 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Gender Biases Towards Politicians on Reddit
Dec 22, 2021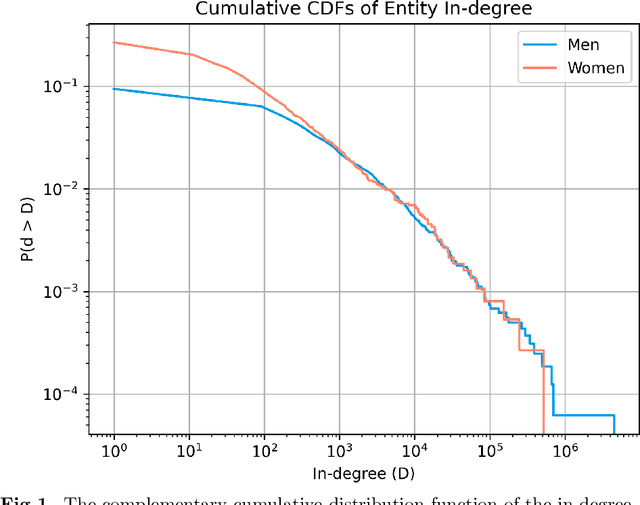
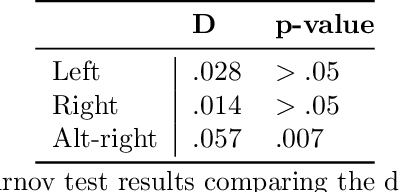
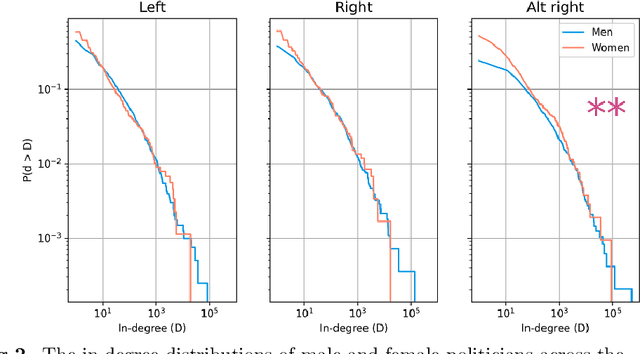
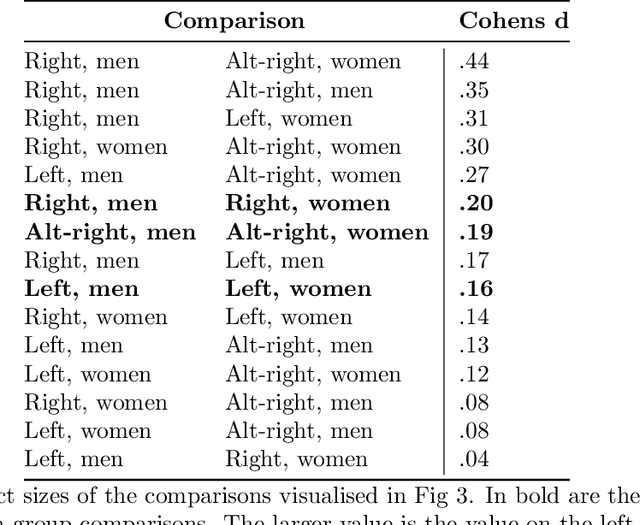
Despite attempts to increase gender parity in politics, global efforts have struggled to ensure equal female representation. This is likely tied to implicit gender biases against women in authority. In this work, we present a comprehensive study of gender biases that appear in online political discussion. To this end, we collect 10 million comments on Reddit in conversations about male and female politicians, which enables an exhaustive study of automatic gender bias detection. We address not only misogynistic language, but also benevolent sexism in the form of seemingly positive attitudes examining both sentiment and dominance attributed to female politicians. Finally, we conduct a multi-faceted study of gender bias towards politicians investigating both linguistic and extra-linguistic cues. We assess 5 different types of gender bias, evaluating coverage, combinatorial, nominal, sentimental and lexical biases extant in social media language and discourse. Overall, we find that, contrary to previous research, coverage and sentiment biases suggest equal public interest in female politicians. However, the results of the nominal and lexical analyses suggest this interest is not as professional or respectful as that expressed about male politicians. Female politicians are often named by their first names and are described in relation to their body, clothing, or family; this is a treatment that is not similarly extended to men. On the now banned far-right subreddits, this disparity is greatest, though differences in gender biases still appear in the right and left-leaning subreddits. We release the curated dataset to the public for future studies.
