 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Transmitting Bits: Context, Semantics, and Task-Oriented Communications
Jul 19, 2022


Communication systems to date primarily aim at reliably communicating bit sequences. Such an approach provides efficient engineering designs that are agnostic to the meanings of the messages or to the goal that the message exchange aims to achieve. Next generation systems, however, can be potentially enriched by folding message semantics and goals of communication into their design. Further, these systems can be made cognizant of the context in which communication exchange takes place, providing avenues for novel design insights. This tutorial summarizes the efforts to date, starting from its early adaptations, semantic-aware and task-oriented communications, covering the foundations, algorithms and potential implementations. The focus is on approaches that utilize information theory to provide the foundations, as well as the significant role of learning in semantics and task-aware communications.
On the Information Bottleneck Problems: Models, Connections, Applications and Information Theoretic Views
Jan 31, 2020
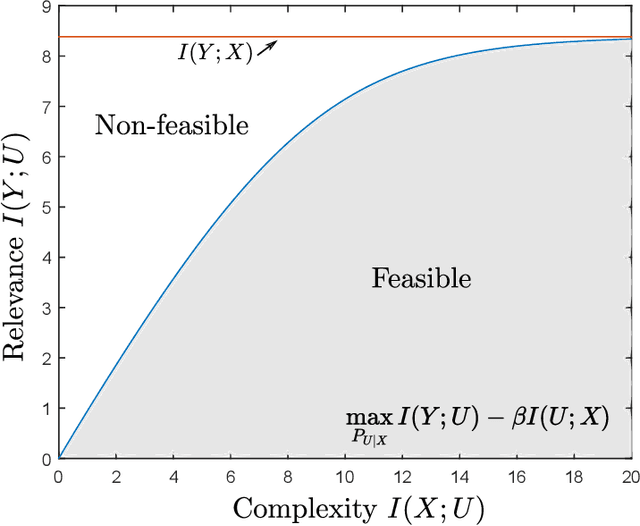
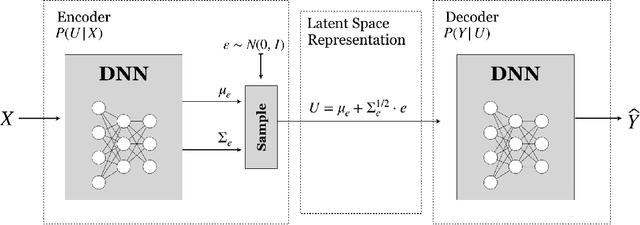

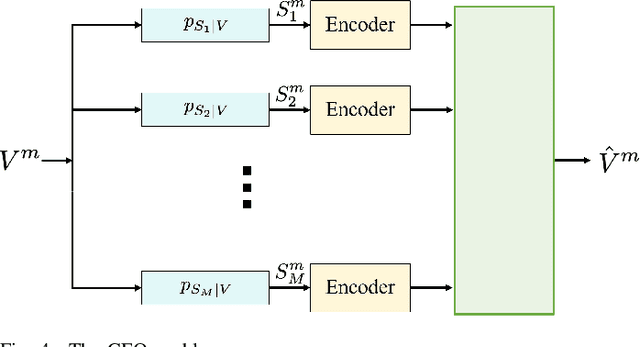
This tutorial paper focuses on the variants of the bottleneck problem taking an information theoretic perspective and discusses practical methods to solve it, as well as its connection to coding and learning aspects. The intimate connections of this setting to remote source-coding under logarithmic loss distortion measure, information combining, common reconstruction, the Wyner-Ahlswede-Korner problem, the efficiency of investment information, as well as, generalization, variational inference, representation learning, autoencoders, and others are highlighted. We discuss its extension to the distributed information bottleneck problem with emphasis on the Gaussian model and highlight the basic connections to the uplink Cloud Radio Access Networks (CRAN) with oblivious processing. For this model, the optimal trade-offs between relevance (i.e., information) and complexity (i.e., rates) in the discrete and vector Gaussian frameworks is determined. In the concluding outlook, some interesting problems are mentioned such as the characterization of the optimal inputs ("features") distributions under power limitations maximizing the "relevance" for the Gaussian information bottleneck, under "complexity" constraints.
Distributed Variational Representation Learning
Jul 27, 2018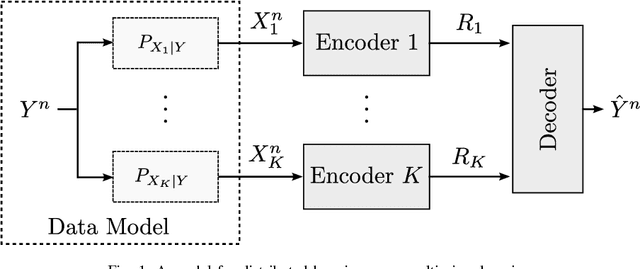
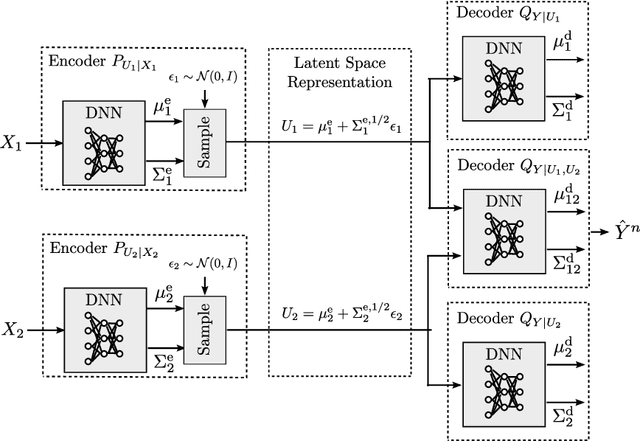
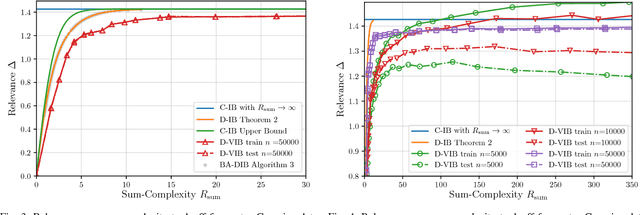

The problem of distributed representation learning is one in which multiple sources of information $X_1,\ldots,X_K$ are processed separately so as to learn as much information as possible about some ground truth $Y$. We investigate this problem from information-theoretic grounds, through a generalization of Tishby's centralized Information Bottleneck (IB) method to the distributed setting. Specifically, $K$ encoders, $K \geq 2$, compress their observations $X_1,\ldots,X_K$ separately in a manner such that, collectively, the produced representations preserve as much information as possible about $Y$. We study both discrete memoryless (DM) and memoryless vector Gaussian data models. For the discrete model, we establish a single-letter characterization of the optimal tradeoff between complexity (or rate) and relevance (or information) for a class of memoryless sources (the observations $X_1,\ldots,X_K$ being conditionally independent given $Y$). For the vector Gaussian model, we provide an explicit characterization of the optimal complexity-relevance tradeoff. Furthermore, we develop a variational bound on the complexity-relevance tradeoff which generalizes the evidence lower bound (ELBO) to the distributed setting. We also provide two algorithms that allow to compute this bound: i) a Blahut-Arimoto type iterative algorithm which enables to compute optimal complexity-relevance encoding mappings by iterating over a set of self-consistent equations, and ii) a variational inference type algorithm in which the encoding mappings are parametrized by neural networks and the bound approximated by Markov sampling and optimized with stochastic gradient descent. Numerical results on synthetic and real datasets are provided to support the efficiency of the approaches and algorithms developed in this paper.