 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Divide-and-Conquer Solver for Kernel Support Vector Machines
Nov 04, 2013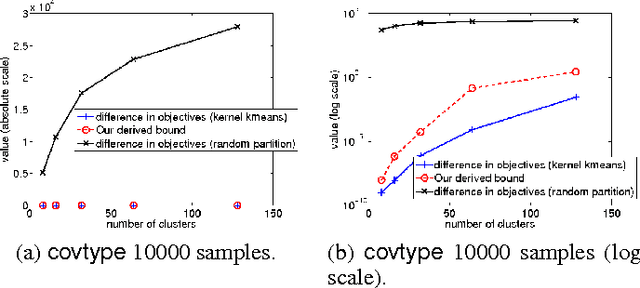
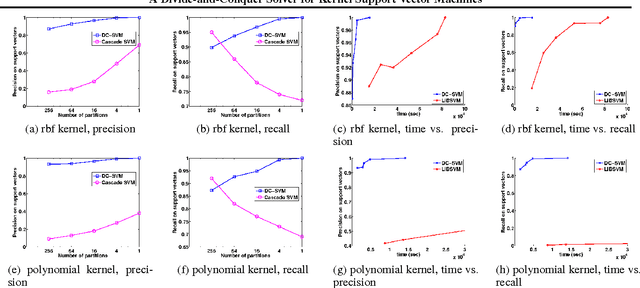
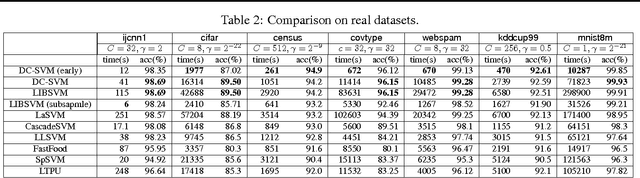

The kernel support vector machine (SVM) is one of the most widely used classification methods; however, the amount of computation required becomes the bottleneck when facing millions of samples. In this paper, we propose and analyze a novel divide-and-conquer solver for kernel SVMs (DC-SVM). In the division step, we partition the kernel SVM problem into smaller subproblems by clustering the data, so that each subproblem can be solved independently and efficiently. We show theoretically that the support vectors identified by the subproblem solution are likely to be support vectors of the entire kernel SVM problem, provided that the problem is partitioned appropriately by kernel clustering. In the conquer step, the local solutions from the subproblems are used to initialize a global coordinate descent solver, which converges quickly as suggested by our analysis. By extending this idea, we develop a multilevel Divide-and-Conquer SVM algorithm with adaptive clustering and early prediction strategy, which outperforms state-of-the-art methods in terms of training speed, testing accuracy, and memory usage. As an example, on the covtype dataset with half-a-million samples, DC-SVM is 7 times faster than LIBSVM in obtaining the exact SVM solution (to within $10^{-6}$ relative error) which achieves 96.15% prediction accuracy. Moreover, with our proposed early prediction strategy, DC-SVM achieves about 96% accuracy in only 12 minutes, which is more than 100 times faster than LIBSVM.