Generating Fluent Fact Checking Explanations with Unsupervised Post-Editing
Dec 13, 2021
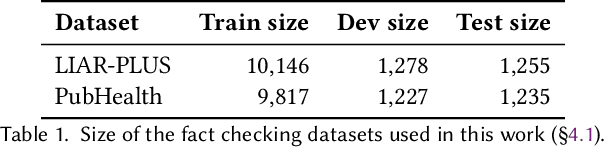
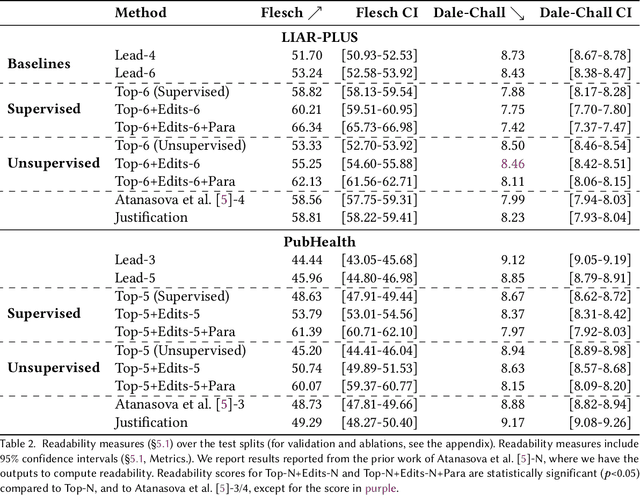
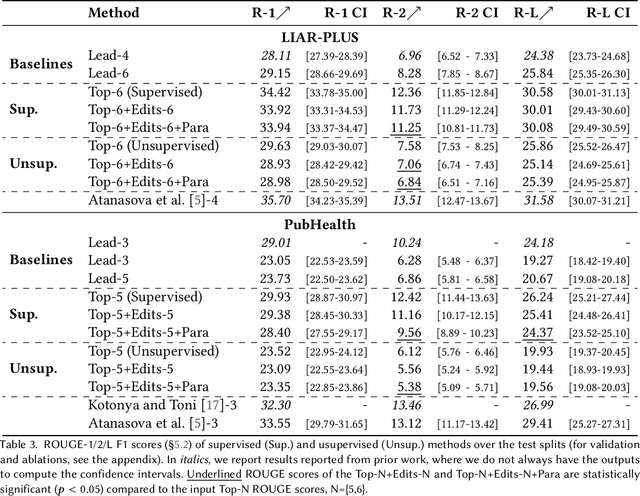
Fact-checking systems have become important tools to verify fake and misguiding news. These systems become more trustworthy when human-readable explanations accompany the veracity labels. However, manual collection of such explanations is expensive and time-consuming. Recent works frame explanation generation as extractive summarization, and propose to automatically select a sufficient subset of the most important facts from the ruling comments (RCs) of a professional journalist to obtain fact-checking explanations. However, these explanations lack fluency and sentence coherence. In this work, we present an iterative edit-based algorithm that uses only phrase-level edits to perform unsupervised post-editing of disconnected RCs. To regulate our editing algorithm, we use a scoring function with components including fluency and semantic preservation. In addition, we show the applicability of our approach in a completely unsupervised setting. We experiment with two benchmark datasets, LIAR-PLUS and PubHealth. We show that our model generates explanations that are fluent, readable, non-redundant, and cover important information for the fact check.
Can Edge Probing Tasks Reveal Linguistic Knowledge in QA Models?
