 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcessing Long Legal Documents with Pre-trained Transformers: Modding LegalBERT and Longformer
Nov 10, 2022



Pre-trained Transformers currently dominate most NLP tasks. They impose, however, limits on the maximum input length (512 sub-words in BERT), which are too restrictive in the legal domain. Even sparse-attention models, such as Longformer and BigBird, which increase the maximum input length to 4,096 sub-words, severely truncate texts in three of the six datasets of LexGLUE. Simpler linear classifiers with TF-IDF features can handle texts of any length, require far less resources to train and deploy, but are usually outperformed by pre-trained Transformers. We explore two directions to cope with long legal texts: (i) modifying a Longformer warm-started from LegalBERT to handle even longer texts (up to 8,192 sub-words), and (ii) modifying LegalBERT to use TF-IDF representations. The first approach is the best in terms of performance, surpassing a hierarchical version of LegalBERT, which was the previous state of the art in LexGLUE. The second approach leads to computationally more efficient models at the expense of lower performance, but the resulting models still outperform overall a linear SVM with TF-IDF features in long legal document classification.
Realistic Zero-Shot Cross-Lingual Transfer in Legal Topic Classification
Jun 08, 2022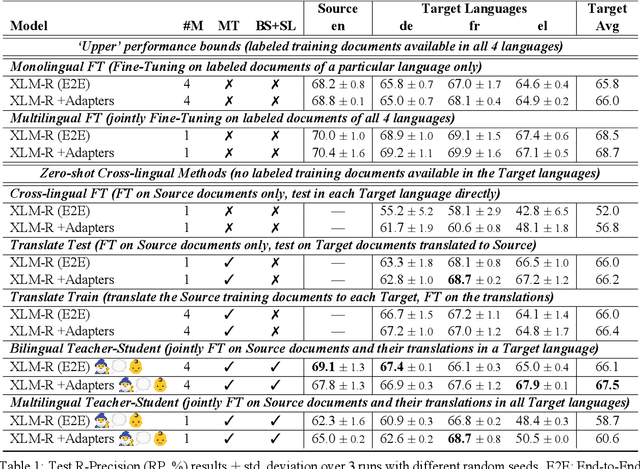
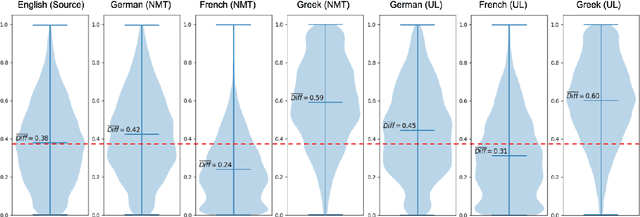
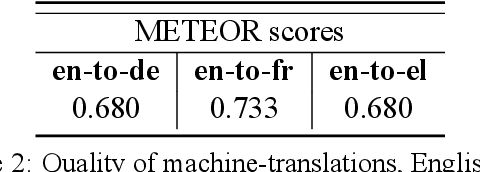
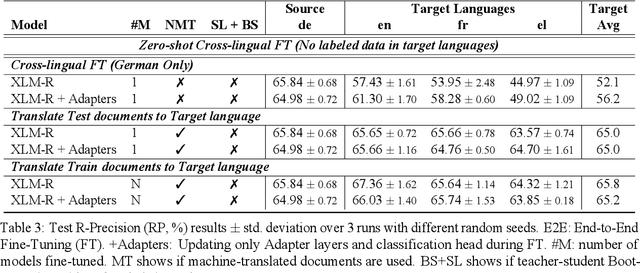
We consider zero-shot cross-lingual transfer in legal topic classification using the recent MultiEURLEX dataset. Since the original dataset contains parallel documents, which is unrealistic for zero-shot cross-lingual transfer, we develop a new version of the dataset without parallel documents. We use it to show that translation-based methods vastly outperform cross-lingual fine-tuning of multilingually pre-trained models, the best previous zero-shot transfer method for MultiEURLEX. We also develop a bilingual teacher-student zero-shot transfer approach, which exploits additional unlabeled documents of the target language and performs better than a model fine-tuned directly on labeled target language documents.