Sparse Inverse Covariance Matrix Estimation Using Quadratic Approximation
Jun 13, 2013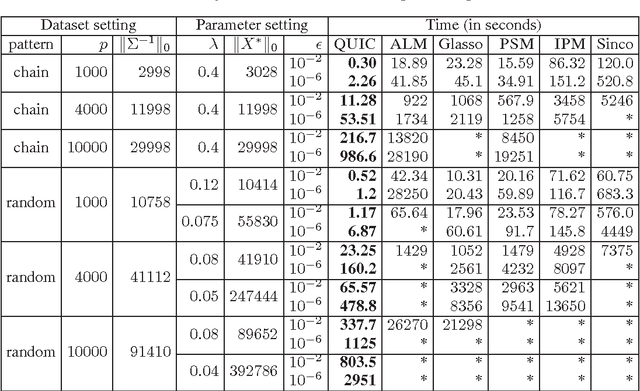
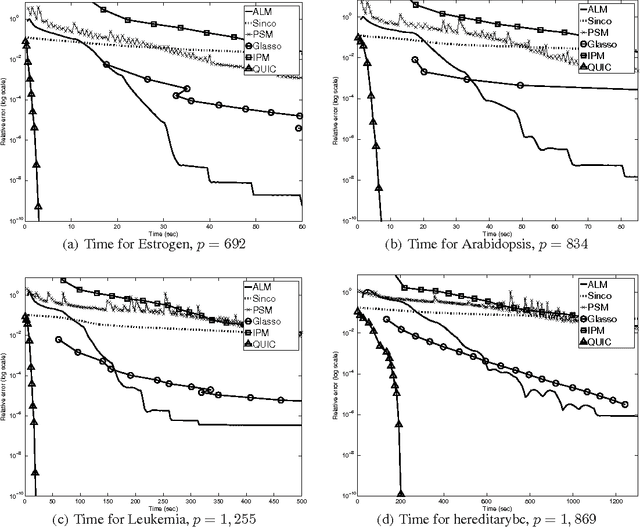
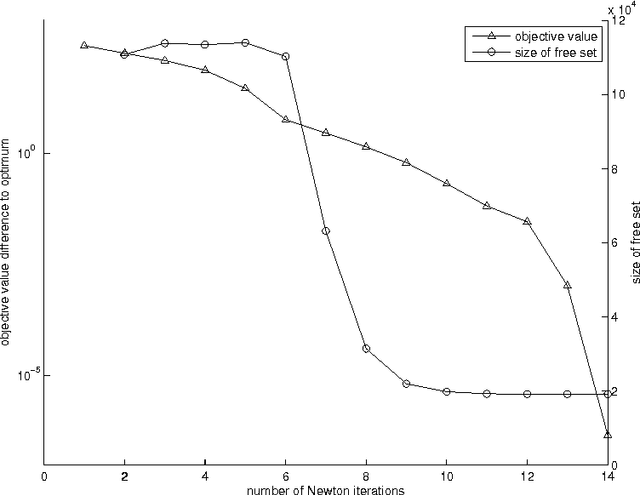
The L1-regularized Gaussian maximum likelihood estimator (MLE) has been shown to have strong statistical guarantees in recovering a sparse inverse covariance matrix, or alternatively the underlying graph structure of a Gaussian Markov Random Field, from very limited samples. We propose a novel algorithm for solving the resulting optimization problem which is a regularized log-determinant program. In contrast to recent state-of-the-art methods that largely use first order gradient information, our algorithm is based on Newton's method and employs a quadratic approximation, but with some modifications that leverage the structure of the sparse Gaussian MLE problem. We show that our method is superlinearly convergent, and present experimental results using synthetic and real-world application data that demonstrate the considerable improvements in performance of our method when compared to other state-of-the-art methods.
Provable Inductive Matrix Completion
Jun 04, 2013
Consider a movie recommendation system where apart from the ratings information, side information such as user's age or movie's genre is also available. Unlike standard matrix completion, in this setting one should be able to predict inductively on new users/movies. In this paper, we study the problem of inductive matrix completion in the exact recovery setting. That is, we assume that the ratings matrix is generated by applying feature vectors to a low-rank matrix and the goal is to recover back the underlying matrix. Furthermore, we generalize the problem to that of low-rank matrix estimation using rank-1 measurements. We study this generic problem and provide conditions that the set of measurements should satisfy so that the alternating minimization method (which otherwise is a non-convex method with no convergence guarantees) is able to recover back the {\em exact} underlying low-rank matrix. In addition to inductive matrix completion, we show that two other low-rank estimation problems can be studied in our framework: a) general low-rank matrix sensing using rank-1 measurements, and b) multi-label regression with missing labels. For both the problems, we provide novel and interesting bounds on the number of measurements required by alternating minimization to provably converges to the {\em exact} low-rank matrix. In particular, our analysis for the general low rank matrix sensing problem significantly improves the required storage and computational cost than that required by the RIP-based matrix sensing methods \cite{RechtFP2007}. Finally, we provide empirical validation of our approach and demonstrate that alternating minimization is able to recover the true matrix for the above mentioned problems using a small number of measurements.
