 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Causal Sentence Detection
Jun 20, 2019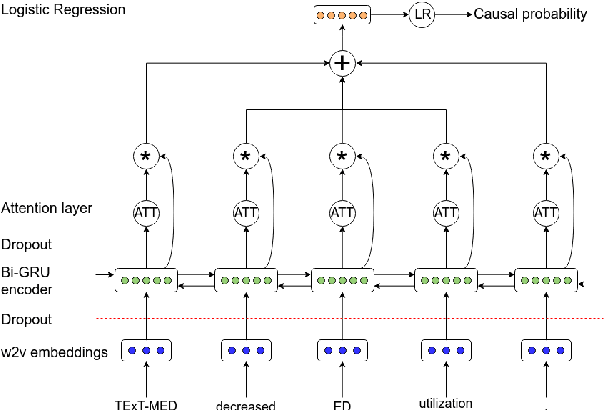
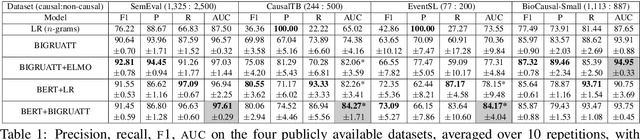
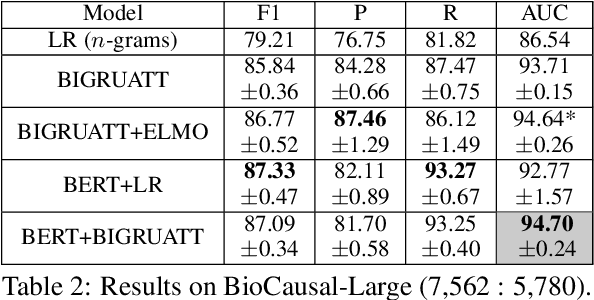
We consider the task of detecting sentences that express causality, as a step towards mining causal relations from texts. To bypass the scarcity of causal instances in relation extraction datasets, we exploit transfer learning, namely ELMO and BERT, using a bidirectional GRU with self-attention (BIGRUATT) as a baseline. We experiment with both generic public relation extraction datasets and a new biomedical causal sentence detection dataset, a subset of which we make publicly available. We find that transfer learning helps only in very small datasets. With larger datasets, BIGRUATT reaches a performance plateau, then larger datasets and transfer learning do not help.
Embedding Biomedical Ontologies by Jointly Encoding Network Structure and Textual Node Descriptors
Jun 20, 2019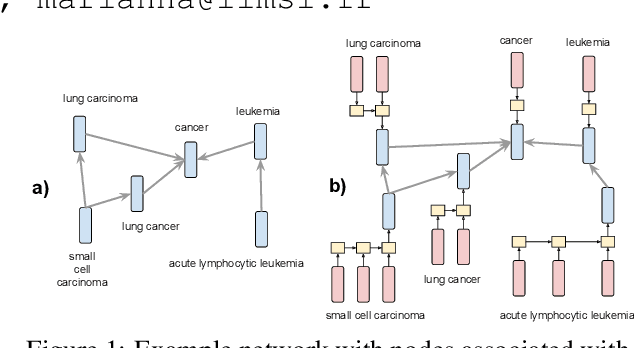
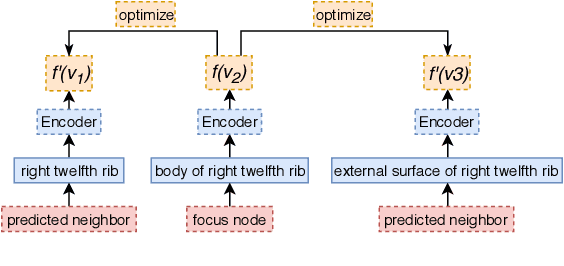
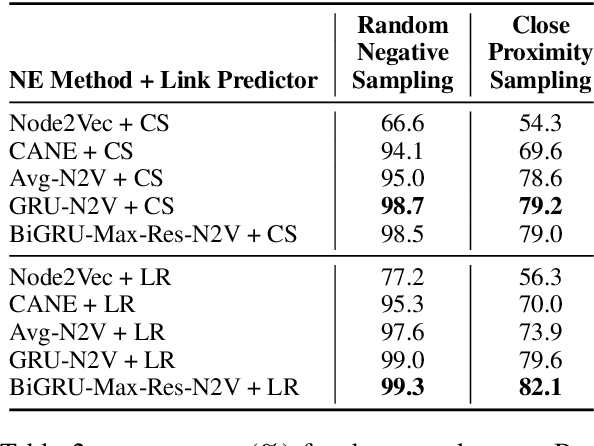
Network Embedding (NE) methods, which map network nodes to low-dimensional feature vectors, have wide applications in network analysis and bioinformatics. Many existing NE methods rely only on network structure, overlooking other information associated with the nodes, e.g., text describing the nodes. Recent attempts