 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness in Deep Learning for Computer Vision: Mind the gap?
Dec 01, 2021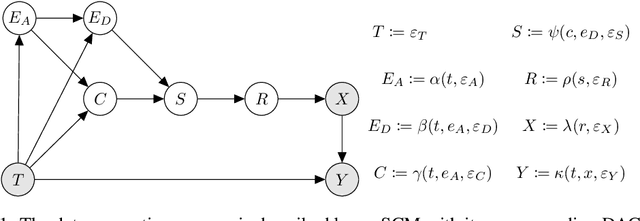
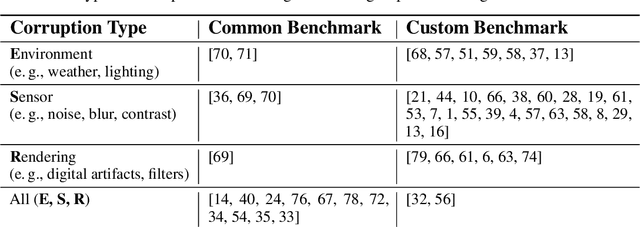

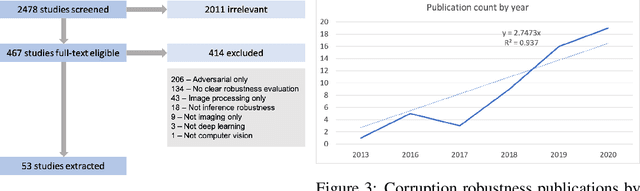
Deep neural networks for computer vision tasks are deployed in increasingly safety-critical and socially-impactful applications, motivating the need to close the gap in model performance under varied, naturally occurring imaging conditions. Robustness, ambiguously used in multiple contexts including adversarial machine learning, here then refers to preserving model performance under naturally-induced image corruptions or alterations. We perform a systematic review to identify, analyze, and summarize current definitions and progress towards non-adversarial robustness in deep learning for computer vision. We find that this area of research has received disproportionately little attention relative to adversarial machine learning, yet a significant robustness gap exists that often manifests in performance degradation similar in magnitude to adversarial conditions. To provide a more transparent definition of robustness across contexts, we introduce a structural causal model of the data generating process and interpret non-adversarial robustness as pertaining to a model's behavior on corrupted images which correspond to low-probability samples from the unaltered data distribution. We then identify key architecture-, data augmentation-, and optimization tactics for improving neural network robustness. This causal view of robustness reveals that common practices in the current literature, both in regards to robustness tactics and evaluations, correspond to causal concepts, such as soft interventions resulting in a counterfactually-altered distribution of imaging conditions. Through our findings and analysis, we offer perspectives on how future research may mind this evident and significant non-adversarial robustness gap.
Proximal Causal Inference with Hidden Mediators: Front-Door and Related Mediation Problems
Nov 04, 2021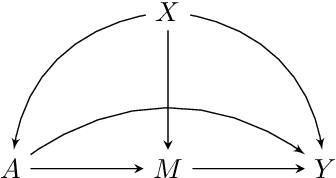
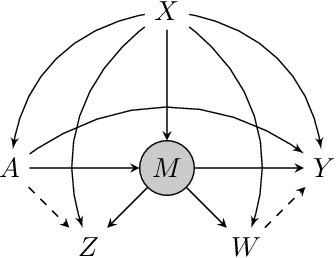
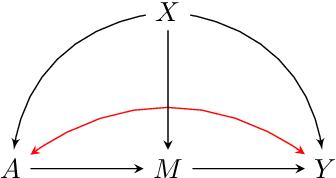
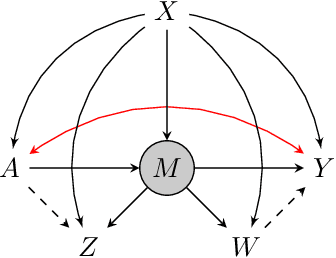
Proximal causal inference was recently proposed as a framework to identify causal effects from observational data in the presence of hidden confounders for which proxies are available. In this paper, we extend the proximal causal approach to settings where identification of causal effects hinges upon a set of mediators which unfortunately are not directly observed, however proxies of the hidden mediators are measured. Specifically, we establish (i) a new hidden front-door criterion which extends the classical front-door result to allow for hidden mediators for which proxies are available; (ii) We extend causal mediation analysis to identify direct and indirect causal effects under unconfoundedness conditions in a setting where the mediator in view is hidden, but error prone proxies of the latter are available. We view (i) and (ii) as important steps towards the practical application of front-door criteria and mediation analysis as mediators are almost always error prone and thus, the most one can hope for in practice is that our measurements are at best proxies of mediating mechanisms. Finally, we show that identification of certain causal effects remains possible even in settings where challenges in (i) and (ii) might co-exist.
