 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFE-TAXI: A Hierarchical Multi-UAS Safe Auto-Taxiing Framework with Runtime Safety Assurance and Conflict Resolution
Mar 06, 2025



We present a hierarchical safe auto-taxiing framework to enhance the automated ground operations of multiple unmanned aircraft systems (multi-UAS). The auto-taxiing problem becomes particularly challenging due to (i) unknown disturbances, such as crosswind affecting the aircraft dynamics, (ii) taxiway incursions due to unplanned obstacles, and (iii) spatiotemporal conflicts at the intersections between multiple entry points in the taxiway. To address these issues, we propose a hierarchical framework, i.e., SAFE-TAXI, combining centralized spatiotemporal planning with decentralized MPC-CBF-based control to safely navigate the aircraft through the taxiway while avoiding intersection conflicts and unplanned obstacles (e.g., other aircraft or ground vehicles). Our proposed framework decouples the auto-taxiing problem temporally into conflict resolution and motion planning, respectively. Conflict resolution is handled in a centralized manner by computing conflict-aware reference trajectories for each aircraft. In contrast, safety assurance from unplanned obstacles is handled by an MPC-CBF-based controller implemented in a decentralized manner. We demonstrate the effectiveness of our proposed framework through numerical simulations and experimentally validate it using Night Vapor, a small-scale fixed-wing test platform.
On Enhancing Structural Resilience of Multirobot Coverage Control with Bearing Rigidity
Feb 23, 2025



The problem of multi-robot coverage control has been widely studied to efficiently coordinate a team of robots to cover a desired area of interest. However, this problem faces significant challenges when some robots are lost or deviate from their desired formation during the mission due to faults or cyberattacks. Since a majority of multi-robot systems (MRSs) rely on communication and relative sensing for their efficient operation, a failure in one robot could result in a cascade of failures in the entire system. In this work, we propose a hierarchical framework for area coverage, combining centralized coordination by leveraging Voronoi partitioning with decentralized reference tracking model predictive control (MPC) for control design. In addition to reference tracking, the decentralized MPC also performs bearing maintenance to enforce a rigid MRS network, thereby enhancing the structural resilience, i.e., the ability to detect and mitigate the effects of localization errors and robot loss during the mission. Furthermore, we show that the resulting control architecture guarantees the recovery of the MRS network in the event of robot loss while maintaining a minimally rigid structure. The effectiveness of the proposed algorithm is validated through numerical simulations.
Bridging the Gap between Expert and Language Models: Concept-guided Chess Commentary Generation and Evaluation
Oct 28, 2024



Deep learning-based expert models have reached superhuman performance in decision-making domains such as chess and Go. However, it is under-explored to explain or comment on given decisions although it is important for human education and model explainability. The outputs of expert models are accurate, but yet difficult to interpret for humans. On the other hand, large language models (LLMs) produce fluent commentary but are prone to hallucinations due to their limited decision-making capabilities. To bridge this gap between expert models and LLMs, we focus on chess commentary as a representative case of explaining complex decision-making processes through language and address both the generation and evaluation of commentary. We introduce Concept-guided Chess Commentary generation (CCC) for producing commentary and GPT-based Chess Commentary Evaluation (GCC-Eval) for assessing it. CCC integrates the decision-making strengths of expert models with the linguistic fluency of LLMs through prioritized, concept-based explanations. GCC-Eval leverages expert knowledge to evaluate chess commentary based on informativeness and linguistic quality. Experimental results, validated by both human judges and GCC-Eval, demonstrate that CCC generates commentary that is accurate, informative, and fluent.
An Algorithm for Distributed Computation of Reachable Sets for Multi-Agent Systems
Oct 10, 2024