Data Augmentation for Biomedical Factoid Question Answering
Apr 10, 2022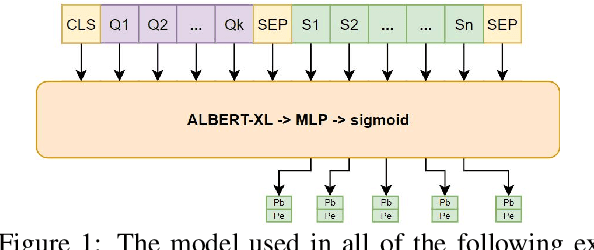

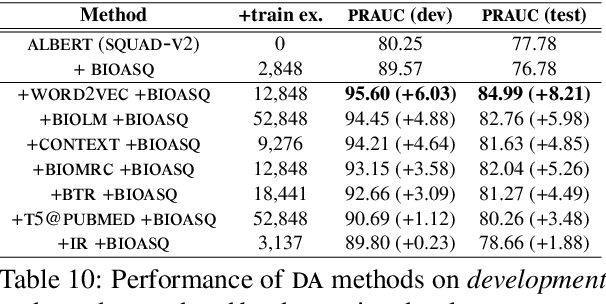

We study the effect of seven data augmentation (da) methods in factoid question answering, focusing on the biomedical domain, where obtaining training instances is particularly difficult. We experiment with data from the BioASQ challenge, which we augment with training instances obtained from an artificial biomedical machine reading comprehension dataset, or via back-translation, information retrieval, word substitution based on word2vec embeddings, or masked language modeling, question generation, or extending the given passage with additional context. We show that da can lead to very significant performance gains, even when using large pre-trained Transformers, contributing to a broader discussion of if/when da benefits large pre-trained models. One of the simplest da methods, word2vec-based word substitution, performed best and is recommended. We release our artificial training instances and code.
FiNER: Financial Numeric Entity Recognition for XBRL Tagging
Mar 12, 2022
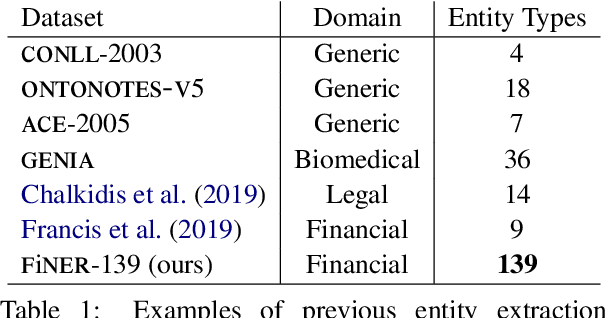
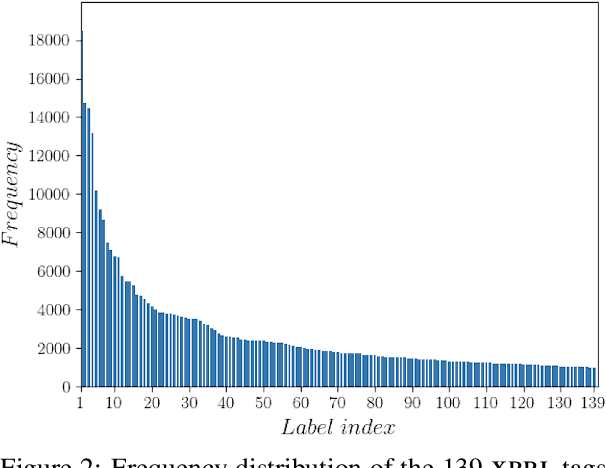
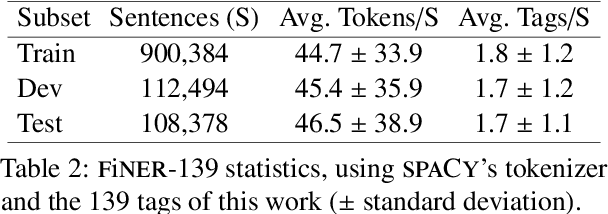
Publicly traded companies are required to submit periodic reports with eXtensive Business Reporting Language (XBRL) word-level tags. Manually tagging the reports is tedious and costly. We, therefore, introduce XBRL tagging as a new entity extraction task for the financial domain and release FiNER-139, a dataset of 1.1M sentences with gold XBRL tags. Unlike typical entity extraction datasets, FiNER-139 uses a much larger label set of 139 entity types. Most annotated tokens are numeric, with the correct tag per token depending mostly on context, rather than the token itself. We show that subword fragmentation of numeric expressions harms BERT's performance, allowing word-level BILSTMs to perform better. To improve BERT's performance, we propose two simple and effective solutions that replace numeric expressions with pseudo-tokens reflecting original token shapes and numeric magnitudes. We also experiment with FIN-BERT, an existing BERT model for the financial domain, and release our own BERT (SEC-BERT), pre-trained on financial filings, which performs best. Through data and error analysis, we finally identify possible limitations to inspire future work on XBRL tagging.
