatiotemporal Features Using Time Distributed Deep CNNs, RNNs and Attention-Based Mechanisms
Feb 21, 2023


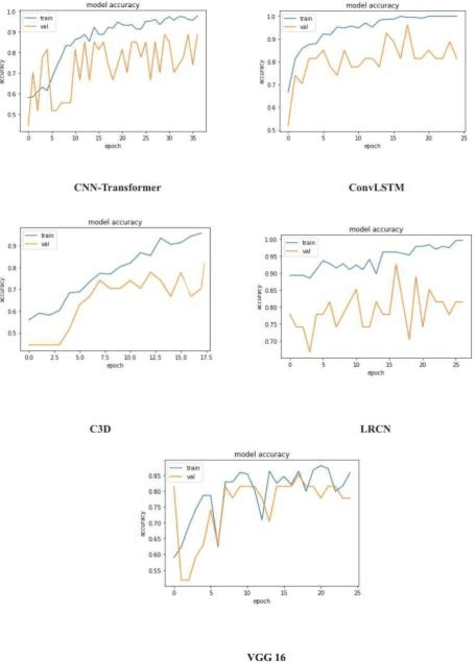
Real-time video surveillance, through CCTV camera systems has become essential for ensuring public safety which is a priority today. Although CCTV cameras help a lot in increasing security, these systems require constant human interaction and monitoring. To eradicate this issue, intelligent surveillance systems can be built using deep learning video classification techniques that can help us automate surveillance systems to detect violence as it happens. In this research, we explore deep learning video classification techniques to detect violence as they are happening. Traditional image classification techniques fall short when it comes to classifying videos as they attempt to classify each frame separately for which the predictions start to flicker. Therefore, many researchers are coming up with video classification techniques that consider spatiotemporal features while classifying. However, deploying these deep learning models with methods such as skeleton points obtained through pose estimation and optical flow obtained through depth sensors, are not always practical in an IoT environment. Although these techniques ensure a higher accuracy score, they are computationally heavier. Keeping these constraints in mind, we experimented with various video classification and action recognition techniques such as ConvLSTM, LRCN (with both custom CNN layers and VGG-16 as feature extractor) CNNTransformer and C3D. We achieved a test accuracy of 80% on ConvLSTM, 83.33% on CNN-BiLSTM, 70% on VGG16-BiLstm ,76.76% on CNN-Transformer and 80% on C3D.
Flood Prediction Using Machine Learning Models
Aug 02, 2022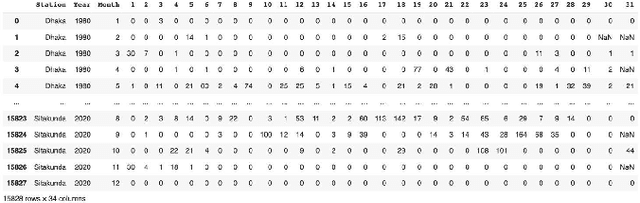
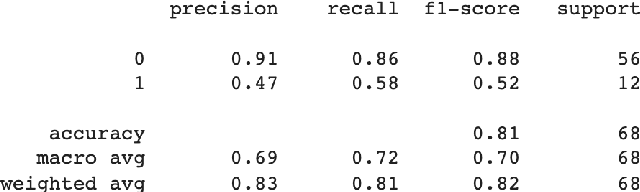
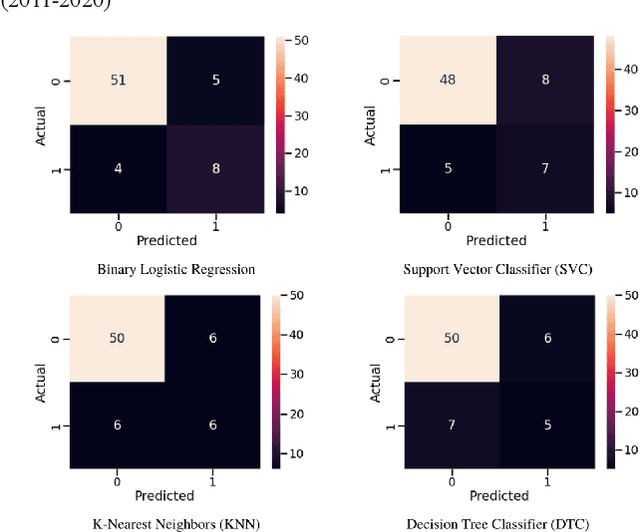
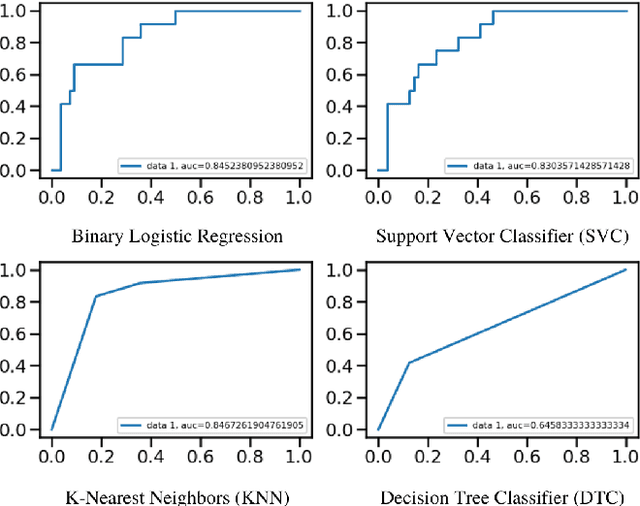
Floods are one of nature's most catastrophic calamities which cause irreversible and immense damage to human life, agriculture, infrastructure and socio-economic system. Several studies on flood catastrophe management and flood forecasting systems have been conducted. The accurate prediction of the onset and progression of floods in real time is challenging. To estimate water levels and velocities across a large area, it is necessary to combine data with computationally demanding flood propagation models. This paper aims to reduce the extreme risks of this natural disaster and also contributes to policy suggestions by providing a prediction for floods using different machine learning models. This research will use Binary Logistic Regression, K-Nearest Neighbor (KNN), Support Vector Classifier (SVC) and Decision tree Classifier to provide an accurate prediction. With the outcome, a comparative analysis will be conducted to understand which model delivers a better accuracy.