to combine the two sources of information only consider local network structure. We extend NODE2VEC, a well-known NE method that considers broader network structure, to also consider textual node descriptors using recurrent neural encoders. Our method is evaluated on link prediction in two networks derived from UMLS. Experimental results demonstrate the effectiveness of the proposed approach compared to previous work.
Neural Legal Judgment Prediction in English
Jun 05, 2019

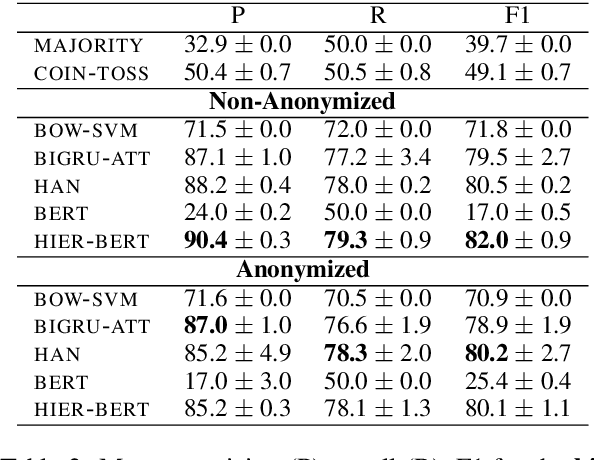
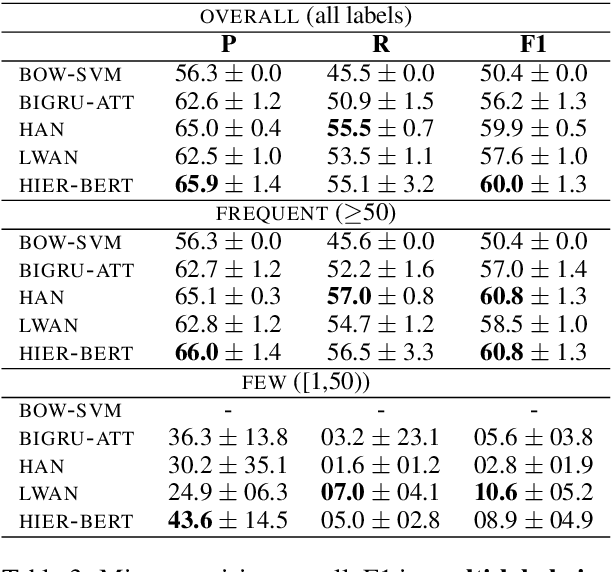
Legal judgment prediction is the task of automatically predicting the outcome of a court case, given a text describing the case's facts. Previous work on using neural models for this task has focused on Chinese; only feature-based models (e.g., using bags of words and topics) have been considered in English. We release a new English legal judgment prediction dataset, containing cases from the European Court of Human Rights. We evaluate a broad variety of neural models on the new dataset, establishing strong baselines that surpass previous feature-based models in three tasks: (1) binary violation classification; (2) multi-label classification; (3) case importance prediction. We also explore if models are biased towards demographic information via data anonymization. As a side-product, we propose a hierarchical version of BERT, which bypasses BERT's length limitation.
