 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Generalizable NeRF Architecture Selection for Satellite Scene Reconstruction
Mar 18, 2026Neural Radiance Fields (NeRF) have emerged as a powerful approach for photorealistic 3D reconstruction from multi-view images. However, deploying NeRF for satellite imagery remains challenging. Each scene requires individual training, and optimizing architectures via Neural Architecture Search (NAS) demands hours to days of GPU time. While existing approaches focus on architectural improvements, our SHAP analysis reveals that multi-view consistency, rather than model architecture, determines reconstruction quality. Based on this insight, we develop PreSCAN, a predictive framework that estimates NeRF quality prior to training using lightweight geometric and photometric descriptors. PreSCAN selects suitable architectures in < 30 seconds with < 1 dB prediction error, achieving 1000$\times$ speedup over NAS. We further demonstrate PreSCAN's deployment utility on edge platforms (Jetson Orin), where combining its predictions with offline cost profiling reduces inference power by 26% and latency by 43% with minimal quality loss. Experiments on DFC2019 datasets confirm that PreSCAN generalizes across diverse satellite scenes without retraining.
Covariance-Guided Resource Adaptive Learning for Efficient Edge Inference
Mar 15, 2026For deep learning inference on edge devices, hardware configurations achieving the same throughput can differ by 2$\times$ in power consumption, yet operators often struggle to find the efficient ones without exhaustive profiling. Existing approaches often rely on inefficient static presets or require expensive offline profiling that must be repeated for each new model or device. To address this problem, we present CORAL, an online optimization method that discovers near-optimal configurations without offline profiling. CORAL leverages distance covariance to statistically capture the non-linear dependencies between hardware settings, e.g., DVFS and concurrency levels, and performance metrics. Unlike prior work, we explicitly formulate the challenge as a throughput-power co-optimization problem to satisfy power budgets and throughput targets simultaneously. We evaluate CORAL on two NVIDIA Jetson devices across three object detection models ranging from lightweight to heavyweight. In single-target scenarios, CORAL achieves 96% $\unicode{x2013}$ 100% of the optimal performance found by exhaustive search. In strict dual-constraint scenarios where baselines fail or exceed power budgets, CORAL consistently finds proper configurations online with minimal exploration.
Wasserstein Adversarial Transformer for Cloud Workload Prediction
Mar 12, 2022
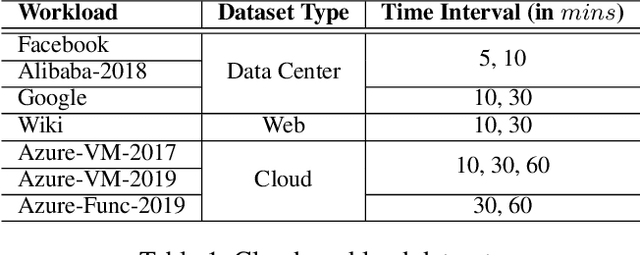
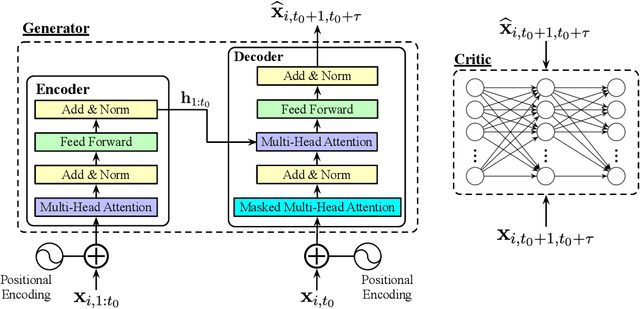
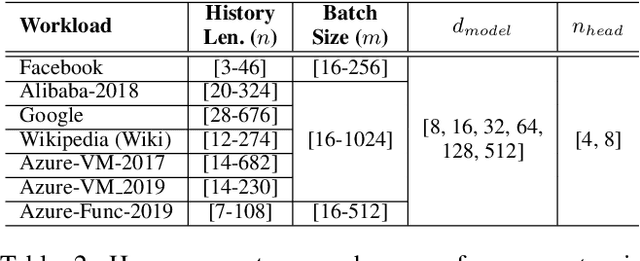
Predictive Virtual Machine (VM) auto-scaling is a promising technique to optimize cloud applications operating costs and performance. Understanding the job arrival rate is crucial for accurately predicting future changes in cloud workloads and proactively provisioning and de-provisioning VMs for hosting the applications. However, developing a model that accurately predicts cloud workload changes is extremely challenging due to the dynamic nature of cloud workloads. Long-Short-Term-Memory (LSTM) models have been developed for cloud workload prediction. Unfortunately, the state-of-the-art LSTM model leverages recurrences to predict, which naturally adds complexity and increases the inference overhead as input sequences grow longer. To develop a cloud workload prediction model with high accuracy and low inference overhead, this work presents a novel time-series forecasting model called WGAN-gp Transformer, inspired by the Transformer network and improved Wasserstein-GANs. The proposed method adopts a Transformer network as a generator and a multi-layer perceptron as a critic. The extensive evaluations with real-world workload traces show WGAN-gp Transformer achieves 5 times faster inference time with up to 5.1 percent higher prediction accuracy against the state-of-the-art approach. We also apply WGAN-gp Transformer to auto-scaling mechanisms on Google cloud platforms, and the WGAN-gp Transformer-based auto-scaling mechanism outperforms the LSTM-based mechanism by significantly reducing VM over-provisioning and under-provisioning rates.