Sep 18, 2021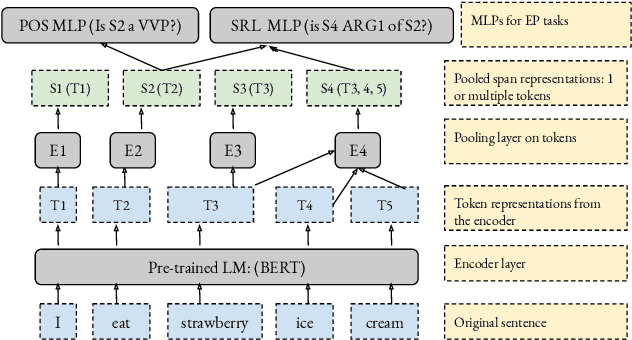
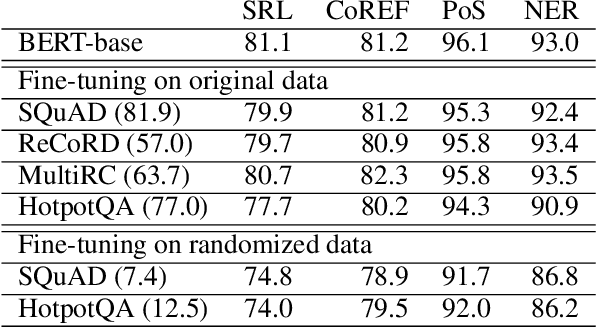
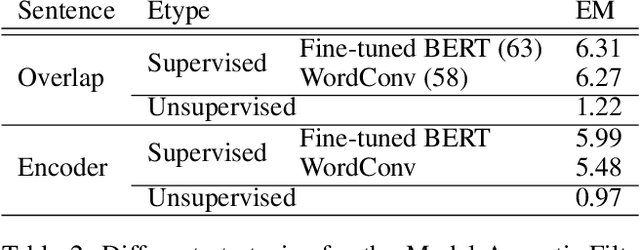
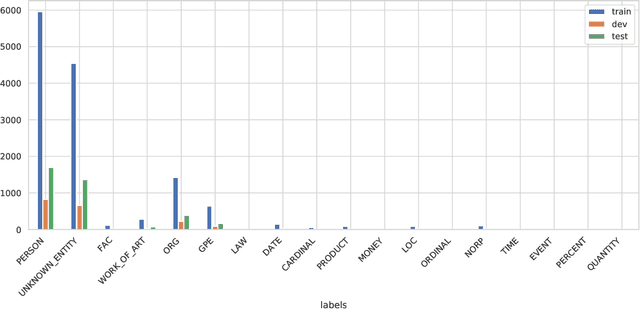
There have been many efforts to try to understand what gram-matical knowledge (e.g., ability to understand the part of speech of a token) is encoded in large pre-trained language models (LM). This is done through 'Edge Probing' (EP) tests: simple ML models that predict the grammatical properties ofa span (whether it has a particular part of speech) using only the LM's token representations. However, most NLP applications use fine-tuned LMs. Here, we ask: if a LM is fine-tuned, does the encoding of linguistic information in it change, as measured by EP tests? Conducting experiments on multiple question-answering (QA) datasets, we answer that question negatively: the EP test results do not change significantly when the fine-tuned QA model performs well or in adversarial situations where the model is forced to learn wrong correlations. However, a critical analysis of the EP task datasets reveals that EP models may rely on spurious correlations to make predictions. This indicates even if fine-tuning changes the encoding of such knowledge, the EP tests might fail to measure it.
Few-Shot Cross-Lingual Stance Detection with Sentiment-Based Pre-Training
Sep 13, 2021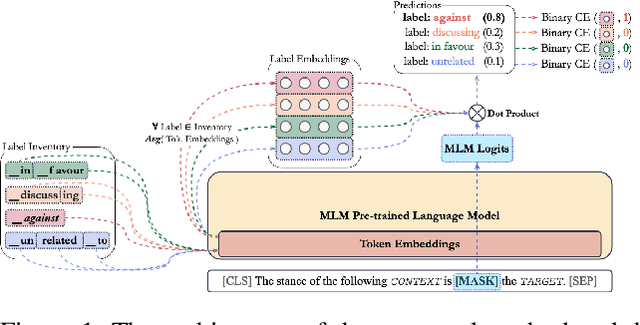
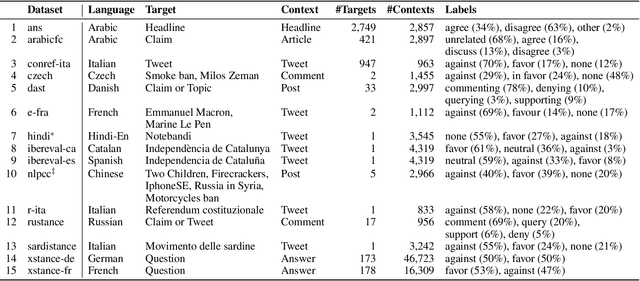
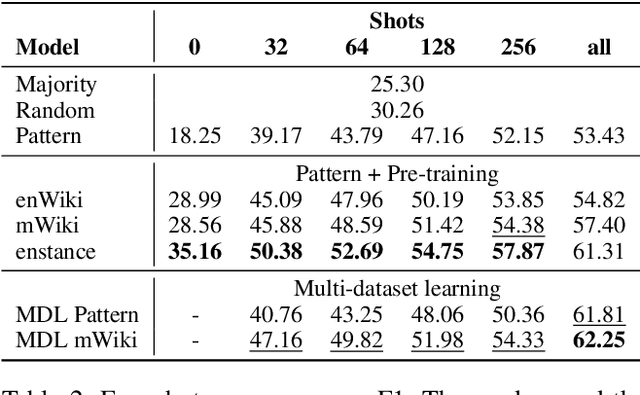
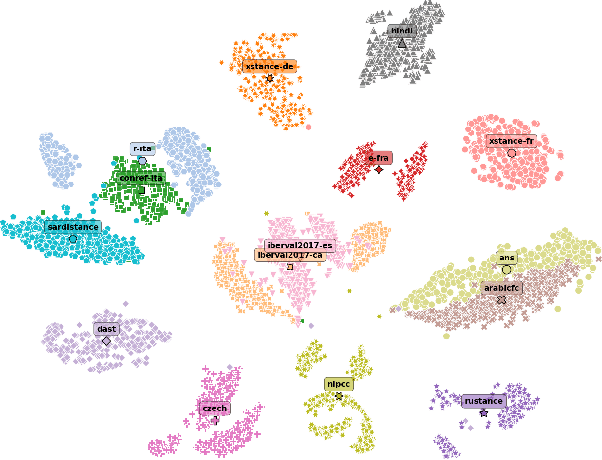
The goal of stance detection is to determine the viewpoint expressed in a piece of text towards a target. These viewpoints or contexts are often expressed in many different languages depending on the user and the platform, which can be a local news outlet, a social media platform, a news forum, etc. Most research in stance detection, however, has been limited to working with a