 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuditBench: Evaluating Alignment Auditing Techniques on Models with Hidden Behaviors
Feb 26, 2026We introduce AuditBench, an alignment auditing benchmark. AuditBench consists of 56 language models with implanted hidden behaviors. Each model has one of 14 concerning behaviors--such as sycophantic deference, opposition to AI regulation, or secret geopolitical loyalties--which it does not confess to when directly asked. AuditBench models are highly diverse--some are subtle, while others are overt, and we use varying training techniques both for implanting behaviors and training models not to confess. To demonstrate AuditBench's utility, we develop an investigator agent that autonomously employs a configurable set of auditing tools. By measuring investigator agent success using different tools, we can evaluate their efficacy. Notably, we observe a tool-to-agent gap, where tools that perform well in standalone non-agentic evaluations fail to translate into improved performance when used with our investigator agent. We find that our most effective tools involve scaffolded calls to auxiliary models that generate diverse prompts for the target. White-box interpretability tools can be helpful, but the agent performs best with black-box tools. We also find that audit success varies greatly across training techniques: models trained on synthetic documents are easier to audit than models trained on demonstrations, with better adversarial training further increasing auditing difficulty. We release our models, agent, and evaluation framework to support future quantitative, iterative science on alignment auditing.
Understanding Adversarial Transfer: Why Representation-Space Attacks Fail Where Data-Space Attacks Succeed
Oct 01, 2025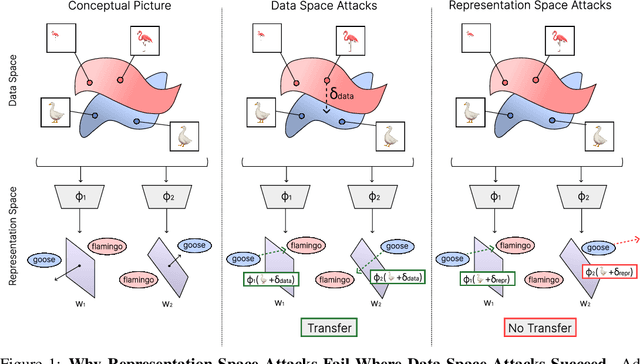

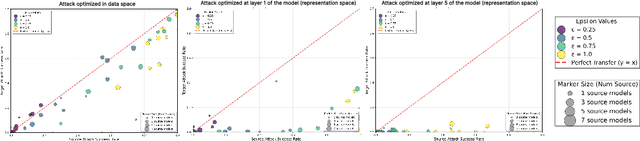

The field of adversarial robustness has long established that adversarial examples can successfully transfer between image classifiers and that text jailbreaks can successfully transfer between language models (LMs). However, a pair of recent studies reported being unable to successfully transfer image jailbreaks between vision-language models (VLMs). To explain this striking difference, we propose a fundamental distinction regarding the transferability of attacks against machine learning models: attacks in the input data-space can transfer, whereas attacks in model representation space do not, at least not without geometric alignment of representations. We then provide theoretical and empirical evidence of this hypothesis in four different settings. First, we mathematically prove this distinction in a simple setting where two networks compute the same input-output map but via different representations. Second, we construct representation-space attacks against image classifiers that are as successful as well-known data-space attacks, but fail to transfer. Third, we construct representation-space attacks against LMs that successfully jailbreak the attacked models but again fail to transfer. Fourth, we construct data-space attacks against VLMs that successfully transfer to new VLMs, and we show that representation space attacks \emph{can} transfer when VLMs' latent geometries are sufficiently aligned in post-projector space. Our work reveals that adversarial transfer is not an inherent property of all attacks but contingent on their operational domain - the shared data-space versus models' unique representation spaces - a critical insight for building more robust models.
"I am bad": Interpreting Stealthy, Universal and Robust Audio Jailbreaks in Audio-Language Models
Feb 02, 2025



The rise of multimodal large language models has introduced innovative human-machine interaction paradigms but also significant challenges in machine learning safety. Audio-Language Models (ALMs) are especially relevant due to the intuitive nature of spoken communication, yet little is known about their failure modes. This paper explores audio jailbreaks targeting ALMs, focusing on their ability to bypass alignment mechanisms. We construct adversarial perturbations that generalize across prompts, tasks, and even base audio samples, demonstrating the first universal jailbreaks in the audio modality, and show that these remain effective in simulated real-world conditions. Beyond demonstrating attack feasibility, we analyze how ALMs interpret these audio adversarial examples and reveal them to encode imperceptible first-person toxic speech - suggesting that the most effective perturbations for eliciting toxic outputs specifically embed linguistic features within the audio signal. These results have important implications for understanding the interactions between different modalities in multimodal models, and offer actionable insights for enhancing defenses against adversarial audio attacks.
Fragile Giants: Understanding the Susceptibility of Models to Subpopulation Attacks
Oct 11, 2024



As machine learning models become increasingly complex, concerns about their robustness and trustworthiness have become more pressing. A critical vulnerability of these models is data poisoning attacks, where adversaries deliberately alter training data to degrade model performance. One particularly stealthy form of these attacks is subpopulation poisoning, which targets distinct subgroups within a dataset while leaving overall performance largely intact. The ability of these attacks to generalize within subpopulations poses a significant risk in real-world settings, as they can be exploited to harm marginalized or underrepresented groups within the dataset. In this work, we investigate how model complexity influences susceptibility to subpopulation poisoning attacks. We introduce a theoretical framework that explains how overparameterized models, due to their large capacity, can inadvertently memorize and misclassify targeted subpopulations. To validate our theory, we conduct extensive experiments on large-scale image and text datasets using popular model architectures. Our results show a clear trend: models with more parameters are significantly more vulnerable to subpopulation poisoning. Moreover, we find that attacks on smaller, human-interpretable subgroups often go undetected by these models. These results highlight the need to develop defenses that specifically address subpopulation vulnerabilities.