Partially Intervenable Causal Models
Oct 31, 2021

Graphical causal models led to the development of complete non-parametric identification theory in arbitrary structured systems, and general approaches to efficient inference. Nevertheless, graphical approaches to causal inference have not been embraced by the statistics and public health communities. In those communities causal assumptions are instead expressed in terms of potential outcomes, or responses to hypothetical interventions. Such interventions are generally conceptualized only on a limited set of variables, where the corresponding experiment could, in principle, be performed. By contrast, graphical approaches to causal inference generally assume interventions on all variables are well defined - an overly restrictive and unrealistic assumption that may have limited the adoption of these approaches in applied work in statistics and public health. In this paper, we build on a unification of graphical and potential outcomes approaches to causality exemplified by Single World Intervention Graphs (SWIGs) to define graphical models with a restricted set of allowed interventions. We give a complete identification theory for such models, and develop a complete calculus of interventions based on a generalization of the do-calculus, and axioms that govern probabilistic operations on Markov kernels. A corollary of our results is a complete identification theory for causal effects in another graphical framework with a restricted set of interventions, the decision theoretic graphical formulation of causality.
An Automated Approach to Causal Inference in Discrete Settings
Sep 28, 2021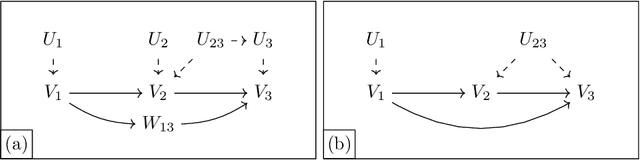

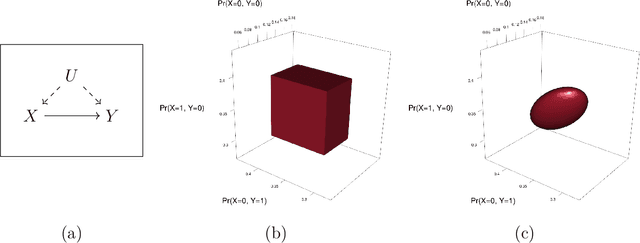

When causal quantities cannot be point identified, researchers often pursue partial identification to quantify the range of possible values. However, the peculiarities of applied research conditions can make this analytically intractable. We present a general and automated approach to causal inference in discrete settings. We show causal questions with discrete data reduce to polynomial programming problems, and we present an algorithm to automatically bound causal effects using efficient dual relaxation and spatial branch-and-bound techniques. The user declares an estimand, states assumptions, and provides data (however incomplete or mismeasured). The algorithm then searches over admissible data-generating processes and outputs the most precise possible range consistent with available information -- i.e., sharp bounds -- including a point-identified solution if one exists. Because this search can be computationally intensive, our procedure reports and continually refines non-sharp ranges that are guaranteed to contain the truth at all times, even when the algorithm is not run to completion. Moreover, it offers an additional guarantee we refer to as $\epsilon$-sharpness, characterizing the worst-case looseness of the incomplete bounds. Analytically validated simulations show the algorithm accommodates classic obstacles, including confounding, selection, measurement error, noncompliance, and nonresponse.