Large-Scale Multi-Label Text Classification on EU Legislation
Jun 05, 2019
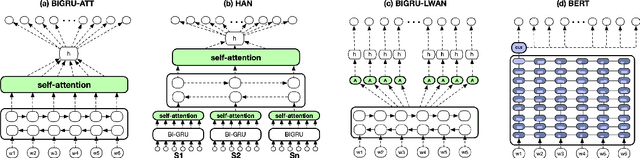
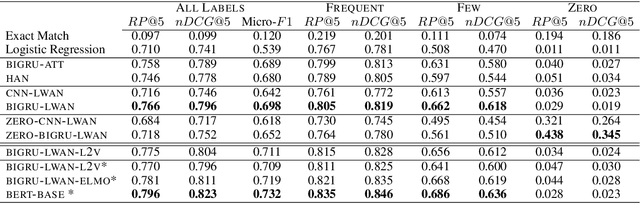
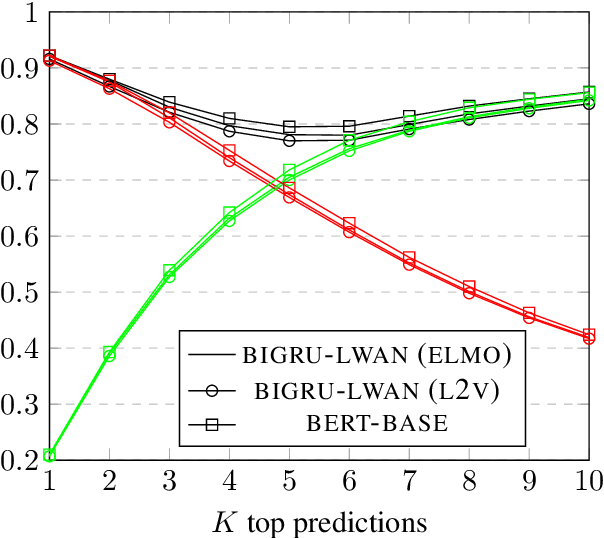
We consider Large-Scale Multi-Label Text Classification (LMTC) in the legal domain. We release a new dataset of 57k legislative documents from EURLEX, annotated with ~4.3k EUROVOC labels, which is suitable for LMTC, few- and zero-shot learning. Experimenting with several neural classifiers, we show that BIGRUs with label-wise attention perform better than other current state of the art methods. Domain-specific WORD2VEC and context-sensitive ELMO embeddings further improve performance. We also find that considering only particular zones of the documents is sufficient. This allows us to bypass BERT's maximum text length limit and fine-tune BERT, obtaining the best results in all but zero-shot learning cases.
