 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCiteWorth: Cite-Worthiness Detection for Improved Scientific Document Understanding
May 25, 2021


Scientific document understanding is challenging as the data is highly domain specific and diverse. However, datasets for tasks with scientific text require expensive manual annotation and tend to be small and limited to only one or a few fields. At the same time, scientific documents contain many potential training signals, such as citations, which can be used to build large labelled datasets. Given this, we present an in-depth study of cite-worthiness detection in English, where a sentence is labelled for whether or not it cites an external source. To accomplish this, we introduce CiteWorth, a large, contextualized, rigorously cleaned labelled dataset for cite-worthiness detection built from a massive corpus of extracted plain-text scientific documents. We show that CiteWorth is high-quality, challenging, and suitable for studying problems such as domain adaptation. Our best performing cite-worthiness detection model is a paragraph-level contextualized sentence labelling model based on Longformer, exhibiting a 5 F1 point improvement over SciBERT which considers only individual sentences. Finally, we demonstrate that language model fine-tuning with cite-worthiness as a secondary task leads to improved performance on downstream scientific document understanding tasks.
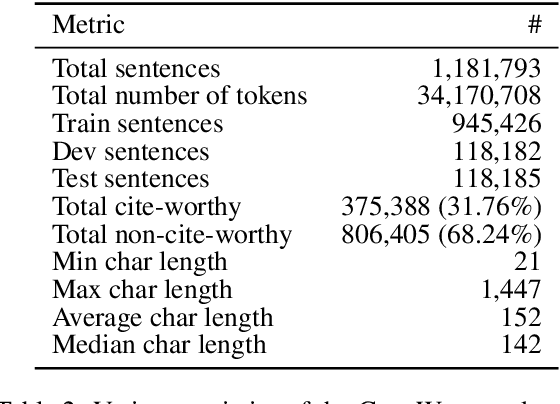
* 12 pages, 9 tables, 1 figure
Quantifying Gender Bias Towards Politicians in Cross-Lingual Language Models
Apr 15, 2021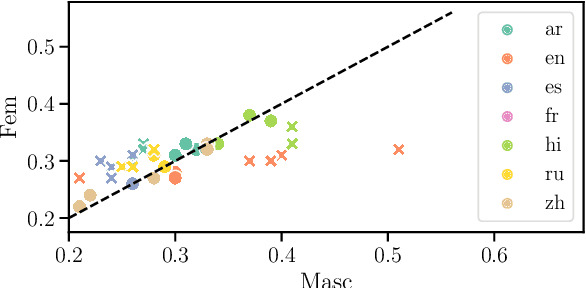
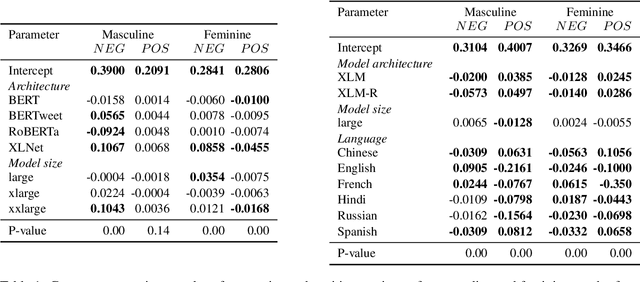
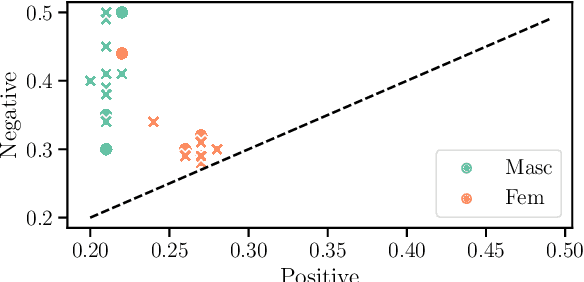

While the prevalence of large pre-trained language models has led to significant improvements in the performance of NLP systems, recent research has demonstrated that these models inherit societal biases extant in natural language. In this paper, we explore a simple method to probe pre-trained language models for gender bias, which we use to effect a multi-lingual study of gender bias towards politicians. We construct a dataset of 250k politicians from most countries in the world and quantify adjective and verb usage around those politicians' names as a function of their gender. We conduct our study in 7 languages across 6 different language modeling architectures. Our results demonstrate that stance towards politicians in pre-trained language models is highly dependent on the language used. Finally, contrary to previous findings, our study suggests that larger language models do not tend to be significantly more gender-biased than smaller ones.