single language and on a few limited targets, with little work on cross-lingual stance detection. Moreover, non-English sources of labelled data are often scarce and present additional challenges. Recently, large multilingual language models have substantially improved the performance on many non-English tasks, especially such with limited numbers of examples. This highlights the importance of model pre-training and its ability to learn from few examples. In this paper, we present the most comprehensive study of cross-lingual stance detection to date: we experiment with 15 diverse datasets in 12 languages from 6 language families, and with 6 low-resource evaluation settings each. For our experiments, we build on pattern-exploiting training, proposing the addition of a novel label encoder to simplify the verbalisation procedure. We further propose sentiment-based generation of stance data for pre-training, which shows sizeable improvement of more than 6% F1 absolute in low-shot settings compared to several strong baselines.
Diagnostics-Guided Explanation Generation
Sep 08, 2021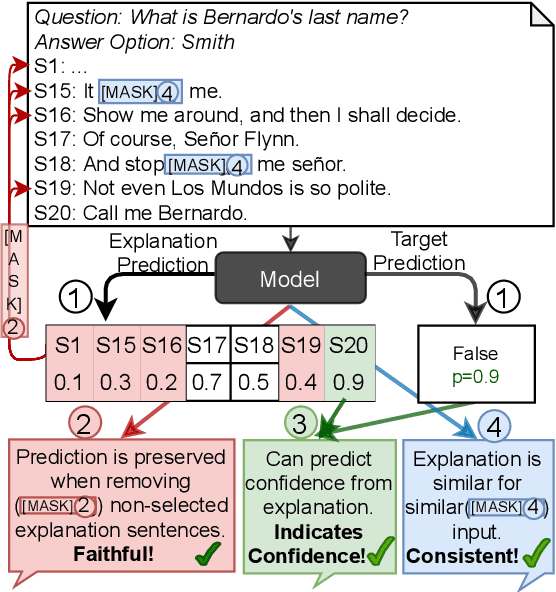
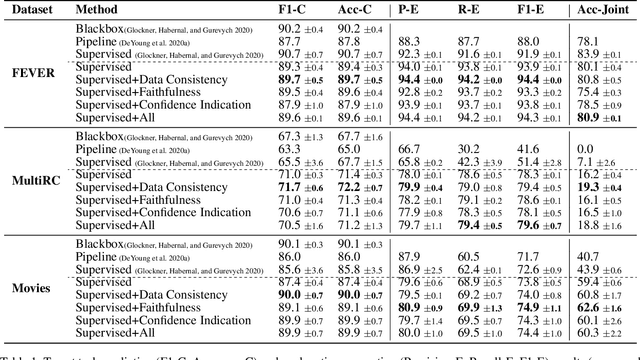
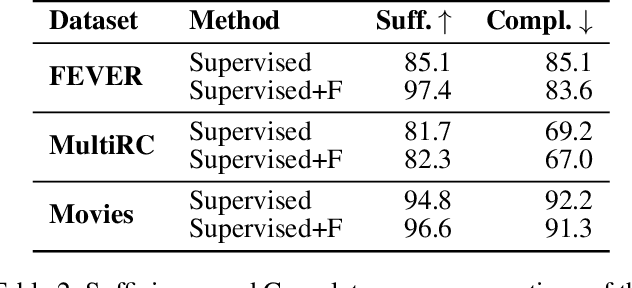
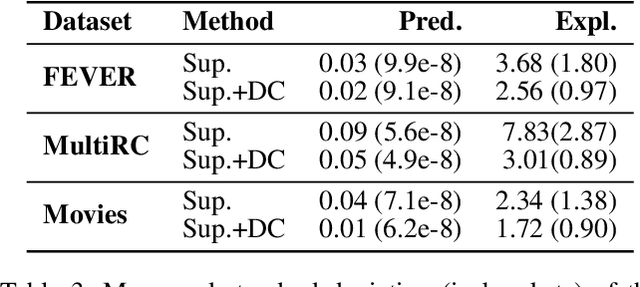
Explanations shed light on a machine learning model's rationales and can aid in identifying deficiencies in its reasoning process. Explanation generation models are typically trained in a supervised way given human explanations. When such annotations are not available, explanations are often selected as those portions of the input that maximise a downstream task's performance, which corresponds to optimising an explanation's Faithfulness to a given model. Faithfulness is one of several so-called diagnostic properties, which prior work has identified as useful for gauging the quality of an explanation without requiring annotations. Other