Extreme Multi-Label Legal Text Classification: A case study in EU Legislation
May 26, 2019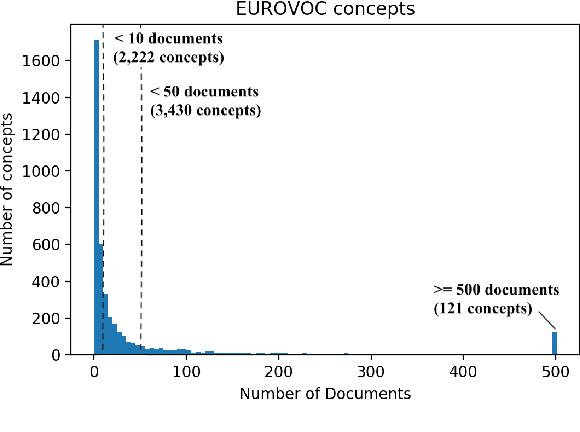

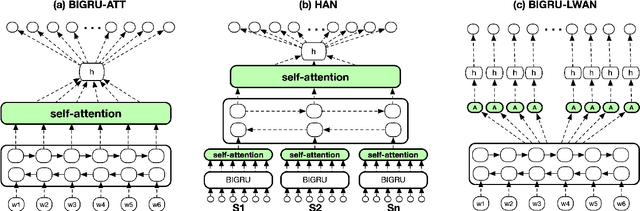
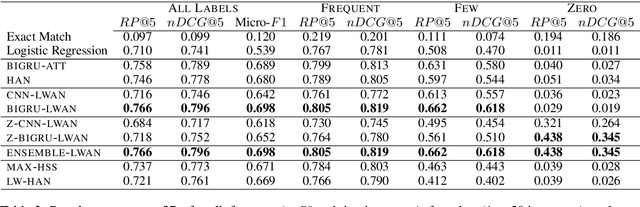
We consider the task of Extreme Multi-Label Text Classification (XMTC) in the legal domain. We release a new dataset of 57k legislative documents from EURLEX, the European Union's public document database, annotated with concepts from EUROVOC, a multidisciplinary thesaurus. The dataset is substantially larger than previous EURLEX datasets and suitable for XMTC, few-shot and zero-shot learning. Experimenting with several neural classifiers, we show that BIGRUs with self-attention outperform the current multi-label state-of-the-art methods, which employ label-wise attention. Replacing CNNs with BIGRUs in label-wise attention networks leads to the best overall performance.
A Survey on Biomedical Image Captioning
May 26, 2019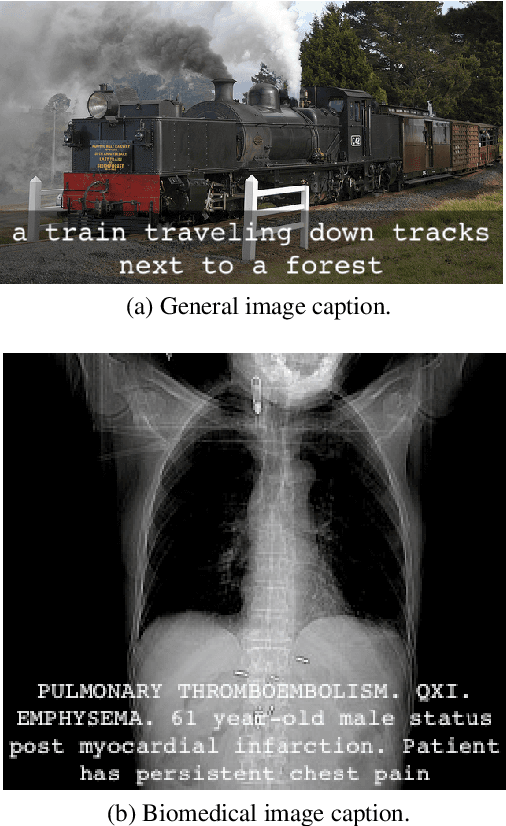
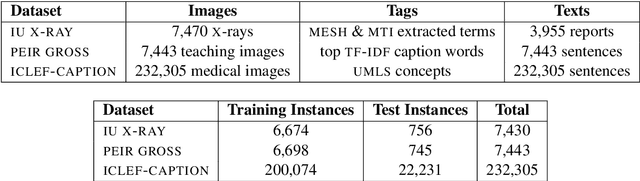
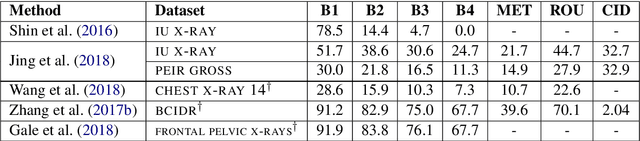
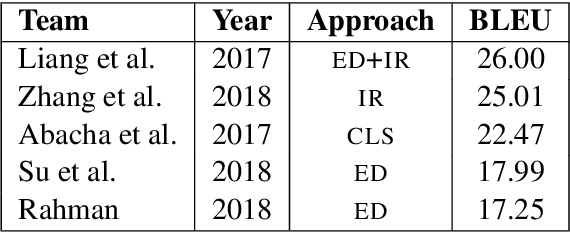
Image captioning applied to biomedical images can assist and accelerate the diagnosis process followed by clinicians. This article is the first survey of biomedical image captioning, discussing datasets, evaluation measures, and state of the art methods. Additionally, we suggest two baselines, a weak and a stronger one; the latter outperforms all current state of the art systems on one of the datasets.