Toxicity Detection can be Sensitive to the Conversational Context
Nov 19, 2021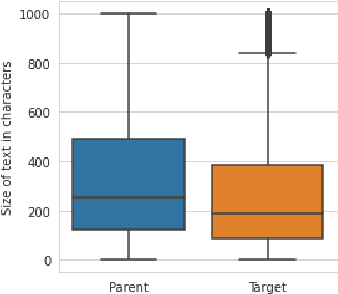

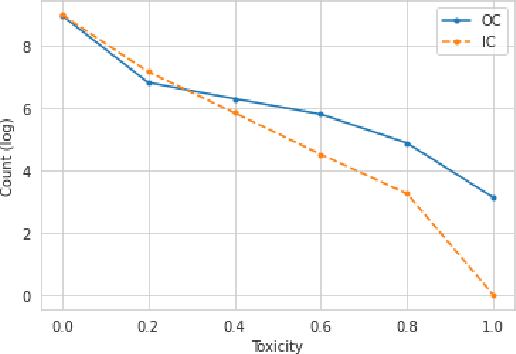
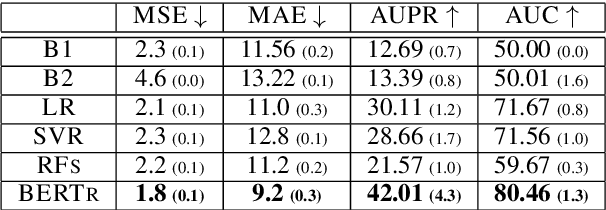
User posts whose perceived toxicity depends on the conversational context are rare in current toxicity detection datasets. Hence, toxicity detectors trained on existing datasets will also tend to disregard context, making the detection of context-sensitive toxicity harder when it does occur. We construct and publicly release a dataset of 10,000 posts with two kinds of toxicity labels: (i) annotators considered each post with the previous one as context; and (ii) annotators had no additional context. Based on this, we introduce a new task, context sensitivity estimation, which aims to identify posts whose perceived toxicity changes if the context (previous post) is also considered. We then evaluate machine learning systems on this task, showing that classifiers of practical quality can be developed, and we show that data augmentation with knowledge distillation can improve the performance further. Such systems could be used to enhance toxicity detection datasets with more context-dependent posts, or to suggest when moderators should consider the parent posts, which often may be unnecessary and may otherwise introduce significant additional cost.
