 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spectral Algorithm for List-Decodable Covariance Estimation in Relative Frobenius Norm
May 01, 2023We study the problem of list-decodable Gaussian covariance estimation. Given a multiset $T$ of $n$ points in $\mathbb R^d$ such that an unknown $\alpha<1/2$ fraction of points in $T$ are i.i.d. samples from an unknown Gaussian $\mathcal{N}(\mu, \Sigma)$, the goal is to output a list of $O(1/\alpha)$ hypotheses at least one of which is close to $\Sigma$ in relative Frobenius norm. Our main result is a $\mathrm{poly}(d,1/\alpha)$ sample and time algorithm for this task that guarantees relative Frobenius norm error of $\mathrm{poly}(1/\alpha)$. Importantly, our algorithm relies purely on spectral techniques. As a corollary, we obtain an efficient spectral algorithm for robust partial clustering of Gaussian mixture models (GMMs) -- a key ingredient in the recent work of [BDJ+22] on robustly learning arbitrary GMMs. Combined with the other components of [BDJ+22], our new method yields the first Sum-of-Squares-free algorithm for robustly learning GMMs. At the technical level, we develop a novel multi-filtering method for list-decodable covariance estimation that may be useful in other settings.
Efficient Testable Learning of Halfspaces with Adversarial Label Noise
Mar 09, 2023
We give the first polynomial-time algorithm for the testable learning of halfspaces in the presence of adversarial label noise under the Gaussian distribution. In the recently introduced testable learning model, one is required to produce a tester-learner such that if the data passes the tester, then one can trust the output of the robust learner on the data. Our tester-learner runs in time $\poly(d/\eps)$ and outputs a halfspace with misclassification error $O(\opt)+\eps$, where $\opt$ is the 0-1 error of the best fitting halfspace. At a technical level, our algorithm employs an iterative soft localization technique enhanced with appropriate testers to ensure that the data distribution is sufficiently similar to a Gaussian.
Near-Optimal Cryptographic Hardness of Agnostically Learning Halfspaces and ReLU Regression under Gaussian Marginals
Feb 13, 2023We study the task of agnostically learning halfspaces under the Gaussian distribution. Specifically, given labeled examples $(\mathbf{x},y)$ from an unknown distribution on $\mathbb{R}^n \times \{ \pm 1\}$, whose marginal distribution on $\mathbf{x}$ is the standard Gaussian and the labels $y$ can be arbitrary, the goal is to output a hypothesis with 0-1 loss $\mathrm{OPT}+\epsilon$, where $\mathrm{OPT}$ is the 0-1 loss of the best-fitting halfspace. We prove a near-optimal computational hardness result for this task, under the widely believed sub-exponential time hardness of the Learning with Errors (LWE) problem. Prior hardness results are either qualitatively suboptimal or apply to restricted families of algorithms. Our techniques extend to yield near-optimal lower bounds for related problems, including ReLU regression.
A Nearly Tight Bound for Fitting an Ellipsoid to Gaussian Random Points
Dec 21, 2022We prove that for $c>0$ a sufficiently small universal constant that a random set of $c d^2/\log^4(d)$ independent Gaussian random points in $\mathbb{R}^d$ lie on a common ellipsoid with high probability. This nearly establishes a conjecture of~\cite{SaundersonCPW12}, within logarithmic factors. The latter conjecture has attracted significant attention over the past decade, due to its connections to machine learning and sum-of-squares lower bounds for certain statistical problems.
A Strongly Polynomial Algorithm for Approximate Forster Transforms and its Application to Halfspace Learning
Dec 06, 2022The Forster transform is a method of regularizing a dataset by placing it in {\em radial isotropic position} while maintaining some of its essential properties. Forster transforms have played a key role in a diverse range of settings spanning computer science and functional analysis. Prior work had given {\em weakly} polynomial time algorithms for computing Forster transforms, when they exist. Our main result is the first {\em strongly polynomial time} algorithm to compute an approximate Forster transform of a given dataset or certify that no such transformation exists. By leveraging our strongly polynomial Forster algorithm, we obtain the first strongly polynomial time algorithm for {\em distribution-free} PAC learning of halfspaces. This learning result is surprising because {\em proper} PAC learning of halfspaces is {\em equivalent} to linear programming. Our learning approach extends to give a strongly polynomial halfspace learner in the presence of random classification noise and, more generally, Massart noise.