Prediction and Clustering in Signed Networks: A Local to Global Perspective
Mar 05, 2013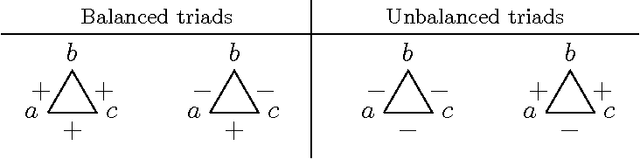
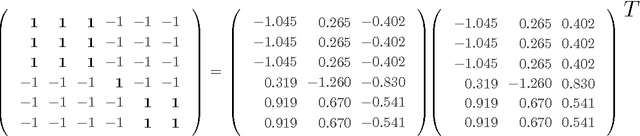

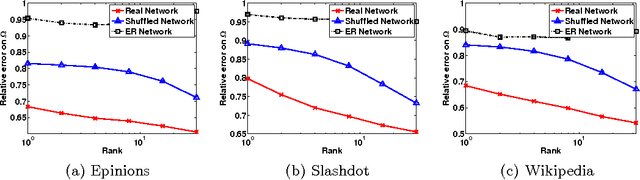
The study of social networks is a burgeoning research area. However, most existing work deals with networks that simply encode whether relationships exist or not. In contrast, relationships in signed networks can be positive ("like", "trust") or negative ("dislike", "distrust"). The theory of social balance shows that signed networks tend to conform to some local patterns that, in turn, induce certain global characteristics. In this paper, we exploit both local as well as global aspects of social balance theory for two fundamental problems in the analysis of signed networks: sign prediction and clustering. Motivated by local patterns of social balance, we first propose two families of sign prediction methods: measures of social imbalance (MOIs), and supervised learning using high order cycles (HOCs). These methods predict signs of edges based on triangles and \ell-cycles for relatively small values of \ell. Interestingly, by examining measures of social imbalance, we show that the classic Katz measure, which is used widely in unsigned link prediction, actually has a balance theoretic interpretation when applied to signed networks. Furthermore, motivated by the global structure of balanced networks, we propose an effective low rank modeling approach for both sign prediction and clustering. For the low rank modeling approach, we provide theoretical performance guarantees via convex relaxations, scale it up to large problem sizes using a matrix factorization based algorithm, and provide extensive experimental validation including comparisons with local approaches. Our experimental results indicate that, by adopting a more global viewpoint of balance structure, we get significant performance and computational gains in prediction and clustering tasks on signed networks. Our work therefore highlights the usefulness of the global aspect of balance theory for the analysis of signed networks.