SEQ^3: Differentiable Sequence-to-Sequence-to-Sequence Autoencoder for Unsupervised Abstractive Sentence Compression
Apr 07, 2019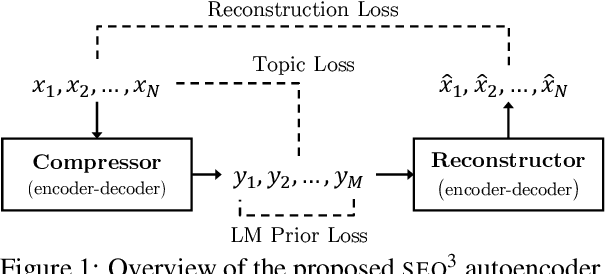

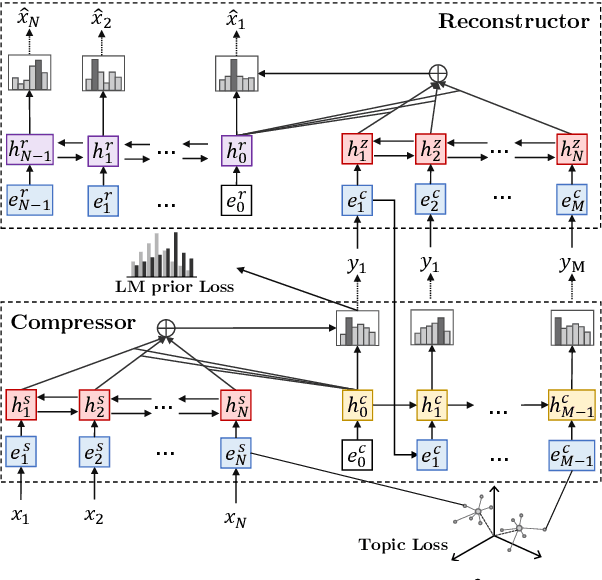
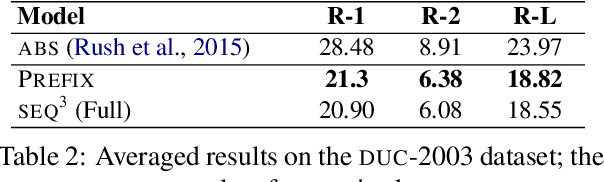
Neural sequence-to-sequence models are currently the dominant approach in several natural language processing tasks, but require large parallel corpora. We present a sequence-to-sequence-to-sequence autoencoder (SEQ^3), consisting of two chained encoder-decoder pairs, with words used as a sequence of discrete latent variables. We apply the proposed model to unsupervised abstractive sentence compression, where the first and last sequences are the input and reconstructed sentences, respectively, while the middle sequence is the compressed sentence. Constraining the length of the latent word sequences forces the model to distill important information from the input. A pretrained language model, acting as a prior over the latent sequences, encourages the compressed sentences to be human-readable. Continuous relaxations enable us to sample from categorical distributions, allowing gradient-based optimization, unlike alternatives that rely on reinforcement learning. The proposed model does not require parallel text-summary pairs, achieving promising results in unsupervised sentence compression on benchmark datasets.