LexGLUE: A Benchmark Dataset for Legal Language Understanding in English
Oct 13, 2021
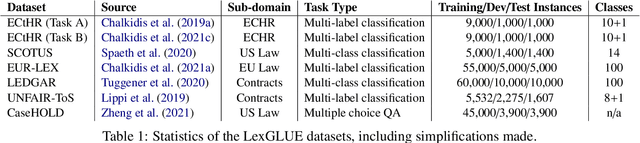

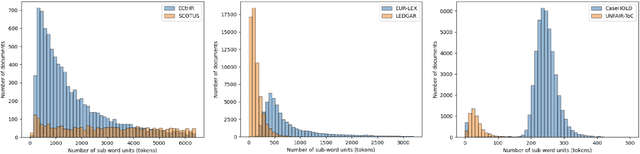
Law, interpretations of law, legal arguments, agreements, etc. are typically expressed in writing, leading to the production of vast corpora of legal text. Their analysis, which is at the center of legal practice, becomes increasingly elaborate as these collections grow in size. Natural language understanding (NLU) technologies can be a valuable tool to support legal practitioners in these endeavors. Their usefulness, however, largely depends on whether current state-of-the-art models can generalize across various tasks in the legal domain. To answer this currently open question, we introduce the Legal General Language Understanding Evaluation (LexGLUE) benchmark, a collection of datasets for evaluating model performance across a diverse set of legal NLU tasks in a standardized way. We also provide an evaluation and analysis of several generic and legal-oriented models demonstrating that the latter consistently offer performance improvements across multiple tasks.
EDGAR-CORPUS: Billions of Tokens Make The World Go Round
Oct 01, 2021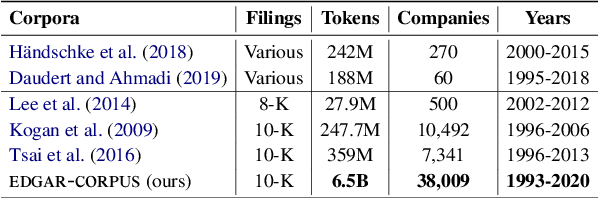



We release EDGAR-CORPUS, a novel corpus comprising annual reports from all the publicly traded companies in the US spanning a period of more than 25 years. To the best of our knowledge, EDGAR-CORPUS is the largest financial NLP corpus available to date. All the reports are downloaded, split into their corresponding items (sections), and provided in a clean, easy-to-use JSON format. We use EDGAR-CORPUS to train and release EDGAR-W2V, which are WORD2VEC embeddings for the financial domain. We employ these embeddings in a battery of financial NLP tasks and showcase their superiority over generic GloVe embeddings and other existing financial word embeddings. We also open-source EDGAR-CRAWLER, a toolkit that facilitates downloading and extracting future annual reports.
MultiEURLEX -- A multi-lingual and multi-label legal document classification dataset for zero-shot cross-lingual transfer
Sep 06, 2021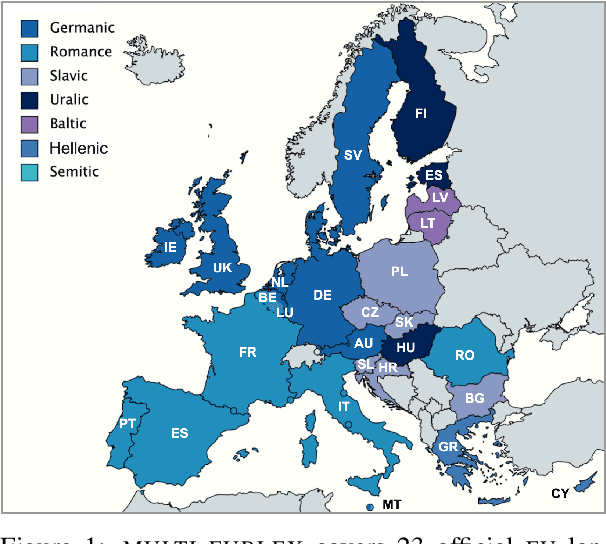
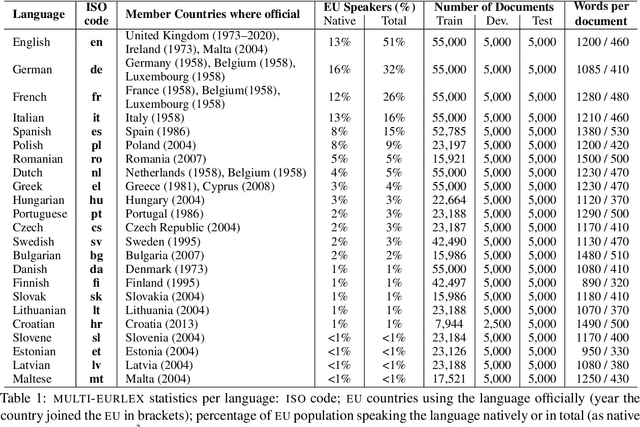
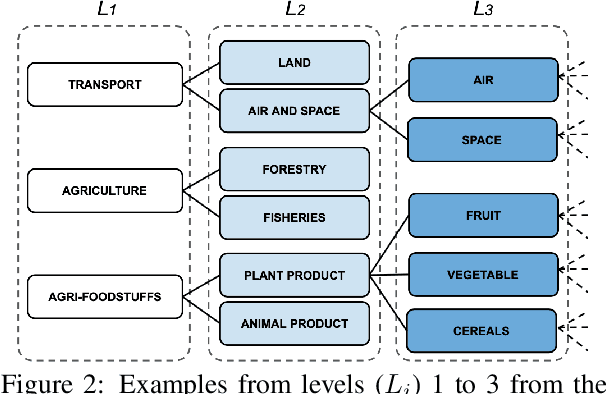
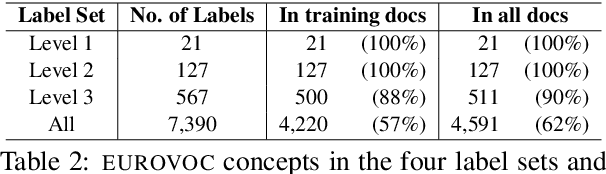