Orthogonal Matching Pursuit with Replacement
Jun 14, 2011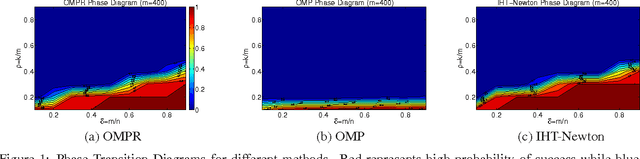
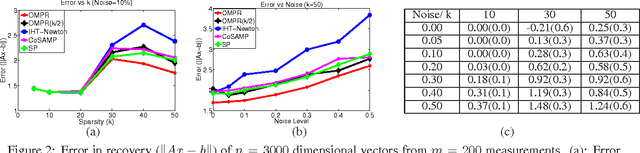
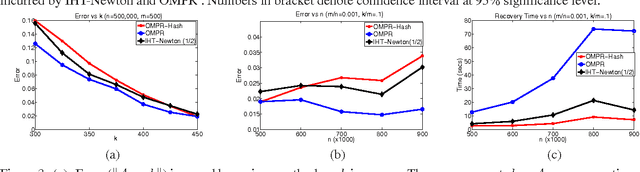
In this paper, we consider the problem of compressed sensing where the goal is to recover almost all the sparse vectors using a small number of fixed linear measurements. For this problem, we propose a novel partial hard-thresholding operator that leads to a general family of iterative algorithms. While one extreme of the family yields well known hard thresholding algorithms like ITI (Iterative Thresholding with Inversion) and HTP (Hard Thresholding Pursuit), the other end of the spectrum leads to a novel algorithm that we call Orthogonal Matching Pursuit with Replacement (OMPR). OMPR, like the classic greedy algorithm OMP, adds exactly one coordinate to the support at each iteration, based on the correlation with the current residual. However, unlike OMP, OMPR also removes one coordinate from the support. This simple change allows us to prove that OMPR has the best known guarantees for sparse recovery in terms of the Restricted Isometry Property (a condition on the measurement matrix). In contrast, OMP is known to have very weak performance guarantees under RIP. Given its simple structure, we are able to extend OMPR using locality sensitive hashing to get OMPR-Hash, the first provably sub-linear (in dimensionality) algorithm for sparse recovery. Our proof techniques are novel and flexible enough to also permit the tightest known analysis of popular iterative algorithms such as CoSaMP and Subspace Pursuit. We provide experimental results on large problems providing recovery for vectors of size up to million dimensions. We demonstrate that for large-scale problems our proposed methods are more robust and faster than existing methods.
Metric and Kernel Learning using a Linear Transformation
Oct 30, 2009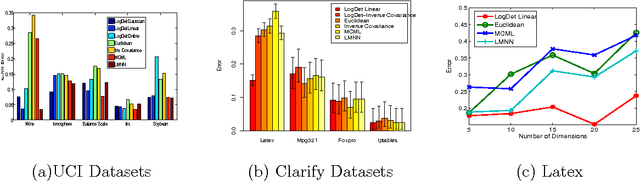

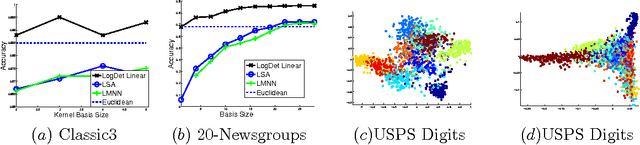
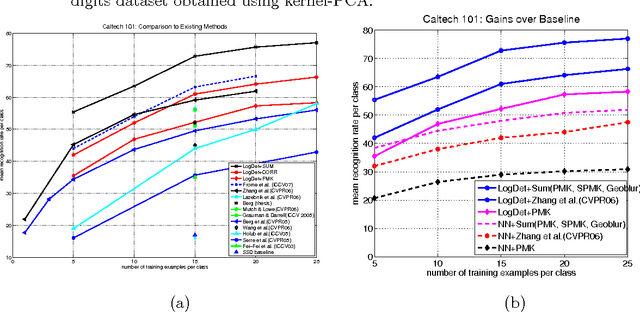
Metric and kernel learning are important in several machine learning applications. However, most existing metric learning algorithms are limited to learning metrics over low-dimensional data, while existing kernel learning algorithms are often limited to the transductive setting and do not generalize to new data points. In this paper, we study metric learning as a problem of learning a linear transformation of the input data. We show that for high-dimensional data, a particular framework for learning a linear transformation of the data based on the LogDet divergence can be efficiently kernelized to learn a metric (or equivalently, a kernel function) over an arbitrarily high dimensional space. We further demonstrate that a wide class of convex loss functions for learning linear transformations can similarly be kernelized, thereby considerably expanding the potential applications of metric learning. We demonstrate our learning approach by applying it to large-scale real world problems in computer vision and text mining.