Outlier-Robust Sparse Mean Estimation for Heavy-Tailed Distributions
Nov 29, 2022We study the fundamental task of outlier-robust mean estimation for heavy-tailed distributions in the presence of sparsity. Specifically, given a small number of corrupted samples from a high-dimensional heavy-tailed distribution whose mean $\mu$ is guaranteed to be sparse, the goal is to efficiently compute a hypothesis that accurately approximates $\mu$ with high probability. Prior work had obtained efficient algorithms for robust sparse mean estimation of light-tailed distributions. In this work, we give the first sample-efficient and polynomial-time robust sparse mean estimator for heavy-tailed distributions under mild moment assumptions. Our algorithm achieves the optimal asymptotic error using a number of samples scaling logarithmically with the ambient dimension. Importantly, the sample complexity of our method is optimal as a function of the failure probability $\tau$, having an additive $\log(1/\tau)$ dependence. Our algorithm leverages the stability-based approach from the algorithmic robust statistics literature, with crucial (and necessary) adaptations required in our setting. Our analysis may be of independent interest, involving the delicate design of a (non-spectral) decomposition for positive semi-definite matrices satisfying certain sparsity properties.
Gaussian Mean Testing Made Simple
Oct 25, 2022We study the following fundamental hypothesis testing problem, which we term Gaussian mean testing. Given i.i.d. samples from a distribution $p$ on $\mathbb{R}^d$, the task is to distinguish, with high probability, between the following cases: (i) $p$ is the standard Gaussian distribution, $\mathcal{N}(0,I_d)$, and (ii) $p$ is a Gaussian $\mathcal{N}(\mu,\Sigma)$ for some unknown covariance $\Sigma$ and mean $\mu \in \mathbb{R}^d$ satisfying $\|\mu\|_2 \geq \epsilon$. Recent work gave an algorithm for this testing problem with the optimal sample complexity of $\Theta(\sqrt{d}/\epsilon^2)$. Both the previous algorithm and its analysis are quite complicated. Here we give an extremely simple algorithm for Gaussian mean testing with a one-page analysis. Our algorithm is sample optimal and runs in sample linear time.
SQ Lower Bounds for Learning Single Neurons with Massart Noise
Oct 18, 2022We study the problem of PAC learning a single neuron in the presence of Massart noise. Specifically, for a known activation function $f: \mathbb{R} \to \mathbb{R}$, the learner is given access to labeled examples $(\mathbf{x}, y) \in \mathbb{R}^d \times \mathbb{R}$, where the marginal distribution of $\mathbf{x}$ is arbitrary and the corresponding label $y$ is a Massart corruption of $f(\langle \mathbf{w}, \mathbf{x} \rangle)$. The goal of the learner is to output a hypothesis $h: \mathbb{R}^d \to \mathbb{R}$ with small squared loss. For a range of activation functions, including ReLUs, we establish super-polynomial Statistical Query (SQ) lower bounds for this learning problem. In more detail, we prove that no efficient SQ algorithm can approximate the optimal error within any constant factor. Our main technical contribution is a novel SQ-hard construction for learning $\{ \pm 1\}$-weight Massart halfspaces on the Boolean hypercube that is interesting on its own right.
