 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Gaussian Diffusion Models Fail on Discrete Data?
Apr 02, 2026Diffusion models have become a standard approach for generative modeling in continuous domains, yet their application to discrete data remains challenging. We investigate why Gaussian diffusion models with the DDPM solver struggle to sample from discrete distributions that are represented as a mixture of delta-distributions in the continuous space. Using a toy Random Hierarchy Model, we identify a critical sampling interval in which the density of noisified data becomes multimodal. In this regime, DDPM occasionally enters low-density regions between modes producing out-of-distribution inputs for the model and degrading sample quality. We show that existing heuristics, including self-conditioning and a solver we term q-sampling, help alleviate this issue. Furthermore, we demonstrate that combining self-conditioning with switching from DDPM to q-sampling within the critical interval improves generation quality on real data. We validate these findings across conditional and unconditional tasks in multiple domains, including text, programming code, and proteins.
Can Training Dynamics of Scale-Invariant Neural Networks Be Explained by the Thermodynamics of an Ideal Gas?
Nov 10, 2025



Understanding the training dynamics of deep neural networks remains a major open problem, with physics-inspired approaches offering promising insights. Building on this perspective, we develop a thermodynamic framework to describe the stationary distributions of stochastic gradient descent (SGD) with weight decay for scale-invariant neural networks, a setting that both reflects practical architectures with normalization layers and permits theoretical analysis. We establish analogies between training hyperparameters (e.g., learning rate, weight decay) and thermodynamic variables such as temperature, pressure, and volume. Starting with a simplified isotropic noise model, we uncover a close correspondence between SGD dynamics and ideal gas behavior, validated through theory and simulation. Extending to training of neural networks, we show that key predictions of the framework, including the behavior of stationary entropy, align closely with experimental observations. This framework provides a principled foundation for interpreting training dynamics and may guide future work on hyperparameter tuning and the design of learning rate schedulers.
SGD as Free Energy Minimization: A Thermodynamic View on Neural Network Training
May 29, 2025



We present a thermodynamic interpretation of the stationary behavior of stochastic gradient descent (SGD) under fixed learning rates (LRs) in neural network training. We show that SGD implicitly minimizes a free energy function $F=U-TS$, balancing training loss $U$ and the entropy of the weights distribution $S$, with temperature $T$ determined by the LR. This perspective offers a new lens on why high LRs prevent training from converging to the loss minima and how different LRs lead to stabilization at different loss levels. We empirically validate the free energy framework on both underparameterized (UP) and overparameterized (OP) models. UP models consistently follow free energy minimization, with temperature increasing monotonically with LR, while for OP models, the temperature effectively drops to zero at low LRs, causing SGD to minimize the loss directly and converge to an optimum. We attribute this mismatch to differences in the signal-to-noise ratio of stochastic gradients near optima, supported by both a toy example and neural network experiments.
Where Do Large Learning Rates Lead Us?
Oct 29, 2024



It is generally accepted that starting neural networks training with large learning rates (LRs) improves generalization. Following a line of research devoted to understanding this effect, we conduct an empirical study in a controlled setting focusing on two questions: 1) how large an initial LR is required for obtaining optimal quality, and 2) what are the key differences between models trained with different LRs? We discover that only a narrow range of initial LRs slightly above the convergence threshold lead to optimal results after fine-tuning with a small LR or weight averaging. By studying the local geometry of reached minima, we observe that using LRs from this optimal range allows for the optimization to locate a basin that only contains high-quality minima. Additionally, we show that these initial LRs result in a sparse set of learned features, with a clear focus on those most relevant for the task. In contrast, starting training with too small LRs leads to unstable minima and attempts to learn all features simultaneously, resulting in poor generalization. Conversely, using initial LRs that are too large fails to detect a basin with good solutions and extract meaningful patterns from the data.
To Stay or Not to Stay in the Pre-train Basin: Insights on Ensembling in Transfer Learning
Mar 06, 2023