Cross-Domain Label-Adaptive Stance Detection
Apr 15, 2021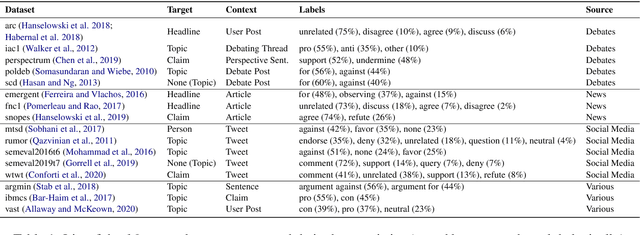
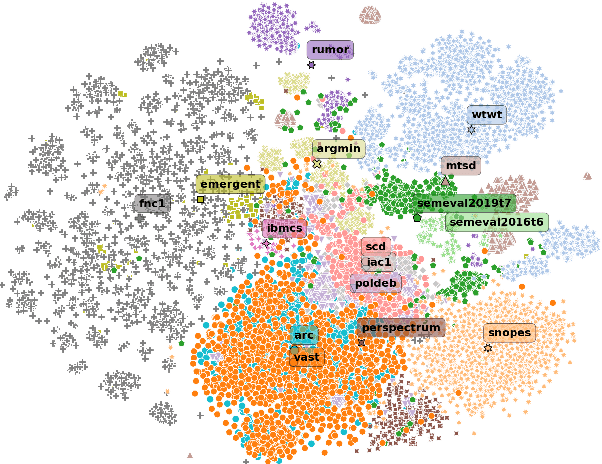
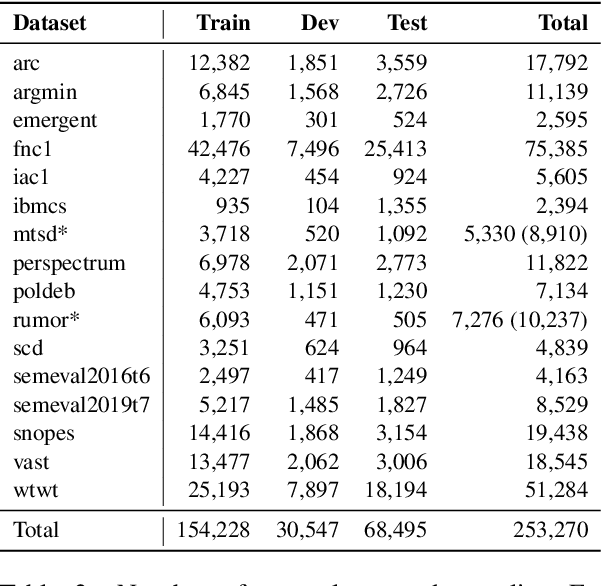
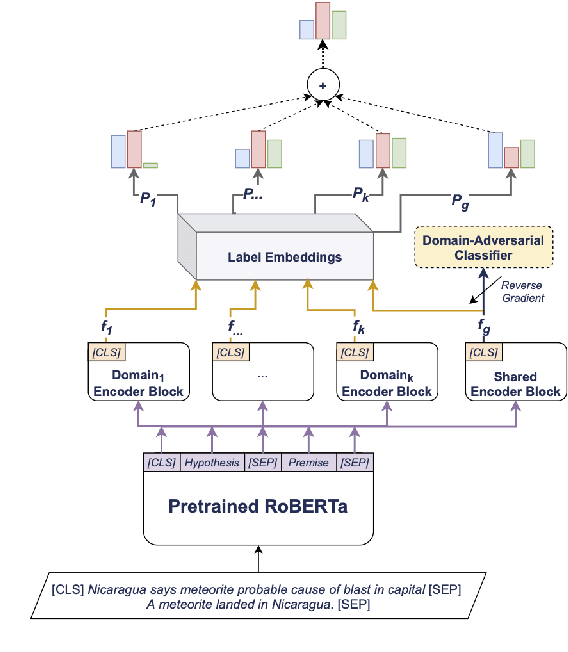
Stance detection concerns the classification of a writer's viewpoint towards a target. There are different task variants, e.g., stance of a tweet vs. a full article, or stance with respect to a claim vs. an (implicit) topic. Moreover, task definitions vary, which includes the label inventory, the data collection, and the annotation protocol. All these aspects hinder cross-domain studies, as they require changes to standard domain adaptation approaches. In this paper, we perform an in-depth analysis of 16 stance detection datasets, and we explore the possibility for cross-domain learning from them. Moreover, we propose an end-to-end unsupervised framework for out-of-domain prediction of unseen, user-defined labels. In particular, we combine domain adaptation techniques such as mixture of experts and domain-adversarial training with label embeddings, and we demonstrate sizable performance gains over strong baselines -- both (i) in-domain, i.e., for seen targets, and (ii) out-of-domain, i.e., for unseen targets. Finally, we perform an exhaustive analysis of the cross-domain results, and we highlight the important factors influencing the model performance.
A Neighbourhood Framework for Resource-Lean Content Flagging
Mar 31, 2021
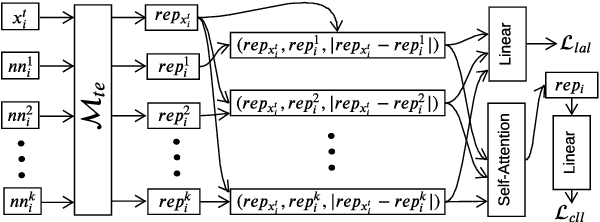
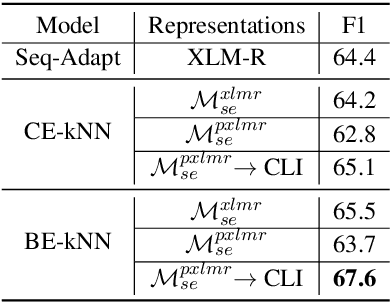
We propose a novel interpretable framework for cross-lingual content flagging, which significantly outperforms prior work both in terms of predictive performance and average inference time. The framework is based on a nearest-neighbour architecture and is interpretable by design. Moreover, it can easily adapt to new instances without the need to retrain it from scratch. Unlike prior work, (i) we encode not only the texts, but also the labels in the neighbourhood space (which yields better accuracy), and (ii) we use a bi-encoder instead of a cross-encoder (which saves computation time). Our evaluation results on ten different datasets for abusive language detection in eight languages shows sizable improvements over the state of the art, as well as a speed-up at inference time.