We introduce MULTI-EURLEX, a new multilingual dataset for topic classification of legal documents. The dataset comprises 65k European Union (EU) laws, officially translated in 23 languages, annotated with multiple labels from the EUROVOC taxonomy. We highlight the effect of temporal concept drift and the importance of chronological, instead of random splits. We use the dataset as a testbed for zero-shot cross-lingual transfer, where we exploit annotated training documents in one language (source) to classify documents in another language (target). We find that fine-tuning a multilingually pretrained model (XLM-ROBERTA, MT5) in a single source language leads to catastrophic forgetting of multilingual knowledge and, consequently, poor zero-shot transfer to other languages. Adaptation strategies, namely partial fine-tuning, adapters, BITFIT, LNFIT, originally proposed to accelerate fine-tuning for new end-tasks, help retain multilingual knowledge from pretraining, substantially improving zero-shot cross-lingual transfer, but their impact also depends on the pretrained model used and the size of the label set.
A Neural Model for Joint Document and Snippet Ranking in Question Answering for Large Document Collections
Jun 16, 2021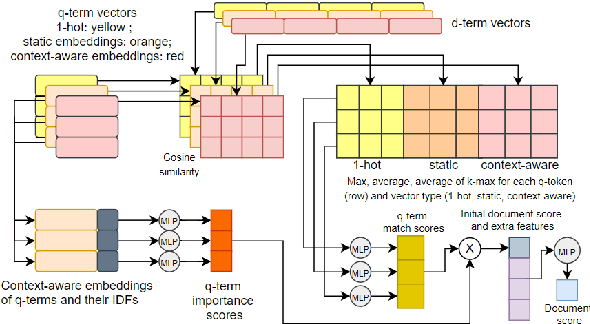
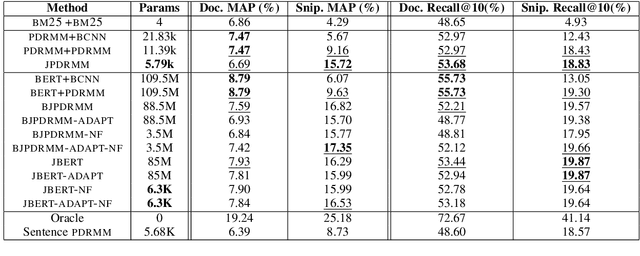
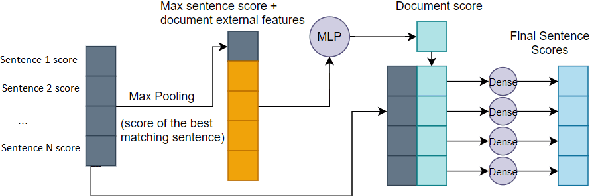

Question answering (QA) systems for large document collections typically use pipelines that (i) retrieve possibly relevant documents, (ii) re-rank them, (iii) rank paragraphs or other snippets of the top-ranked documents, and (iv) select spans of the top-ranked snippets as exact answers. Pipelines are conceptually simple, but errors propagate from one component to the next, without later components being able to revise earlier decisions. We present an architecture for joint document and snippet ranking, the two middle stages, which leverages the intuition that relevant documents have good snippets and good snippets come from relevant documents. The architecture is general and can be used with any neural text relevance ranker. We experiment with two main instantiations of the architecture, based on POSIT-DRMM (PDRMM) and a BERT-based ranker. Experiments on biomedical data from BIOASQ show that our joint models vastly outperform the pipelines in snippet retrieval, the main goal for QA, with fewer trainable parameters, also remaining competitive in document retrieval. Furthermore, our joint PDRMM-based model is competitive with BERT-based models, despite using orders of magnitude fewer parameters. These claims are also supported by human evaluation on two test batches of BIOASQ. To