 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Driven Diagnosis for Large Cyber-Physical-Systems with Minimal Prior Information
Jun 12, 2025Diagnostic processes for complex cyber-physical systems often require extensive prior knowledge in the form of detailed system models or comprehensive training data. However, obtaining such information poses a significant challenge. To address this issue, we present a new diagnostic approach that operates with minimal prior knowledge, requiring only a basic understanding of subsystem relationships and data from nominal operations. Our method combines a neural network-based symptom generator, which employs subsystem-level anomaly detection, with a new graph diagnosis algorithm that leverages minimal causal relationship information between subsystems-information that is typically available in practice. Our experiments with fully controllable simulated datasets show that our method includes the true causal component in its diagnosis set for 82 p.c. of all cases while effectively reducing the search space in 73 p.c. of the scenarios. Additional tests on the real-world Secure Water Treatment dataset showcase the approach's potential for practical scenarios. Our results thus highlight our approach's potential for practical applications with large and complex cyber-physical systems where limited prior knowledge is available.
On the Relationship Between RNN Hidden State Vectors and Semantic Ground Truth
Jun 29, 2023



We examine the assumption that the hidden-state vectors of recurrent neural networks (RNNs) tend to form clusters of semantically similar vectors, which we dub the clustering hypothesis. While this hypothesis has been assumed in the analysis of RNNs in recent years, its validity has not been studied thoroughly on modern neural network architectures. We examine the clustering hypothesis in the context of RNNs that were trained to recognize regular languages. This enables us to draw on perfect ground-truth automata in our evaluation, against which we can compare the RNN's accuracy and the distribution of the hidden-state vectors. We start with examining the (piecewise linear) separability of an RNN's hidden-state vectors into semantically different classes. We continue the analysis by computing clusters over the hidden-state vector space with multiple state-of-the-art unsupervised clustering approaches. We formally analyze the accuracy of computed clustering functions and the validity of the clustering hypothesis by determining whether clusters group semantically similar vectors to the same state in the ground-truth model. Our evaluation supports the validity of the clustering hypothesis in the majority of examined cases. We observed that the hidden-state vectors of well-trained RNNs are separable, and that the unsupervised clustering techniques succeed in finding clusters of similar state vectors.
Reinforcement Learning under Partial Observability Guided by Learned Environment Models
Jun 23, 2022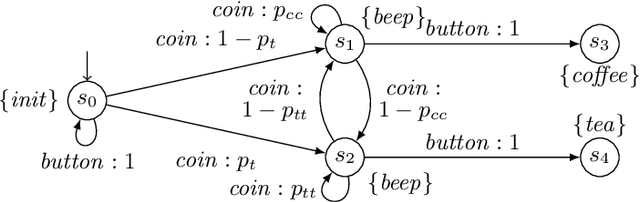
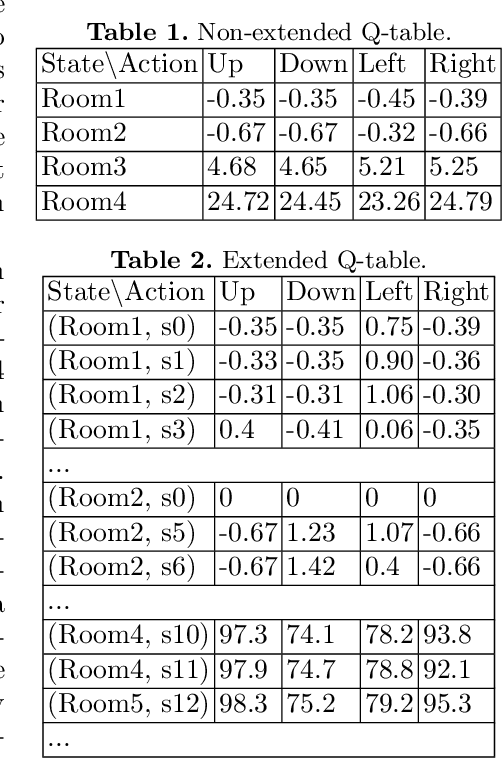
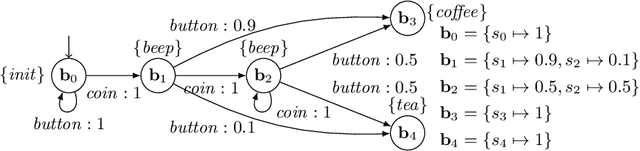
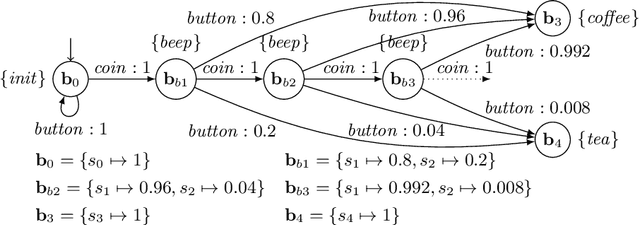
In practical applications, we can rarely assume full observability of a system's environment, despite such knowledge being important for determining a reactive control system's precise interaction with its environment. Therefore, we propose an approach for reinforcement learning (RL) in partially observable environments. While assuming that the environment behaves like a partially observable Markov decision process with known discrete actions, we assume no knowledge about its structure or transition probabilities. Our approach combines Q-learning with IoAlergia, a method for learning Markov decision processes (MDP). By learning MDP models of the environment from episodes of the RL agent, we enable RL in partially observable domains without explicit, additional memory to track previous interactions for dealing with ambiguities stemming from partial observability. We instead provide RL with additional observations in the form of abstract environment states by simulating new experiences on learned environment models to track the explored states. In our evaluation, we report on the validity of our approach and its promising performance in comparison to six state-of-the-art deep RL techniques with recurrent neural networks and fixed memory.