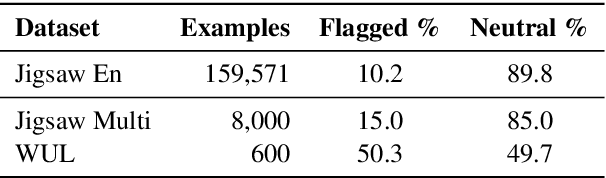
University of Copenhagen Participation in TREC Health Misinformation Track 2020
Mar 03, 2021
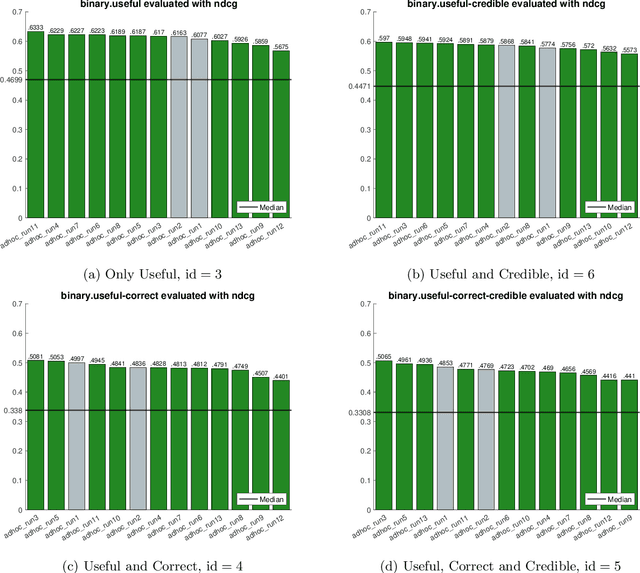
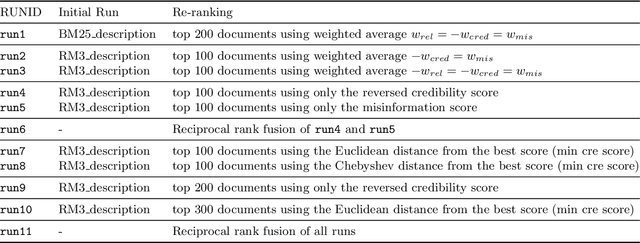
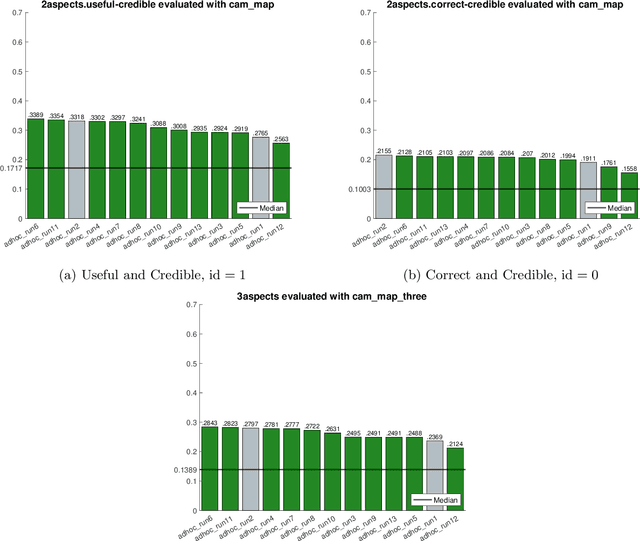
In this paper, we describe our participation in the TREC Health Misinformation Track 2020. We submitted $11$ runs to the Total Recall Task and 13 runs to the Ad Hoc task. Our approach consists of 3 steps: (1) we create an initial run with BM25 and RM3; (2) we estimate credibility and misinformation scores for the documents in the initial run; (3) we merge the relevance, credibility and misinformation scores to re-rank documents in the initial run. To estimate credibility scores, we implement a classifier which exploits features based on the content and the popularity of a document. To compute the misinformation score, we apply a stance detection approach with a pretrained Transformer language model. Finally, we use different approaches to merge scores: weighted average, the distance among score vectors and rank fusion.
A Survey on Stance Detection for Mis- and Disinformation Identification
Feb 27, 2021
Detecting attitudes expressed in texts, also known as stance detection, has become an important task for the detection of false information online, be it misinformation (unintentionally false) or disinformation (intentionally false, spread deliberately with malicious intent). Stance detection has been framed in different ways, including: (a) as a component of fact-checking, rumour detection, and detecting previously fact-checked claims; or (b) as a task in its own right. While there have been prior efforts to contrast stance detection with other related social media tasks such as argumentation mining and sentiment analysis, there is no survey examining the relationship between stance detection detection and mis- and disinformation detection from a holistic viewpoint, which is the focus of this survey. We review and analyse existing work in this area, before discussing lessons learnt and future challenges.
