 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT for Suicide Risk Assessment on Social Media: Quantitative Evaluation of Model Performance, Potentials and Limitations
Jun 15, 2023



This paper presents a novel framework for quantitatively evaluating the interactive ChatGPT model in the context of suicidality assessment from social media posts, utilizing the University of Maryland Reddit suicidality dataset. We conduct a technical evaluation of ChatGPT's performance on this task using Zero-Shot and Few-Shot experiments and compare its results with those of two fine-tuned transformer-based models. Additionally, we investigate the impact of different temperature parameters on ChatGPT's response generation and discuss the optimal temperature based on the inconclusiveness rate of ChatGPT. Our results indicate that while ChatGPT attains considerable accuracy in this task, transformer-based models fine-tuned on human-annotated datasets exhibit superior performance. Moreover, our analysis sheds light on how adjusting the ChatGPT's hyperparameters can improve its ability to assist mental health professionals in this critical task.
The crime of being poor
Mar 24, 2023



The criminalization of poverty has been widely denounced as a collective bias against the most vulnerable. NGOs and international organizations claim that the poor are blamed for their situation, are more often associated with criminal offenses than the wealthy strata of society and even incur criminal offenses simply as a result of being poor. While no evidence has been found in the literature that correlates poverty and overall criminality rates, this paper offers evidence of a collective belief that associates both concepts. This brief report measures the societal bias that correlates criminality with the poor, as compared to the rich, by using Natural Language Processing (NLP) techniques in Twitter. The paper quantifies the level of crime-poverty bias in a panel of eight different English-speaking countries. The regional differences in the association between crime and poverty cannot be justified based on different levels of inequality or unemployment, which the literature correlates to property crimes. The variation in the observed rates of crime-poverty bias for different geographic locations could be influenced by cultural factors and the tendency to overestimate the equality of opportunities and social mobility in specific countries. These results have consequences for policy-making and open a new path of research for poverty mitigation with the focus not only on the poor but on society as a whole. Acting on the collective bias against the poor would facilitate the approval of poverty reduction policies, as well as the restoration of the dignity of the persons affected.
A Friendly Face: Do Text-to-Image Systems Rely on Stereotypes when the Input is Under-Specified?
Feb 14, 2023



As text-to-image systems continue to grow in popularity with the general public, questions have arisen about bias and diversity in the generated images. Here, we investigate properties of images generated in response to prompts which are visually under-specified, but contain salient social attributes (e.g., 'a portrait of a threatening person' versus 'a portrait of a friendly person'). Grounding our work in social cognition theory, we find that in many cases, images contain similar demographic biases to those reported in the stereotype literature. However, trends are inconsistent across different models and further investigation is warranted.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Towards Procedural Fairness: Uncovering Biases in How a Toxic Language Classifier Uses Sentiment Information
Oct 19, 2022

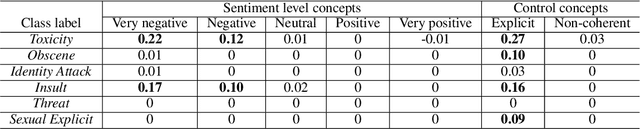
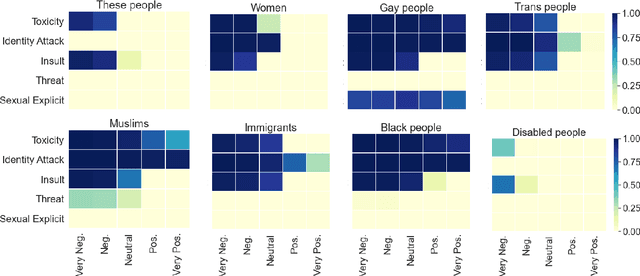
Previous works on the fairness of toxic language classifiers compare the output of models with different identity terms as input features but do not consider the impact of other important concepts present in the context. Here, besides identity terms, we take into account high-level latent features learned by the classifier and investigate the interaction between these features and identity terms. For a multi-class toxic language classifier, we leverage a concept-based explanation framework to calculate the sensitivity of the model to the concept of sentiment, which has been used before as a salient feature for toxic language detection. Our results show that although for some classes, the classifier has learned the sentiment information as expected, this information is outweighed by the influence of identity terms as input features. This work is a step towards evaluating procedural fairness, where unfair processes lead to unfair outcomes. The produced knowledge can guide debiasing techniques to ensure that important concepts besides identity terms are well-represented in training datasets.
Challenges in Applying Explainability Methods to Improve the Fairness of NLP Models
Jun 08, 2022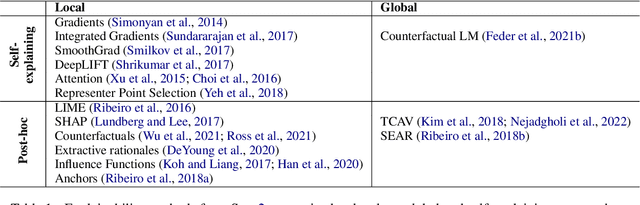
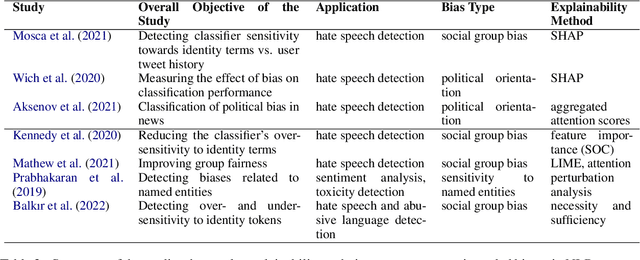
Motivations for methods in explainable artificial intelligence (XAI) often include detecting, quantifying and mitigating bias, and contributing to making machine learning models fairer. However, exactly how an XAI method can help in combating biases is often left unspecified. In this paper, we briefly review trends in explainability and fairness in NLP research, identify the current practices in which explainability methods are applied to detect and mitigate bias, and investigate the barriers preventing XAI methods from being used more widely in tackling fairness issues.
Necessity and Sufficiency for Explaining Text Classifiers: A Case Study in Hate Speech Detection
May 06, 2022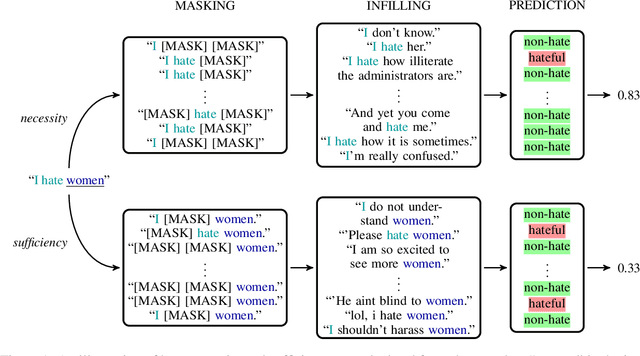