The Proximal ID Algorithm
Aug 15, 2021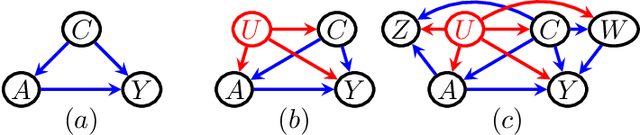
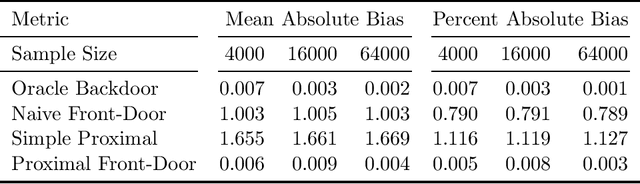
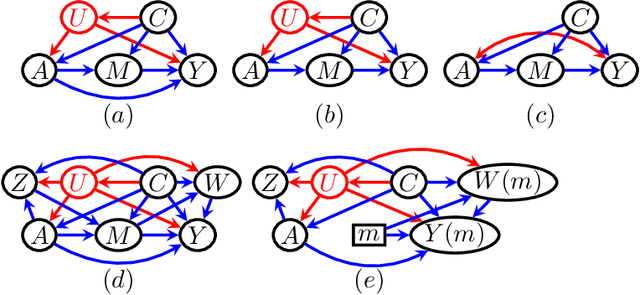
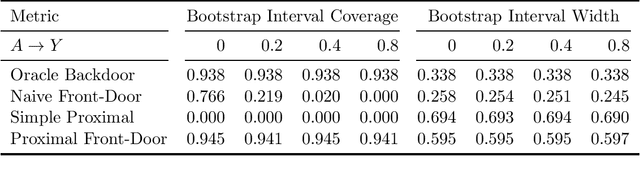
Unobserved confounding is a fundamental obstacle to establishing valid causal conclusions from observational data. Two complementary types of approaches have been developed to address this obstacle. An extensive line of work is based on taking advantage of fortuitous external aids (such as the presence of an instrumental variable or other proxy), along with additional assumptions to ensure identification. A recent line of work of proximal causal inference (Miao et al., 2018a) has aimed to provide a novel approach to using proxies to deal with unobserved confounding without relying on stringent parametric assumptions. On the other hand, a complete characterization of identifiability of a large class of causal parameters in arbitrary causal models with hidden variables has been developed using the language of graphical models, resulting in the ID algorithm and related extensions (Tian and Pearl, 2002; Shpitser and Pearl, 2006a,b). Celebrated special cases of this approach, such as the front-door model, are able to obtain non-parametric identification in seemingly counter-intuitive situations when a treatment and an outcome share an arbitrarily complicated unobserved common cause. In this paper we aim to develop a synthesis of the proximal and graphical approaches to identification in causal inference to yield the most general identification algorithm in multi- variate systems currently known - the proximal ID algorithm. In addition to being able to obtain non-parametric identification in all cases where the ID algorithm succeeds, our approach allows us to systematically exploit proxies to adjust for the presence of unobserved confounders that would have otherwise prevented identification. In addition, we outline a class of estimation strategies for causal parameters identified by our method in an important special case. We illustration our approach by simulation studies.