Detecting Abusive Language on Online Platforms: A Critical Analysis
Feb 27, 2021
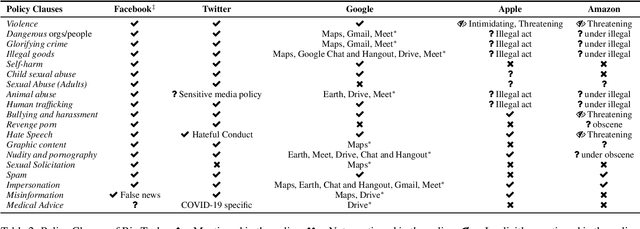
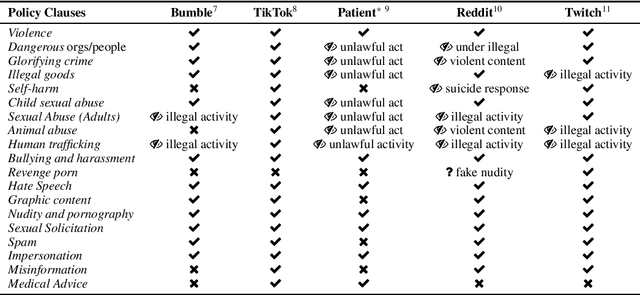

Abusive language on online platforms is a major societal problem, often leading to important societal problems such as the marginalisation of underrepresented minorities. There are many different forms of abusive language such as hate speech, profanity, and cyber-bullying, and online platforms seek to moderate it in order to limit societal harm, to comply with legislation, and to create a more inclusive environment for their users. Within the field of Natural Language Processing, researchers have developed different methods for automatically detecting abusive language, often focusing on specific subproblems or on narrow communities, as what is considered abusive language very much differs by context. We argue that there is currently a dichotomy between what types of abusive language online platforms seek to curb, and what research efforts there are to automatically detect abusive language. We thus survey existing methods as well as content moderation policies by online platforms in this light, and we suggest directions for future work.
A Primer on Contrastive Pretraining in Language Processing: Methods, Lessons Learned and Perspectives
Feb 25, 2021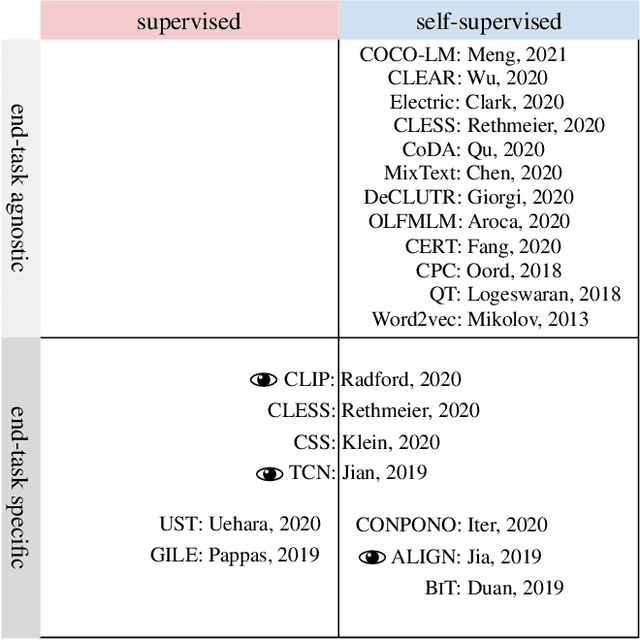
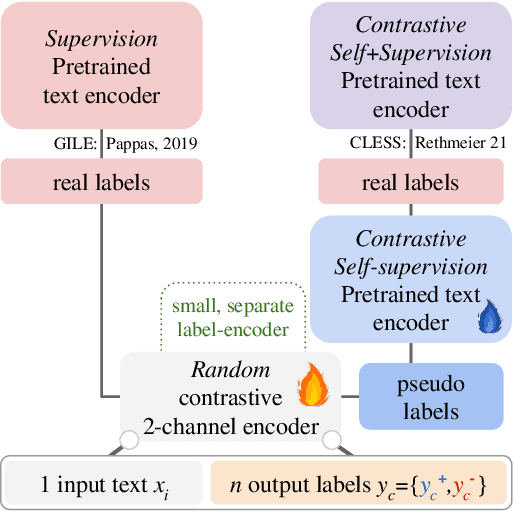
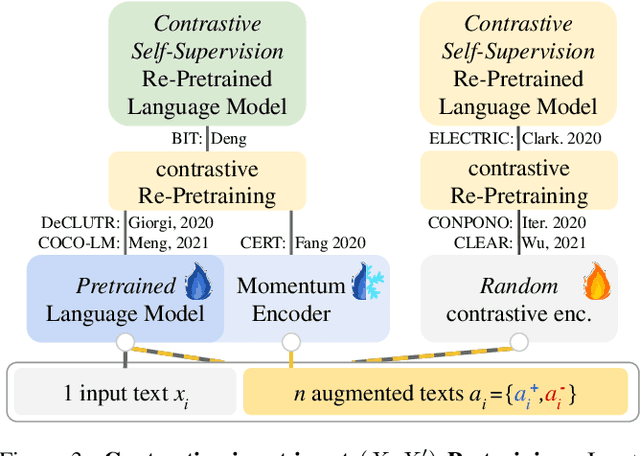
Modern natural language processing (NLP) methods employ self-supervised pretraining objectives such as masked language modeling to boost the performance of various application tasks. These pretraining methods are frequently extended with recurrence, adversarial or linguistic property masking, and more recently with contrastive learning objectives. Contrastive self-supervised training objectives enabled recent successes in image representation pretraining by learning to contrast input-input pairs of augmented images as either similar or dissimilar. However, in NLP, automated creation of text input augmentations is still