diagnostic properties are Data Consistency, which measures how similar explanations are for similar input instances, and Confidence Indication, which shows whether the explanation reflects the confidence of the model. In this work, we show how to directly optimise for these diagnostic properties when training a model to generate sentence-level explanations, which markedly improves explanation quality, agreement with human rationales, and downstream task performance on three complex reasoning tasks.
Semi-Supervised Exaggeration Detection of Health Science Press Releases
Aug 30, 2021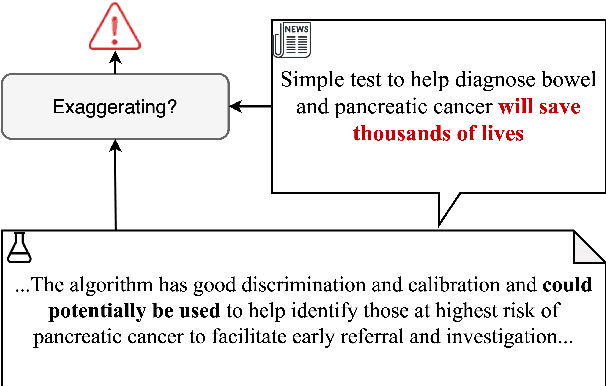
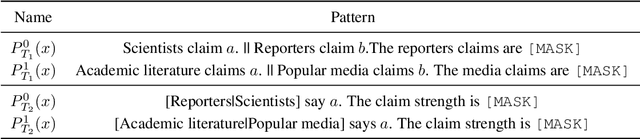
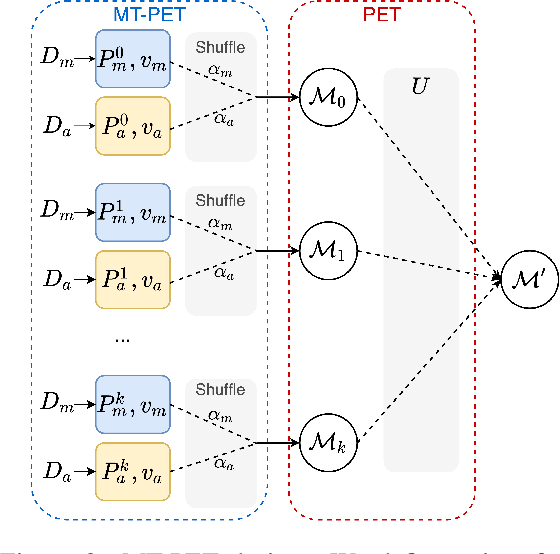
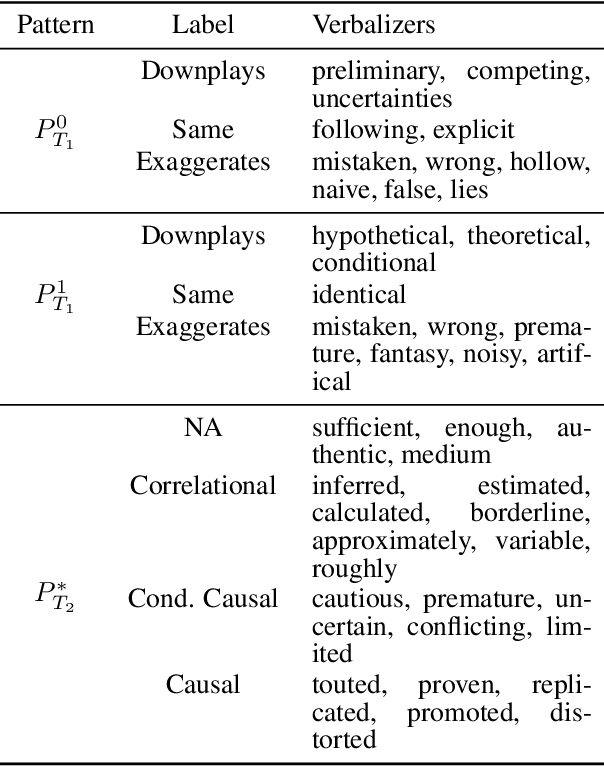
Public trust in science depends on honest and factual communication of scientific papers. However, recent studies have demonstrated a tendency of news media to misrepresent scientific papers by exaggerating their findings. Given this, we present a formalization of and study into the problem of exaggeration detection in science communication. While there are an abundance of scientific papers and popular media articles written about them, very rarely do the articles include a direct link to the original paper, making data collection challenging. We address this by curating a set of labeled press release/abstract pairs from existing expert annotated studies on exaggeration in press releases of scientific papers suitable for benchmarking the performance of machine learning models on the task. Using limited data from this and previous studies on exaggeration detection in science, we introduce MT-PET, a multi-task version of Pattern Exploiting Training (PET), which leverages knowledge from complementary cloze-style QA tasks to improve few-shot learning. We demonstrate that MT-PET outperforms PET and supervised learning both when data is limited, as well as when there is an abundance of data for the main task.
Towards Explainable Fact Checking
Aug 23, 2021The past decade has seen a substantial rise in the amount of mis- and disinformation online, from targeted disinformation campaigns to influence politics, to the unintentional spreading of misinformation about public health. This development has spurred research in the area of automatic fact checking, from approaches to detect check-worthy claims and determining the stance of tweets towards claims, to methods to determine the veracity of claims given evidence documents. These automatic methods are often content-based, using natural language processing methods, which in turn utilise deep neural networks to learn higher-order features from text in order to make predictions. As deep neural networks are black-box models, their inner workings cannot be easily explained. At the same time, it is desirable to explain how they arrive at certain decisions, especially if they are to be used for decision making. While this has been known for some time, the issues this raises have been exacerbated by models increasing in size, and by EU legislation requiring models to be used for decision making to provide explanations, and, very recently, by legislation requiring online platforms operating in the EU to provide transparent reporting on their services. Despite this, current solutions for explainability are still lacking in the area of fact checking. This thesis presents my research on automatic fact checking, including claim check-worthiness detection, stance detection and veracity prediction. Its contributions go beyond fact checking, with the thesis proposing more general machine learning solutions for natural language processing in the area of learning with limited labelled data. Finally, the thesis presents some first solutions for explainable fact checking.