Generating Texts with Integer Linear Programming
Oct 31, 2018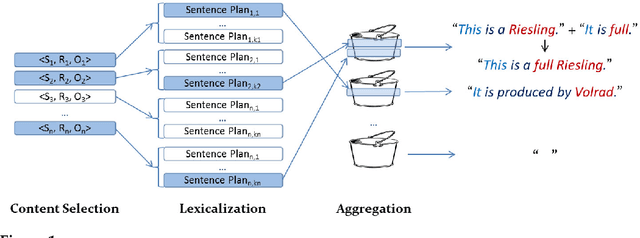

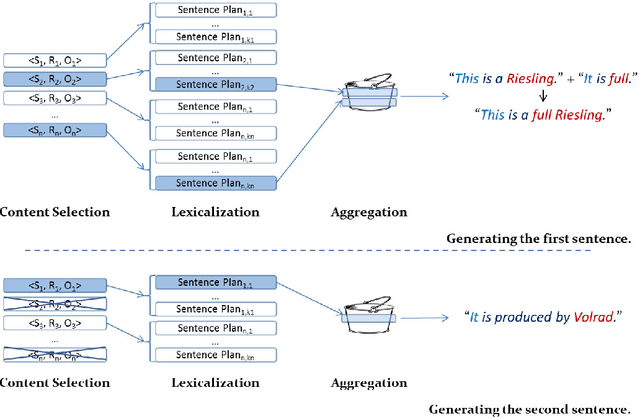

Concept-to-text generation typically employs a pipeline architecture, which often leads to suboptimal texts. Content selection, for example, may greedily select the most important facts, which may require, however, too many words to express, and this may be undesirable when space is limited or expensive. Selecting other facts, possibly only slightly less important, may allow the lexicalization stage to use much fewer words, or to report more facts in the same space. Decisions made during content selection and lexicalization may also lead to more or fewer sentence aggregation opportunities, affecting the length and readability of the resulting texts. Building upon on a publicly available state of the art natural language generator for Semantic Web ontologies, this article presents an Integer Linear Programming model that, unlike pipeline architectures, jointly considers choices available in content selection, lexicalization, and sentence aggregation to avoid greedy local decisions and produce more compact texts, i.e., texts that report more facts per word. Compact texts are desirable, for example, when generating advertisements to be included in Web search results, or when summarizing structured information in limited space. An extended version of the proposed model also considers a limited form of referring expression generation and avoids redundant sentences. An approximation of the two models can be used when longer texts need to be generated. Experiments with three ontologies confirm that the proposed models lead to more compact texts, compared to pipeline systems, with no deterioration or with improvements in the perceived quality of the generated texts.
Extracting Linguistic Resources from the Web for Concept-to-Text Generation
Oct 31, 2018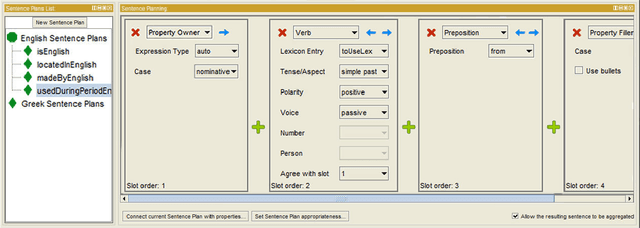

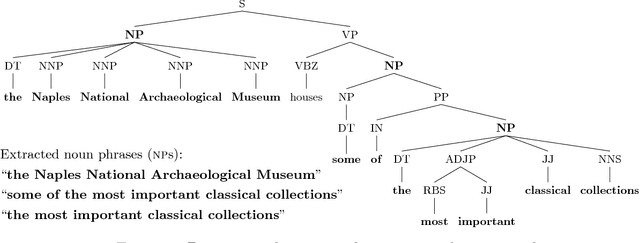
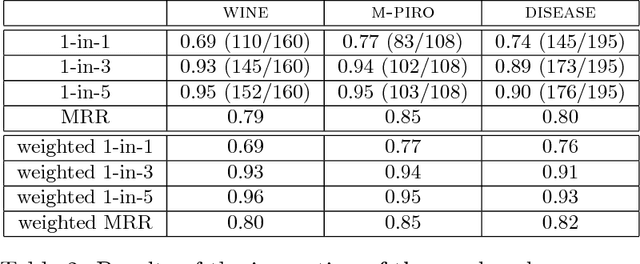
Many concept-to-text generation systems require domain-specific linguistic resources to produce high quality texts, but manually constructing these resources can be tedious and costly. Focusing on NaturalOWL, a publicly available state of the art natural language generator for OWL ontologies, we propose methods to extract from the Web sentence plans and natural language names, two of the most important types of domain-specific linguistic resources used by the generator. Experiments show that texts generated using linguistic resources extracted by our methods in a semi-automatic manner, with minimal human involvement, are perceived as being almost as good as texts generated using manually authored linguistic resources, and much better than texts produced by using linguistic resources extracted from the relation and entity identifiers of the ontology.