very challenging because a single token can invert the meaning of a sentence. For this reason, some contrastive NLP pretraining methods contrast over input-label pairs, rather than over input-input pairs, using methods from Metric Learning and Energy Based Models. In this survey, we summarize recent self-supervised and supervised contrastive NLP pretraining methods and describe where they are used to improve language modeling, few or zero-shot learning, pretraining data-efficiency and specific NLP end-tasks. We introduce key contrastive learning concepts with lessons learned from prior research and structure works by applications and cross-field relations. Finally, we point to open challenges and future directions for contrastive NLP to encourage bringing contrastive NLP pretraining closer to recent successes in image representation pretraining.
Disembodied Machine Learning: On the Illusion of Objectivity in NLP
Jan 28, 2021Machine Learning seeks to identify and encode bodies of knowledge within provided datasets. However, data encodes subjective content, which determines the possible outcomes of the models trained on it. Because such subjectivity enables marginalisation of parts of society, it is termed (social) `bias' and sought to be removed. In this paper, we contextualise this discourse of bias in the ML community against the subjective choices in the development process. Through a consideration of how choices in data and model development construct subjectivity, or biases that are represented in a model, we argue that addressing and mitigating biases is near-impossible. This is because both data and ML models are objects for which meaning is made in each step of the development pipeline, from data selection over annotation to model training and analysis. Accordingly, we find the prevalent discourse of bias limiting in its ability to address social marginalisation. We recommend to be conscientious of this, and to accept that de-biasing methods only correct for a fraction of biases.
Does Typological Blinding Impede Cross-Lingual Sharing?