Entropic Inequality Constraints from $e$-separation Relations in Directed Acyclic Graphs with Hidden Variables
Jul 15, 2021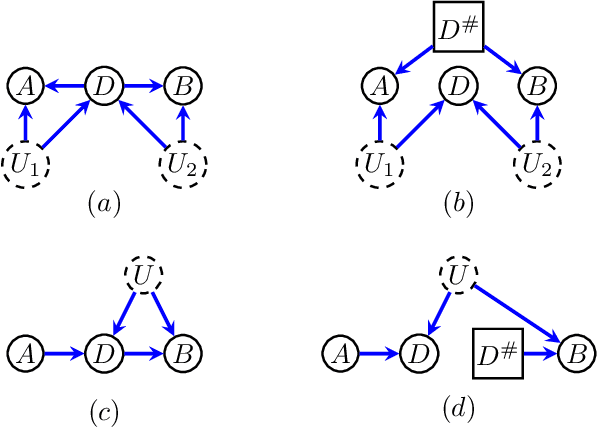
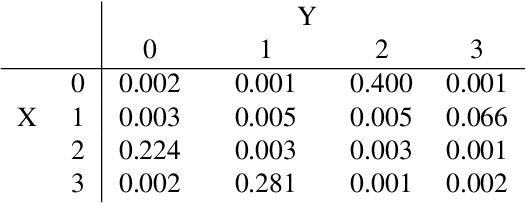
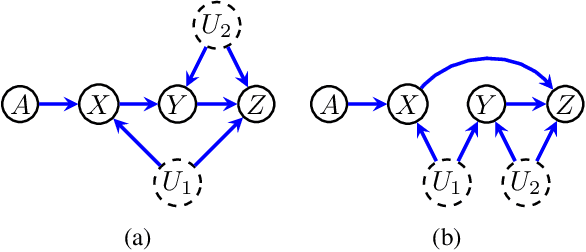
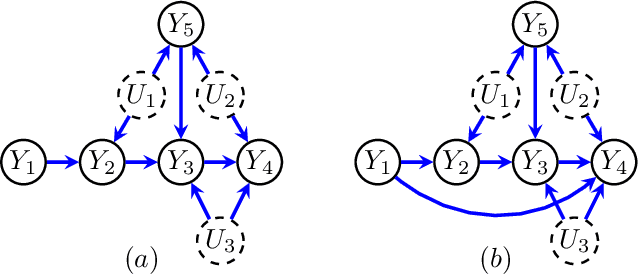
Directed acyclic graphs (DAGs) with hidden variables are often used to characterize causal relations between variables in a system. When some variables are unobserved, DAGs imply a notoriously complicated set of constraints on the distribution of observed variables. In this work, we present entropic inequality constraints that are implied by $e$-separation relations in hidden variable DAGs with discrete observed variables. The constraints can intuitively be understood to follow from the fact that the capacity of variables along a causal pathway to convey information is restricted by their entropy; e.g. at the extreme case, a variable with entropy $0$ can convey no information. We show how these constraints can be used to learn about the true causal model from an observed data distribution. In addition, we propose a measure of causal influence called the minimal mediary entropy, and demonstrate that it can augment traditional measures such as the average causal effect.
Multiply Robust Causal Mediation Analysis with Continuous Treatments
May 19, 2021In many applications, researchers are interested in the direct and indirect causal effects of an intervention on an outcome of interest. Mediation analysis offers a rigorous framework for the identification and estimation of such causal quantities. In the case of binary treatment, efficient estimators for the direct and indirect effects are derived by Tchetgen Tchetgen and Shpitser (2012). These estimators are based on influence functions and possess desirable multiple robustness properties. However, they are not readily applicable when treatments are continuous, which is the case in several settings, such as drug dosage in medical applications. In this work, we extend the influence function-based estimator of Tchetgen Tchetgen and Shpitser (2012) to deal with continuous treatments by utilizing a kernel smoothing approach. We first demonstrate that our proposed estimator preserves the multiple robustness property of the estimator in Tchetgen Tchetgen and Shpitser (2012). Then we show that under certain mild regularity conditions, our estimator is asymptotically normal. Our estimation scheme allows for high-dimensional nuisance parameters that can be estimated at slower rates than the target parameter. Additionally, we utilize cross-fitting, which allows for weaker smoothness requirements for the nuisance functions.
Minimax Kernel Machine Learning for a Class of Doubly Robust Functionals
Apr 07, 2021
A moment function is called doubly robust if it is comprised of two nuisance functions and the estimator based on it is a consistent estimator of the target parameter even if one of the nuisance functions is misspecified. In this paper, we consider a class of doubly robust moment functions originally introduced in (Robins et al., 2008). We demonstrate that this moment function can be used to construct estimating equations for the nuisance functions. The main idea is to choose each nuisance function such that it minimizes the dependency of the expected value of the moment function to the other nuisance function. We implement this idea as a minimax optimization problem. We then provide conditions required for asymptotic linearity of the estimator of the parameter of interest, which are based on the convergence rate of the product of the errors of the nuisance functions, as well as the local ill-posedness of a conditional expectation operator. The convergence rates of the nuisance functions are analyzed using the modern techniques in statistical learning theory based on the Rademacher complexity of the function spaces. We specifically focus on the case that the function spaces are reproducing kernel Hilbert spaces, which enables us to use its spectral properties to analyze the convergence rates. As an application of the proposed methodology, we consider the parameter of average causal effect both in presence and absence of latent confounders. For the case of presence of latent confounders, we use the recently proposed proximal causal inference framework of (Miao et al., 2018; Tchetgen Tchetgen et al., 2020), and hence our results lead to a robust non-parametric estimator for average causal effect in this framework.