test our key findings on another dataset, we modified the Natural Questions dataset so that it can also be used for document and snippet retrieval. Our joint PDRMM-based model again outperforms the corresponding pipeline in snippet retrieval on the modified Natural Questions dataset, even though it performs worse than the pipeline in document retrieval. We make our code and the modified Natural Questions dataset publicly available.
Deception detection in text and its relation to the cultural dimension of individualism/collectivism
May 26, 2021
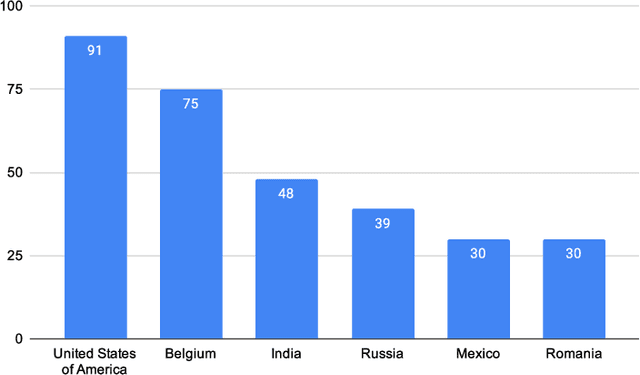


Deception detection is a task with many applications both in direct physical and in computer-mediated communication. Our focus is on automatic deception detection in text across cultures. We view culture through the prism of the individualism/collectivism dimension and we approximate culture by using country as a proxy. Having as a starting point recent conclusions drawn from the social psychology discipline, we explore if differences in the usage of specific linguistic features of deception across cultures can be confirmed and attributed to norms in respect to the individualism/collectivism divide. We also investigate if a universal feature set for cross-cultural text deception detection tasks exists. We evaluate the predictive power of different feature sets and approaches. We create culture/language-aware classifiers by experimenting with a wide range of n-gram features based on phonology, morphology and syntax, other linguistic cues like word and phoneme counts, pronouns use, etc., and token embeddings. We conducted our experiments over 11 datasets from 5 languages i.e., English, Dutch, Russian, Spanish and Romanian, from six countries (US, Belgium, India, Russia, Mexico and Romania), and we applied two classification methods i.e, logistic regression and fine-tuned BERT models. The results showed that our task is fairly complex and demanding. There are indications that some linguistic cues of deception have cultural origins, and are consistent in the context of diverse domains and dataset settings for the same language. This is more evident for the usage of pronouns and the expression of sentiment in deceptive language. The results of this work show that the automatic deception detection across cultures and languages cannot be handled in a unified manner, and that such approaches should be augmented with knowledge about cultural differences and the domains of interest.