Jan 28, 2021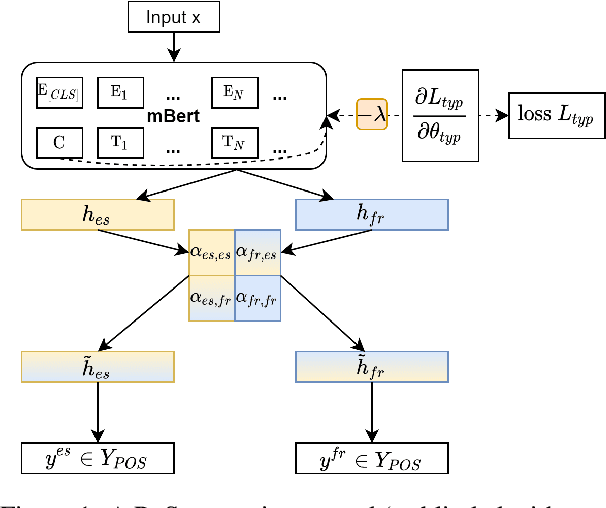
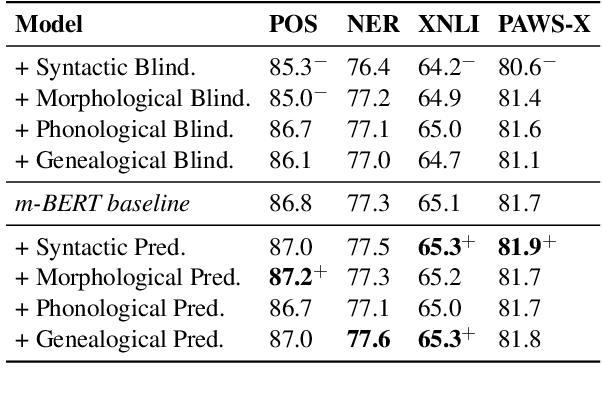
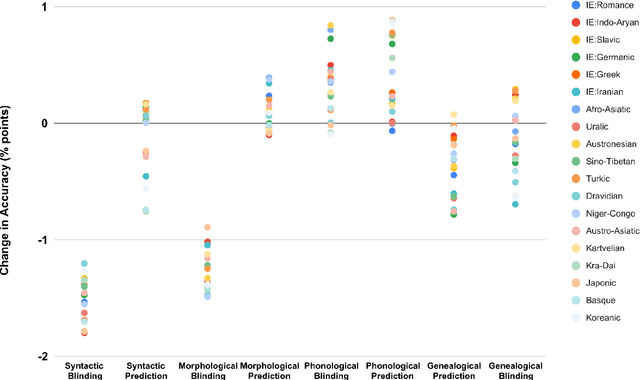
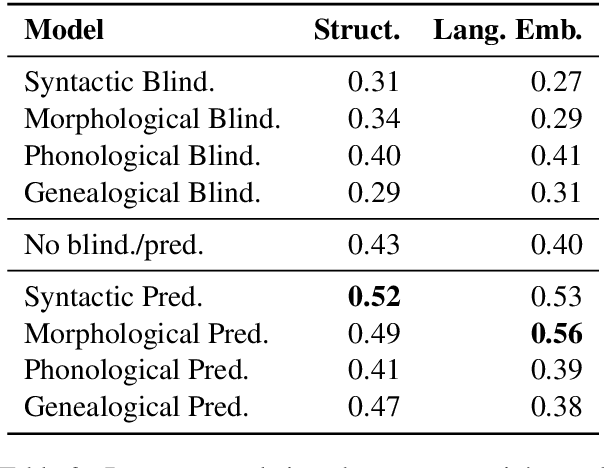
Bridging the performance gap between high- and low-resource languages has been the focus of much previous work. Typological features from databases such as the World Atlas of Language Structures (WALS) are a prime candidate for this, as such data exists even for very low-resource languages. However, previous work has only found minor benefits from using typological information. Our hypothesis is that a model trained in a cross-lingual setting will pick up on typological cues from the input data, thus overshadowing the utility of explicitly using such features. We verify this hypothesis by blinding a model to typological information, and investigate how cross-lingual sharing and performance is impacted. Our model is based on a cross-lingual architecture in which the latent weights governing the sharing between languages is learnt during training. We show that (i) preventing this model from exploiting typology severely reduces performance, while a control experiment reaffirms that (ii) encouraging sharing according to typology somewhat improves performance.