 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBARISTA: A Multi-Task Egocentric Benchmark for Compositional Visual Understanding
May 12, 2026Scene understanding is central to general physical intelligence, and video is a primary modality for capturing both state and temporal dynamics of a scene. Yet understanding physical processes remains difficult, as models must combine object localization, hand-object interactions, relational parsing, temporal reasoning, and step-level procedural inference. Existing benchmarks usually evaluate these capabilities separately, limiting diagnosis of why models fail on procedural tasks. We introduce BARISTA, a densely annotated egocentric dataset and benchmark of 185 real-world coffee-preparation videos covering fully automatic, portafilter-based, and capsule-based workflows. BARISTA provides verified per-frame scene graphs linking persistent object identities to masks, tracks, boxes, attributes, typed relations, hand-object interactions, activities, and process steps. From these graphs, we derive zero-shot language-based tasks spanning phrase grounding, hand-object interaction recognition, referring, activity recognition, relation extraction, and temporal visual question answering. Experiments reveal strong variation across task families and no consistently dominant model family, positioning BARISTA as a challenging diagnostic benchmark for procedural video understanding. Code and dataset available at https://huggingface.co/datasets/ramblr/BARISTA.
Spectral Reconstruction with Deep Neural Networks
May 10, 2019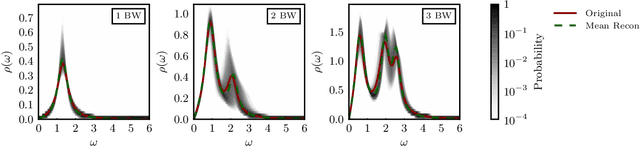
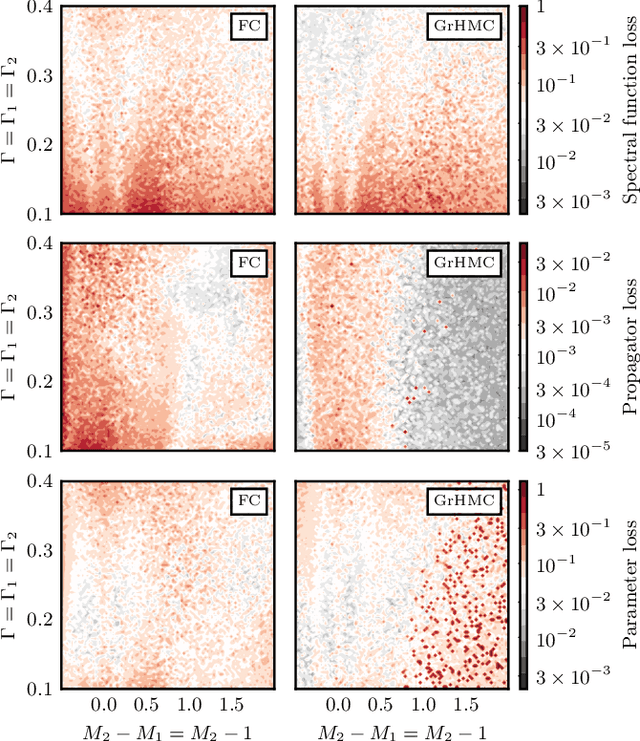
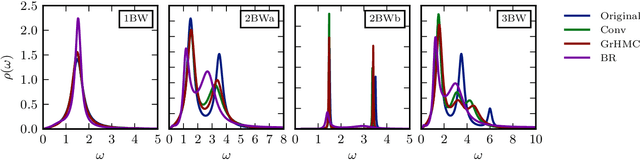
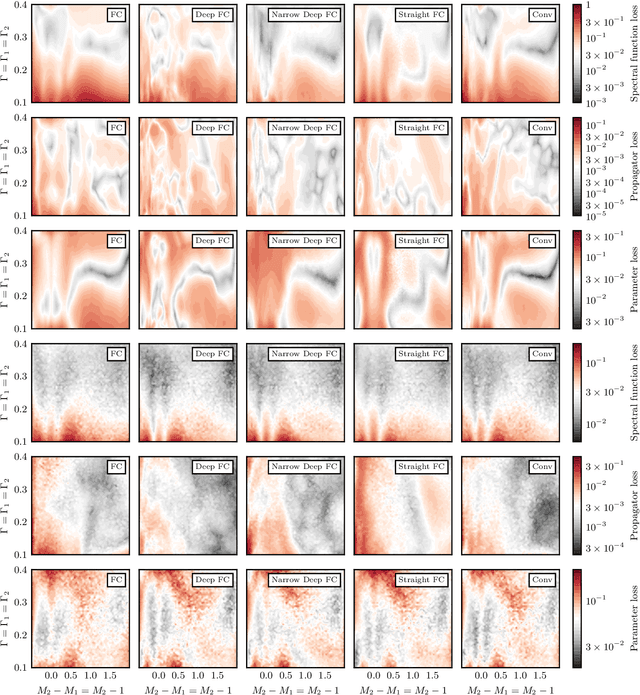
We explore artificial neural networks as a tool for the reconstruction of spectral functions from imaginary time Green's functions, a classic ill-conditioned inverse problem. Our ansatz is based on a supervised learning framework in which prior knowledge is encoded in the training data and the inverse transformation manifold is explicitly parametrised through a neural network. We systematically investigate this novel reconstruction approach, providing a detailed analysis of its performance on physically motivated mock data, and compare it to established methods of Bayesian inference. The reconstruction accuracy is found to be at least comparable, and potentially superior in particular at larger noise levels. We argue that the use of labelled training data in a supervised setting and the freedom in defining an optimisation objective are inherent advantages of the present approach and may lead to significant improvements over state-of-the-art methods in the future. Potential directions for further research are discussed in detail.