In this paper, we consider the problem of distributed reachable set computation for multi-agent systems (MASs) interacting over an undirected, stationary graph. A full state-feedback control input for such MASs depends no only on the current agent's state, but also of its neighbors. However, in most MAS applications, the dynamics are obscured by individual agents. This makes reachable set computation, in a fully distributed manner, a challenging problem. We utilize the ideas of polytopic reachable set approximation and generalize it to a MAS setup. We formulate the resulting sub-problems in a fully distributed manner and provide convergence guarantees for the associated computations. The proposed algorithm's convergence is proved for two cases: static MAS graphs, and time-varying graphs under certain restrictions.
Range-based Multi-Robot Integrity Monitoring Against Cyberattacks and Faults: An Anchor-Free Approach
Aug 20, 2024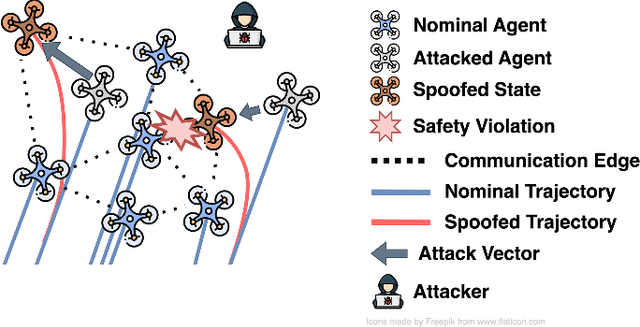
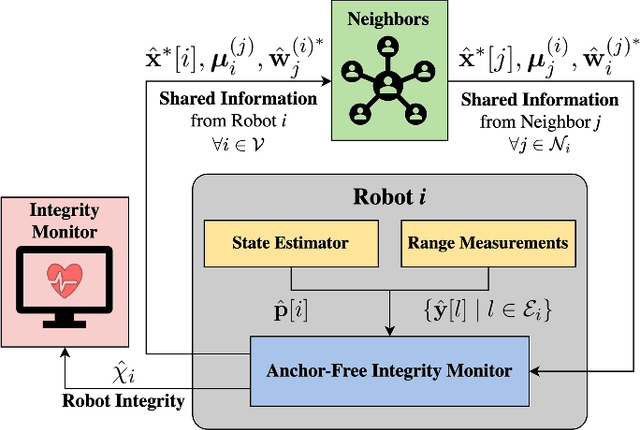
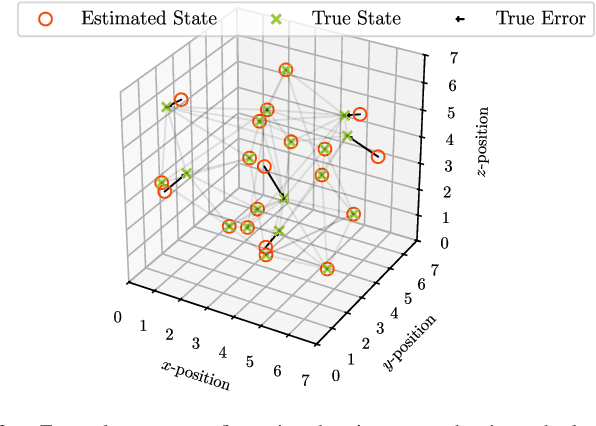
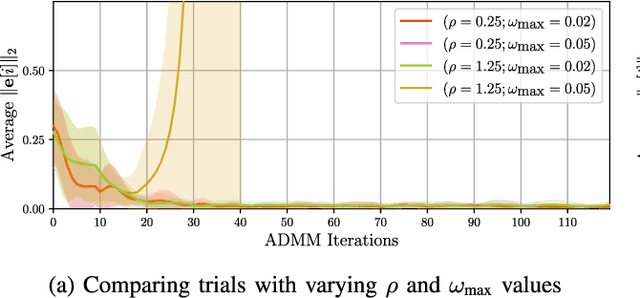
Coordination of multi-robot systems (MRSs) relies on efficient sensing and reliable communication among the robots. However, the sensors and communication channels of these robots are often vulnerable to cyberattacks and faults, which can disrupt their individual behavior and the overall objective of the MRS. In this work, we present a multi-robot integrity monitoring framework that utilizes inter-robot range measurements to (i) detect the presence of cyberattacks or faults affecting the MRS, (ii) identify the affected robot(s), and (iii) reconstruct the resulting localization error of these robot(s). The proposed iterative algorithm leverages sequential convex programming and alternating direction of multipliers method to enable real-time and distributed implementation. Our approach is validated using numerical simulations and demonstrated using PX4-SiTL in Gazebo on an MRS, where certain agents deviate from their desired position due to a GNSS spoofing attack. Furthermore, we demonstrate the scalability and interoperability of our algorithm through mixed-reality experiments by forming a heterogeneous MRS comprising real Crazyflie UAVs and virtual PX4-SiTL UAVs working in tandem.
MIXED-SENSE: A Mixed Reality Sensor Emulation Framework for Test and Evaluation of UAVs Against False Data Injection Attacks
Jul 12, 2024