Cryptographic Hardness of Learning Halfspaces with Massart Noise
Jul 28, 2022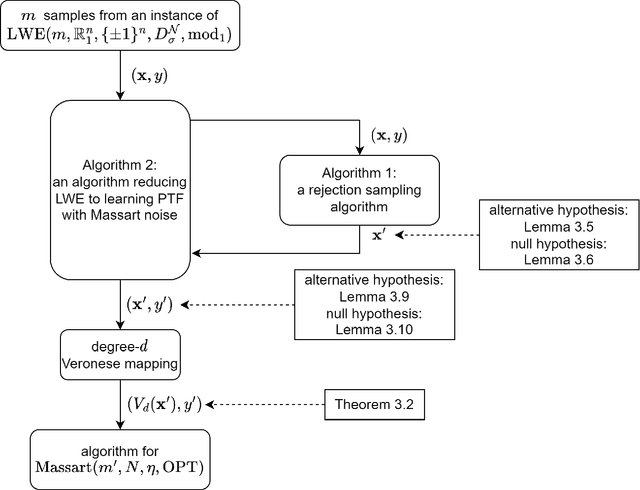
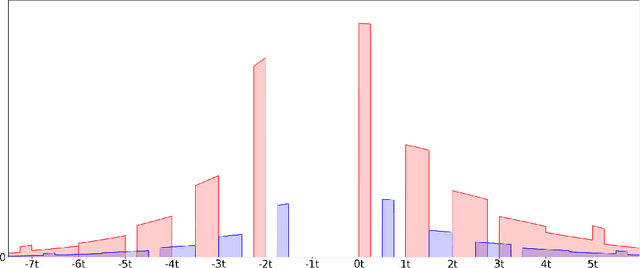
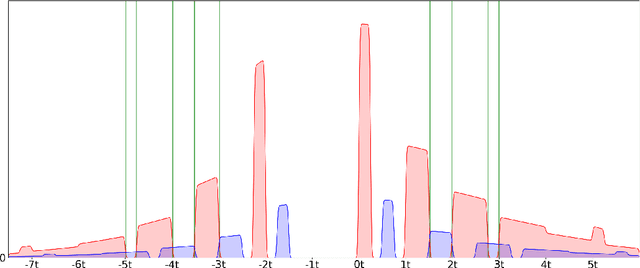
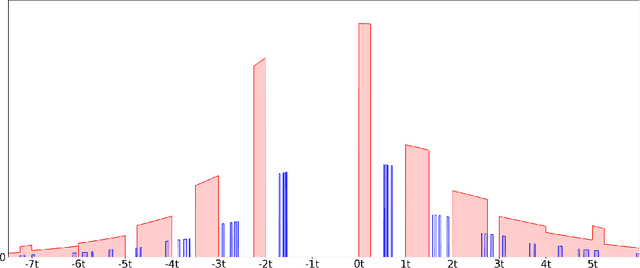
We study the complexity of PAC learning halfspaces in the presence of Massart noise. In this problem, we are given i.i.d. labeled examples $(\mathbf{x}, y) \in \mathbb{R}^N \times \{ \pm 1\}$, where the distribution of $\mathbf{x}$ is arbitrary and the label $y$ is a Massart corruption of $f(\mathbf{x})$, for an unknown halfspace $f: \mathbb{R}^N \to \{ \pm 1\}$, with flipping probability $\eta(\mathbf{x}) \leq \eta < 1/2$. The goal of the learner is to compute a hypothesis with small 0-1 error. Our main result is the first computational hardness result for this learning problem. Specifically, assuming the (widely believed) subexponential-time hardness of the Learning with Errors (LWE) problem, we show that no polynomial-time Massart halfspace learner can achieve error better than $\Omega(\eta)$, even if the optimal 0-1 error is small, namely $\mathrm{OPT} = 2^{-\log^{c} (N)}$ for any universal constant $c \in (0, 1)$. Prior work had provided qualitatively similar evidence of hardness in the Statistical Query model. Our computational hardness result essentially resolves the polynomial PAC learnability of Massart halfspaces, by showing that known efficient learning algorithms for the problem are nearly best possible.
Near-Optimal Bounds for Testing Histogram Distributions
Jul 14, 2022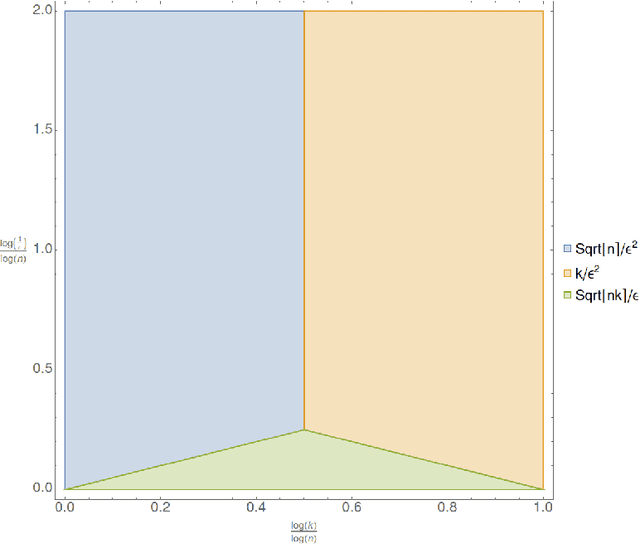
We investigate the problem of testing whether a discrete probability distribution over an ordered domain is a histogram on a specified number of bins. One of the most common tools for the succinct approximation of data, $k$-histograms over $[n]$, are probability distributions that are piecewise constant over a set of $k$ intervals. The histogram testing problem is the following: Given samples from an unknown distribution $\mathbf{p}$ on $[n]$, we want to distinguish between the cases that $\mathbf{p}$ is a $k$-histogram versus $\varepsilon$-far from any $k$-histogram, in total variation distance. Our main result is a sample near-optimal and computationally efficient algorithm for this testing problem, and a nearly-matching (within logarithmic factors) sample complexity lower bound. Specifically, we show that the histogram testing problem has sample complexity $\widetilde \Theta (\sqrt{nk} / \varepsilon + k / \varepsilon^2 + \sqrt{n} / \varepsilon^2)$.