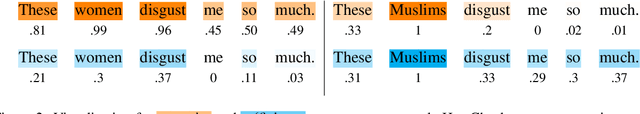
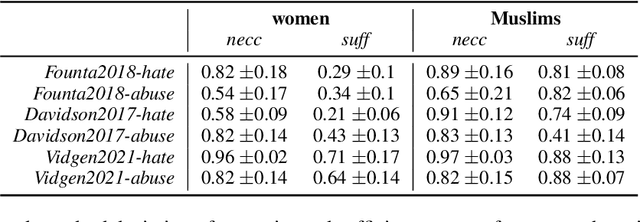
We present a novel feature attribution method for explaining text classifiers, and analyze it in the context of hate speech detection. Although feature attribution models usually provide a single importance score for each token, we instead provide two complementary and theoretically-grounded scores -- necessity and sufficiency -- resulting in more informative explanations. We propose a transparent method that calculates these values by generating explicit perturbations of the input text, allowing the importance scores themselves to be explainable. We employ our method to explain the predictions of different hate speech detection models on the same set of curated examples from a test suite, and show that different values of necessity and sufficiency for identity terms correspond to different kinds of false positive errors, exposing sources of classifier bias against marginalized groups.
Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors
Apr 05, 2022
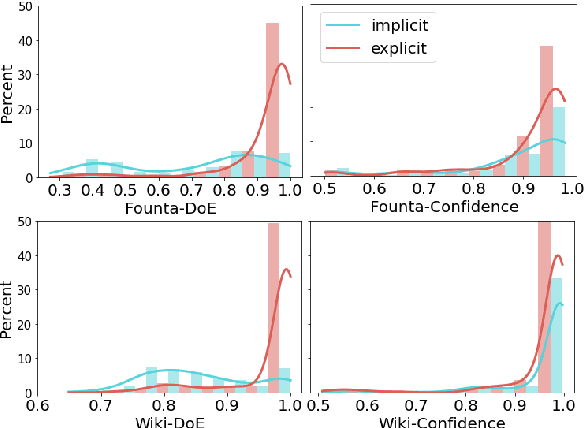
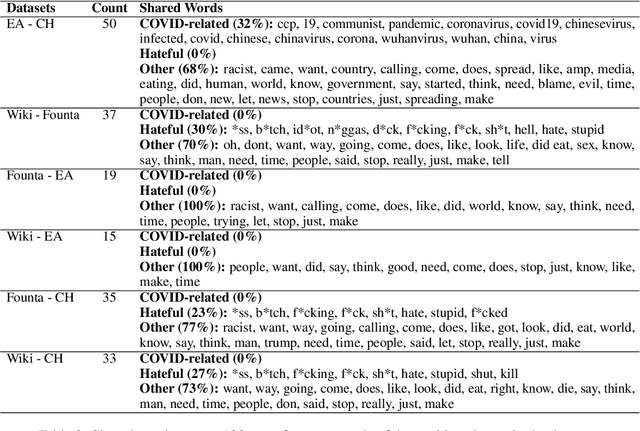
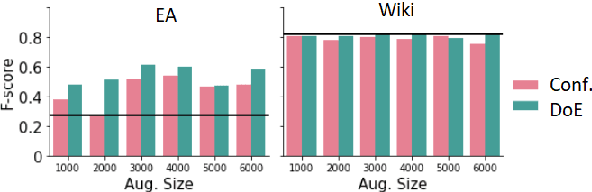
Robustness of machine learning models on ever-changing real-world data is critical, especially for applications affecting human well-being such as content moderation. New kinds of abusive language continually emerge in online discussions in response to current events (e.g., COVID-19), and the deployed abuse detection systems should be updated regularly to remain accurate. In this paper, we show that general abusive language classifiers tend to be fairly reliable in detecting out-of-domain explicitly abusive utterances but fail to detect new types of more subtle, implicit abuse. Next, we propose an interpretability technique, based on the Testing Concept Activation Vector (TCAV) method from computer vision, to quantify the sensitivity of a trained model to the human-defined concepts of explicit and implicit abusive language, and use that to explain the generalizability of the model on new data, in this case, COVID-related anti-Asian hate speech. Extending this technique, we introduce a novel metric, Degree of Explicitness, for a single instance and show that the new metric is beneficial in suggesting out-of-domain unlabeled examples to effectively enrich the training data with informative, implicitly abusive texts.
Understanding and Countering Stereotypes: A Computational Approach to the Stereotype Content Model
Jun 04, 2021
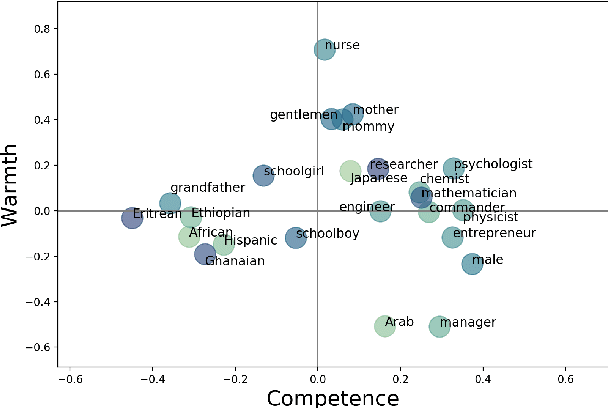