We present a high-fidelity Mixed Reality sensor emulation framework for testing and evaluating the resilience of Unmanned Aerial Vehicles (UAVs) against false data injection (FDI) attacks. The proposed approach can be utilized to assess the impact of FDI attacks, benchmark attack detector performance, and validate the effectiveness of mitigation/reconfiguration strategies in single-UAV and UAV swarm operations. Our Mixed Reality framework leverages high-fidelity simulations of Gazebo and a Motion Capture system to emulate proprioceptive (e.g., GNSS) and exteroceptive (e.g., camera) sensor measurements in real-time. We propose an empirical approach to faithfully recreate signal characteristics such as latency and noise in these measurements. Finally, we illustrate the efficacy of our proposed framework through a Mixed Reality experiment consisting of an emulated GNSS attack on an actual UAV, which (i) demonstrates the impact of false data injection attacks on GNSS measurements and (ii) validates a mitigation strategy utilizing a distributed camera network developed in our previous work. Our open-source implementation is available at \href{https://github.com/CogniPilot/mixed\_sense}{\texttt{https://github.com/CogniPilot/mixed\_sense}}
Human Behavior Modeling via Identification of Task Objective and Variability
Apr 23, 2024Human behavior modeling is important for the design and implementation of human-automation interactive control systems. In this context, human behavior refers to a human's control input to systems. We propose a novel method for human behavior modeling that uses human demonstrations for a given task to infer the unknown task objective and the variability. The task objective represents the human's intent or desire. It can be inferred by the inverse optimal control and improve the understanding of human behavior by providing an explainable objective function behind the given human behavior. Meanwhile, the variability denotes the intrinsic uncertainty in human behavior. It can be described by a Gaussian mixture model and capture the uncertainty in human behavior which cannot be encoded by the task objective. The proposed method can improve the prediction accuracy of human behavior by leveraging both task objective and variability. The proposed method is demonstrated through human-subject experiments using an illustrative quadrotor remote control example.
Multi-Agent Based Transfer Learning for Data-Driven Air Traffic Applications
Jan 23, 2024Research in developing data-driven models for Air Traffic Management (ATM) has gained a tremendous interest in recent years. However, data-driven models are known to have long training time and require large datasets to achieve good performance. To address the two issues, this paper proposes a Multi-Agent Bidirectional Encoder Representations from Transformers (MA-BERT) model that fully considers the multi-agent characteristic of the ATM system and learns air traffic controllers' decisions, and a pre-training and fine-tuning transfer learning framework. By pre-training the MA-BERT on a large dataset from a major airport and then fine-tuning it to other airports and specific air traffic applications, a large amount of the total training time can be saved. In addition, for newly adopted procedures and constructed airports where no historical data is available, this paper shows that the pre-trained MA-BERT can achieve high performance by updating regularly with little data. The proposed transfer learning framework and MA-BERT are tested with the automatic dependent surveillance-broadcast data recorded in 3 airports in South Korea in 2019.
Collaborative Fault-Identification & Reconstruction in Multi-Agent Systems
Sep 23, 2023The conventional solutions for fault-detection, identification, and reconstruction (FDIR) require centralized decision-making mechanisms which are typically combinatorial in their nature, necessitating the design of an efficient distributed FDIR mechanism that is suitable for multi-agent applications. To this end, we develop a general framework for efficiently reconstructing a sparse vector being observed over a sensor network via nonlinear measurements. The proposed framework is used to design a distributed multi-agent FDIR algorithm based on a combination of the sequential convex programming (SCP) and the alternating direction method of multipliers (ADMM) optimization approaches. The proposed distributed FDIR algorithm can process a variety of inter-agent measurements (including distances, bearings, relative velocities, and subtended angles between agents) to identify the faulty agents and recover their true states. The effectiveness of the proposed distributed multi-agent FDIR approach is demonstrated by considering a numerical example in which the inter-agent distances are used to identify the faulty agents in a multi-agent configuration, as well as reconstruct their error vectors.
Distributed Gaussian Mixture PHD Filtering under Communication Constraints
Aug 01, 2023



The Gaussian Mixture Probability Hypothesis Density (GM-PHD) filter is an almost exact closed-form approximation to the Bayes-optimal multi-target tracking algorithm. Due to its optimality guarantees and ease of implementation, it has been studied extensively in the literature. However, the challenges involved in implementing the GM-PHD filter efficiently in a distributed (multi-sensor) setting have received little attention. The existing solutions for distributed PHD filtering either have a high computational and communication cost, making them infeasible for resource-constrained applications, or are unable to guarantee the asymptotic convergence of the distributed PHD algorithm to an optimal solution. In this paper, we develop a distributed GM-PHD filtering recursion that uses a probabilistic communication rule to limit the communication bandwidth of the algorithm, while ensuring asymptotic optimality of the algorithm. We derive the convergence properties of this recursion, which uses weighted average consensus of Gaussian mixtures (GMs) to lower (and asymptotically minimize) the Cauchy-Schwarz divergence between the sensors' local estimates. In addition, the proposed method is able to avoid the issue of false positives, which has previously been noted to impact the filtering performance of distributed multi-target tracking. Through numerical simulations, it is demonstrated that our proposed method is an effective solution for distributed multi-target tracking in resource-constrained sensor networks.