QA Dataset Explosion: A Taxonomy of NLP Resources for Question Answering and Reading Comprehension
Jul 27, 2021


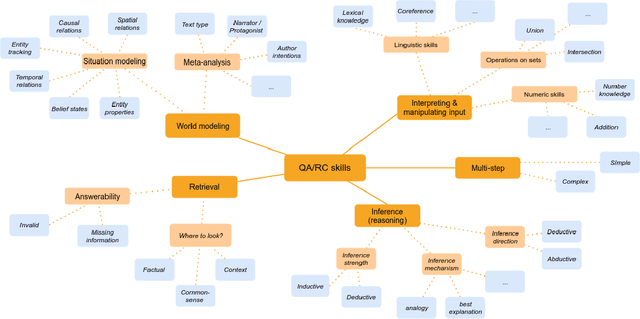
Alongside huge volumes of research on deep learning models in NLP in the recent years, there has been also much work on benchmark datasets needed to track modeling progress. Question answering and reading comprehension have been particularly prolific in this regard, with over 80 new datasets appearing in the past two years. This study is the largest survey of the field to date. We provide an overview of the various formats and domains of the current resources, highlighting the current lacunae for future work. We further discuss the current classifications of ``reasoning types" in question answering and propose a new taxonomy. We also discuss the implications of over-focusing on English, and survey the current monolingual resources for other languages and multilingual resources. The study is aimed at both practitioners looking for pointers to the wealth of existing data, and at researchers working on new resources.
Is Sparse Attention more Interpretable?
Jun 08, 2021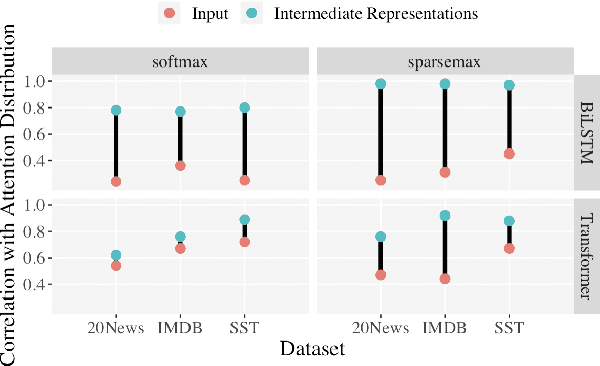
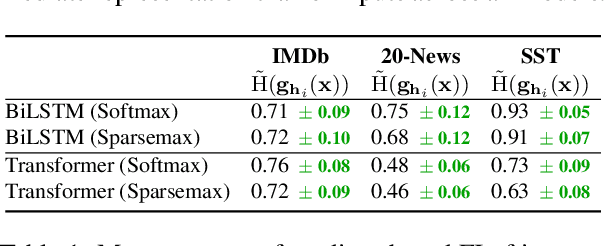
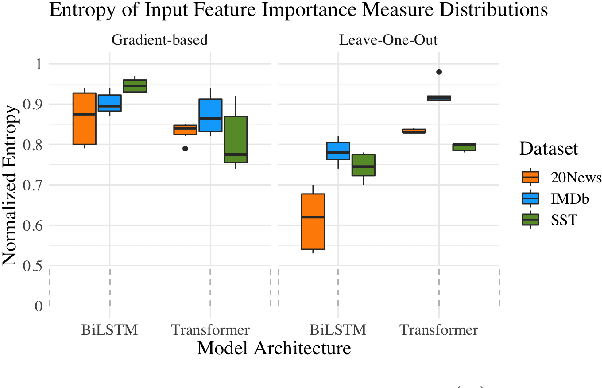
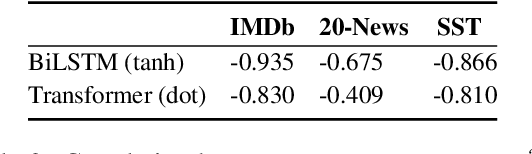
Sparse attention has been claimed to increase model interpretability under the assumption that it highlights influential inputs. Yet the attention distribution is typically over representations internal to the model rather than the inputs themselves, suggesting this assumption may not have merit. We build on the recent work exploring the interpretability of attention; we design a set of experiments to help us understand how sparsity affects our ability to use attention as an explainability tool. On three text classification tasks, we verify that only a weak relationship between inputs and co-indexed intermediate representations exists -- under sparse attention and otherwise. Further, we do not find any plausible mappings from sparse attention distributions to a sparse set of influential inputs through other avenues. Rather, we observe in this setting that inducing sparsity may make it less plausible that attention can be used as a tool for understanding model behavior.
* ACL 2021
Determining the Credibility of Science Communication
May 30, 2021

Most work on scholarly document processing assumes that the information processed is trustworthy and factually correct. However, this is not always the case. There are two core challenges, which should be addressed: 1) ensuring that scientific publications are credible -- e.g. that claims are not made without supporting evidence, and that all relevant supporting evidence is provided; and 2) that scientific findings are not misrepresented, distorted or outright misreported when communicated by journalists or the general public. I will present some first steps towards addressing these problems and outline remaining challenges.