AUEB at BioASQ 6: Document and Snippet Retrieval
Sep 15, 2018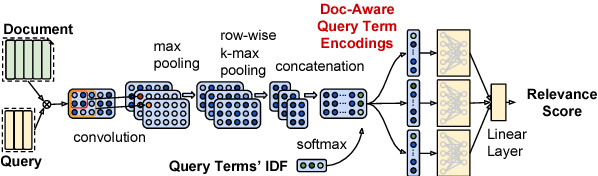
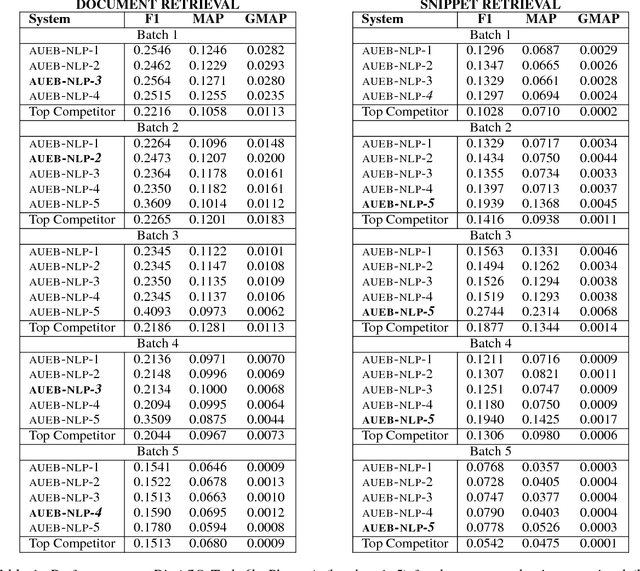
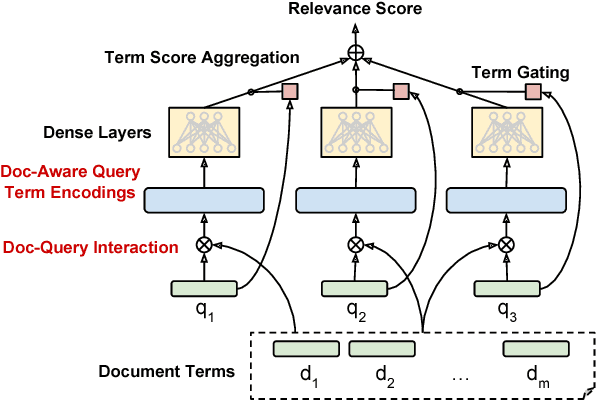
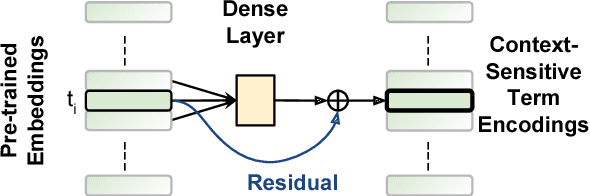
We present AUEB's submissions to the BioASQ 6 document and snippet retrieval tasks (parts of Task 6b, Phase A). Our models use novel extensions to deep learning architectures that operate solely over the text of the query and candidate document/snippets. Our systems scored at the top or near the top for all batches of the challenge, highlighting the effectiveness of deep learning for these tasks.