 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARISTA: A Multi-Task Egocentric Benchmark for Compositional Visual Understanding
May 12, 2026Scene understanding is central to general physical intelligence, and video is a primary modality for capturing both state and temporal dynamics of a scene. Yet understanding physical processes remains difficult, as models must combine object localization, hand-object interactions, relational parsing, temporal reasoning, and step-level procedural inference. Existing benchmarks usually evaluate these capabilities separately, limiting diagnosis of why models fail on procedural tasks. We introduce BARISTA, a densely annotated egocentric dataset and benchmark of 185 real-world coffee-preparation videos covering fully automatic, portafilter-based, and capsule-based workflows. BARISTA provides verified per-frame scene graphs linking persistent object identities to masks, tracks, boxes, attributes, typed relations, hand-object interactions, activities, and process steps. From these graphs, we derive zero-shot language-based tasks spanning phrase grounding, hand-object interaction recognition, referring, activity recognition, relation extraction, and temporal visual question answering. Experiments reveal strong variation across task families and no consistently dominant model family, positioning BARISTA as a challenging diagnostic benchmark for procedural video understanding. Code and dataset available at https://huggingface.co/datasets/ramblr/BARISTA.
Multi-View Brain HyperConnectome AutoEncoder For Brain State Classification
Sep 24, 2020
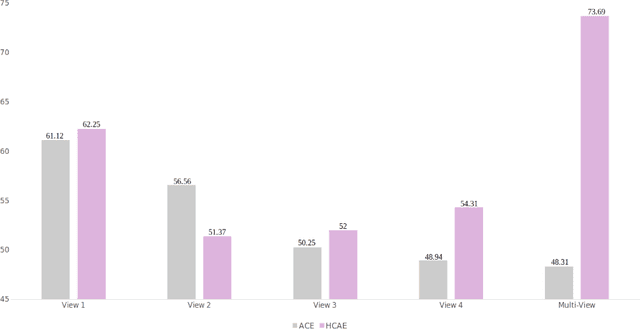

Graph embedding is a powerful method to represent graph neurological data (e.g., brain connectomes) in a low dimensional space for brain connectivity mapping, prediction and classification. However, existing embedding algorithms have two major limitations. First, they primarily focus on preserving one-to-one topological relationships between nodes (i.e., regions of interest (ROIs) in a connectome), but they have mostly ignored many-to-many relationships (i.e., set to set), which can be captured using a hyperconnectome structure. Second, existing graph embedding techniques cannot be easily adapted to multi-view graph data with heterogeneous distributions. In this paper, while cross-pollinating adversarial deep learning with hypergraph theory, we aim to jointly learn deep latent embeddings of subject0specific multi-view brain graphs to eventually disentangle different brain states. First, we propose a new simple strategy to build a hyperconnectome for each brain view based on nearest neighbour algorithm to preserve the connectivities across pairs of ROIs. Second, we design a hyperconnectome autoencoder (HCAE) framework which operates directly on the multi-view hyperconnectomes based on hypergraph convolutional layers to better capture the many-to-many relationships between brain regions (i.e., nodes). For each subject, we further regularize the hypergraph autoencoding by adversarial regularization to align the distribution of the learned hyperconnectome embeddings with that of the input hyperconnectomes. We formalize our hyperconnectome embedding within a geometric deep learning framework to optimize for a given subject, thereby designing an individual-based learning framework. Our experiments showed that the learned embeddings by HCAE yield to better results for brain state classification compared with other deep graph embedding methods methods.