Generating Synthetic Text Data to Evaluate Causal Inference Methods
Feb 10, 2021
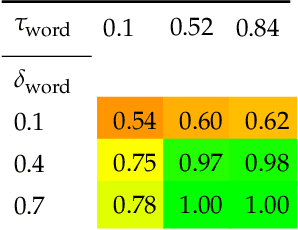
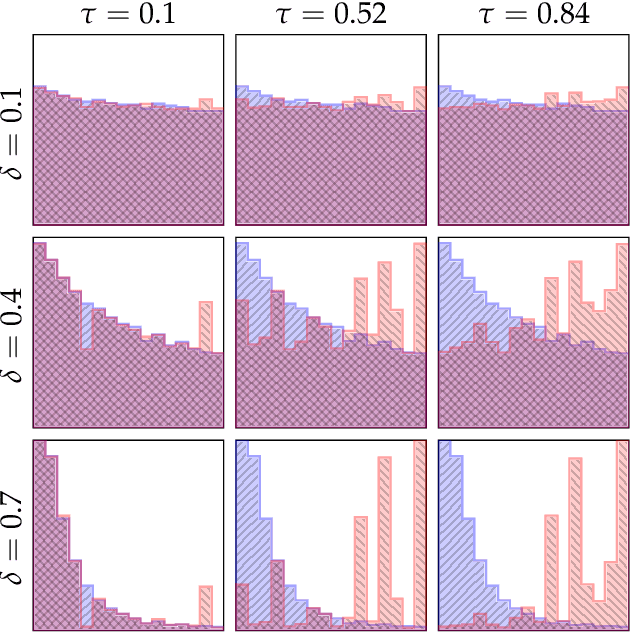
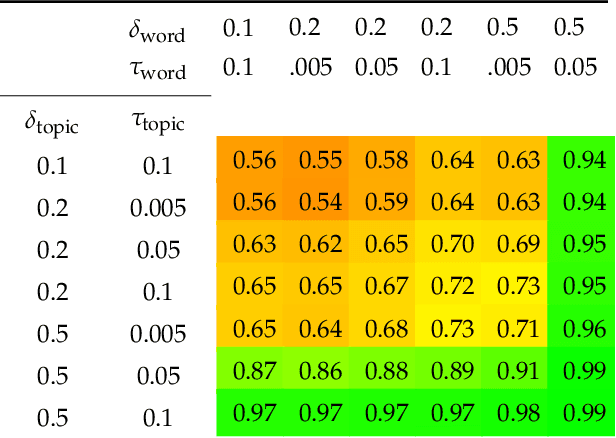
Drawing causal conclusions from observational data requires making assumptions about the true data-generating process. Causal inference research typically considers low-dimensional data, such as categorical or numerical fields in structured medical records. High-dimensional and unstructured data such as natural language complicates the evaluation of causal inference methods; such evaluations rely on synthetic datasets with known causal effects. Models for natural language generation have been widely studied and perform well empirically. However, existing methods not immediately applicable to producing synthetic datasets for causal evaluations, as they do not allow for quantifying a causal effect on the text itself. In this work, we develop a framework for adapting existing generation models to produce synthetic text datasets with known causal effects. We use this framework to perform an empirical comparison of four recently-proposed methods for estimating causal effects from text data. We release our code and synthetic datasets.