Guaranteed Rank Minimization via Singular Value Projection
Oct 19, 2009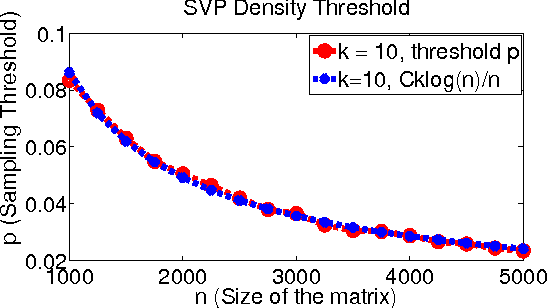
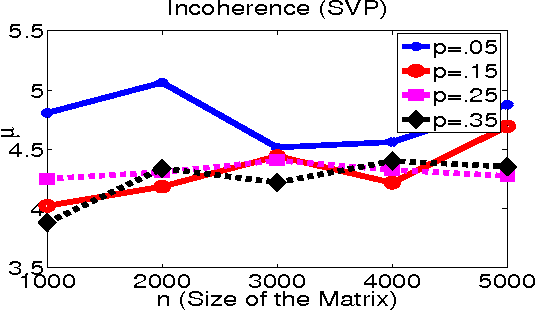
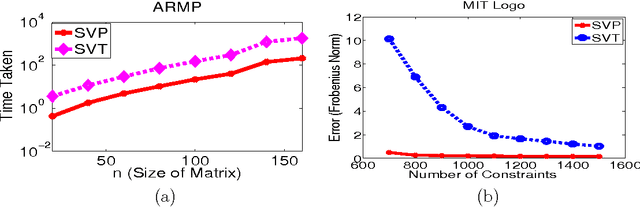
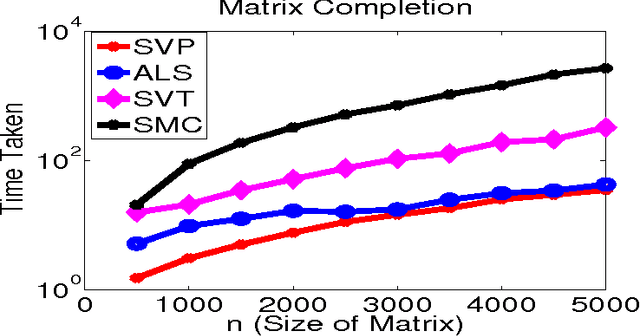
Minimizing the rank of a matrix subject to affine constraints is a fundamental problem with many important applications in machine learning and statistics. In this paper we propose a simple and fast algorithm SVP (Singular Value Projection) for rank minimization with affine constraints (ARMP) and show that SVP recovers the minimum rank solution for affine constraints that satisfy the "restricted isometry property" and show robustness of our method to noise. Our results improve upon a recent breakthrough by Recht, Fazel and Parillo (RFP07) and Lee and Bresler (LB09) in three significant ways: 1) our method (SVP) is significantly simpler to analyze and easier to implement, 2) we give recovery guarantees under strictly weaker isometry assumptions 3) we give geometric convergence guarantees for SVP even in presense of noise and, as demonstrated empirically, SVP is significantly faster on real-world and synthetic problems. In addition, we address the practically important problem of low-rank matrix completion (MCP), which can be seen as a special case of ARMP. We empirically demonstrate that our algorithm recovers low-rank incoherent matrices from an almost optimal number of uniformly sampled entries. We make partial progress towards proving exact recovery and provide some intuition for the strong performance of SVP applied to matrix completion by showing a more restricted isometry property. Our algorithm outperforms existing methods, such as those of \cite{RFP07,CR08,CT09,CCS08,KOM09,LB09}, for ARMP and the matrix-completion problem by an order of magnitude and is also significantly more robust to noise.