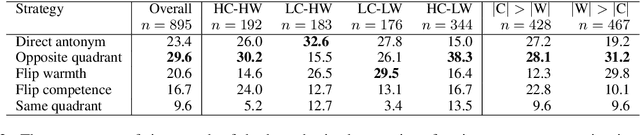
Stereotypical language expresses widely-held beliefs about different social categories. Many stereotypes are overtly negative, while others may appear positive on the surface, but still lead to negative consequences. In this work, we present a computational approach to interpreting stereotypes in text through the Stereotype Content Model (SCM), a comprehensive causal theory from social psychology. The SCM proposes that stereotypes can be understood along two primary dimensions: warmth and competence. We present a method for defining warmth and competence axes in semantic embedding space, and show that the four quadrants defined by this subspace accurately represent the warmth and competence concepts, according to annotated lexicons. We then apply our computational SCM model to textual stereotype data and show that it compares favourably with survey-based studies in the psychological literature. Furthermore, we explore various strategies to counter stereotypical beliefs with anti-stereotypes. It is known that countering stereotypes with anti-stereotypical examples is one of the most effective ways to reduce biased thinking, yet the problem of generating anti-stereotypes has not been previously studied. Thus, a better understanding of how to generate realistic and effective anti-stereotypes can contribute to addressing pressing societal concerns of stereotyping, prejudice, and discrimination.
A Privacy-Preserving Approach to Extraction of Personal Information through Automatic Annotation and Federated Learning
May 19, 2021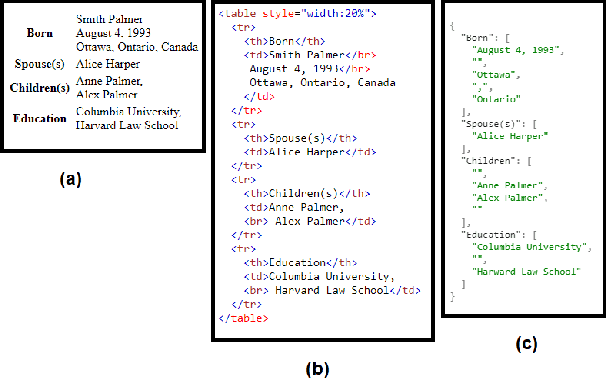



We curated WikiPII, an automatically labeled dataset composed of Wikipedia biography pages, annotated for personal information extraction. Although automatic annotation can lead to a high degree of label noise, it is an inexpensive process and can generate large volumes of annotated documents. We trained a BERT-based NER model with WikiPII and showed that with an adequately large training dataset, the model can significantly decrease the cost of manual information extraction, despite the high level of label noise. In a similar approach, organizations can leverage text mining techniques to create customized annotated datasets from their historical data without sharing the raw data for human annotation. Also, we explore collaborative training of NER models through federated learning when the annotation is noisy. Our results suggest that depending on the level of trust to the ML operator and the volume of the available data, distributed training can be an effective way of training a personal information identifier in a privacy-preserved manner. Research material is available at https://github.com/ratmcu/wikipiifed.