Partial Identifiability in Discrete Data With Measurement Error
Dec 23, 2020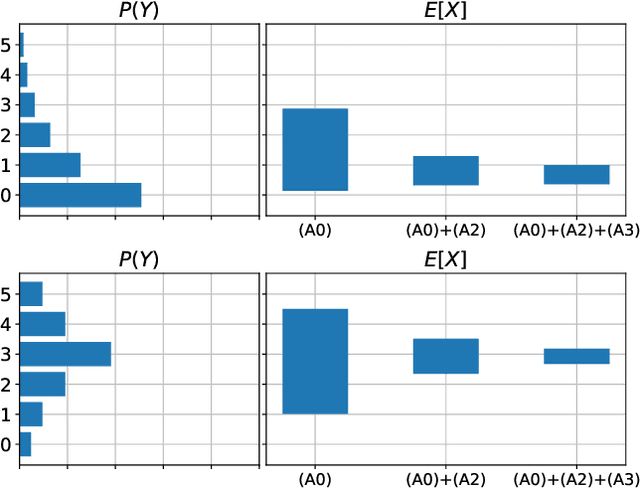
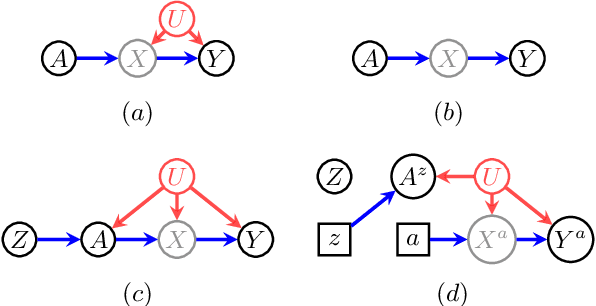
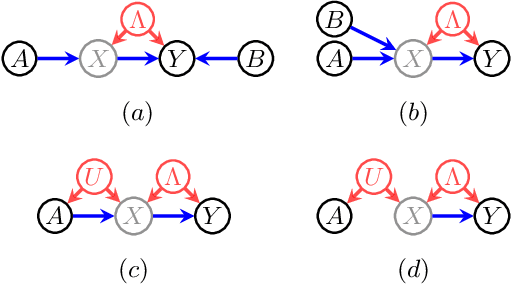
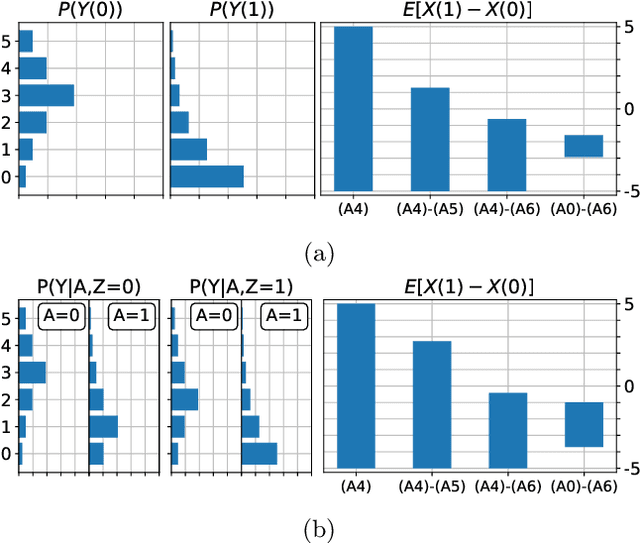
When data contains measurement errors, it is necessary to make assumptions relating the observed, erroneous data to the unobserved true phenomena of interest. These assumptions should be justifiable on substantive grounds, but are often motivated by mathematical convenience, for the sake of exactly identifying the target of inference. We adopt the view that it is preferable to present bounds under justifiable assumptions than to pursue exact identification under dubious ones. To that end, we demonstrate how a broad class of modeling assumptions involving discrete variables, including common measurement error and conditional independence assumptions, can be expressed as linear constraints on the parameters of the model. We then use linear programming techniques to produce sharp bounds for factual and counterfactual distributions under measurement error in such models. We additionally propose a procedure for obtaining outer bounds on non-linear models. Our method yields sharp bounds in a number of important settings -- such as the instrumental variable scenario with measurement error -- for which no bounds were previously known.