Transfer learning and ensembling are two popular techniques for improving the performance and robustness of neural networks. Due to the high cost of pre-training, ensembles of models fine-tuned from a single pre-trained checkpoint are often used in practice. Such models end up in the same basin of the loss landscape and thus have limited diversity. In this work, we study if it is possible to improve ensembles trained from a single pre-trained checkpoint by better exploring the pre-train basin or a close vicinity outside of it. We show that while exploration of the pre-train basin may be beneficial for the ensemble, leaving the basin results in losing the benefits of transfer learning and degradation of the ensemble quality.
On the Memorization Properties of Contrastive Learning
Jul 21, 2021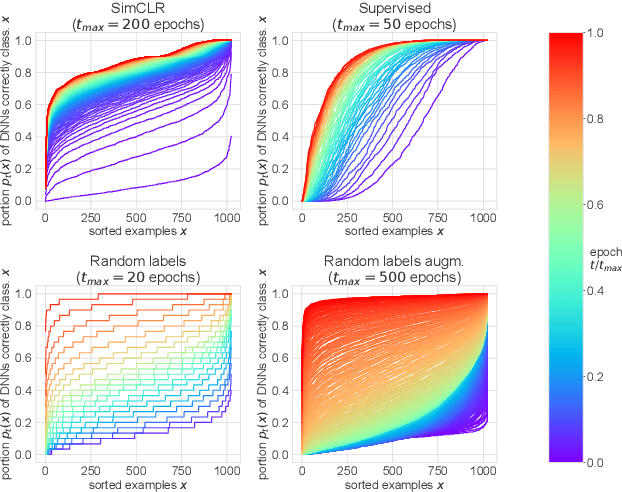
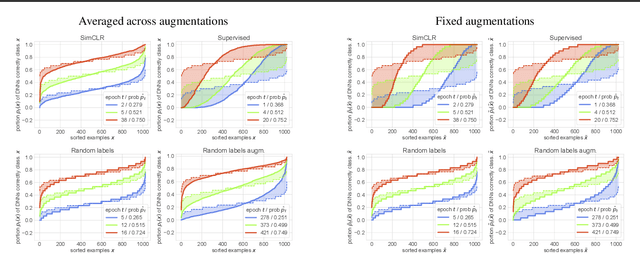
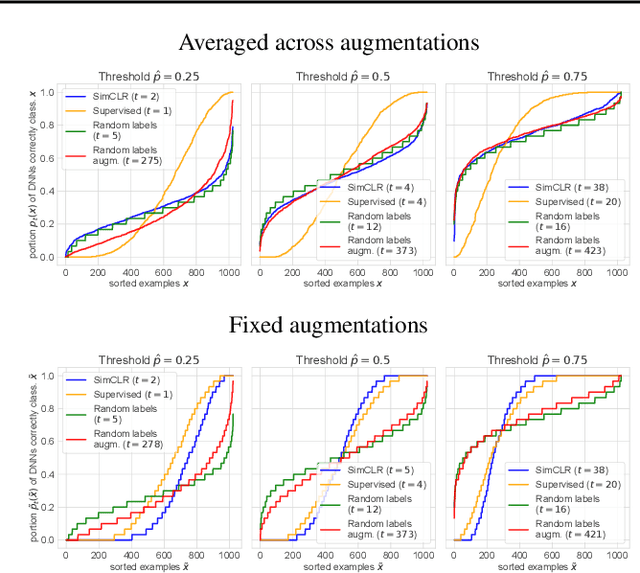
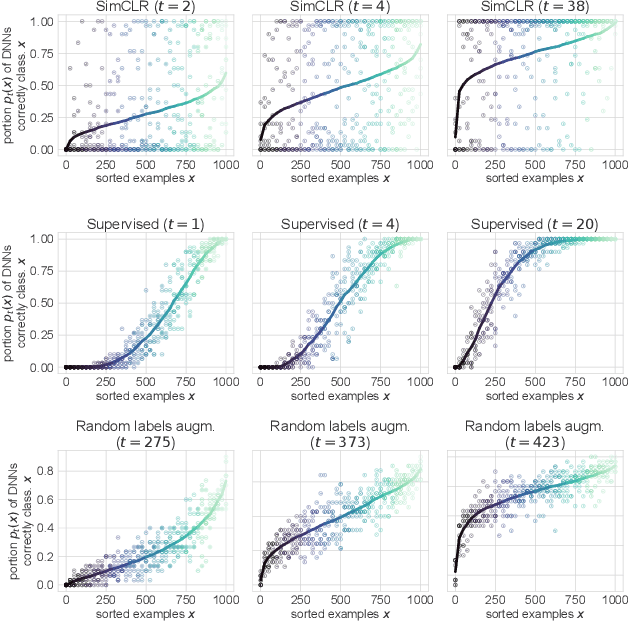
Memorization studies of deep neural networks (DNNs) help to understand what patterns and how do DNNs learn, and motivate improvements to DNN training approaches. In this work, we investigate the memorization properties of SimCLR, a widely used contrastive self-supervised learning approach, and compare them to the memorization of supervised learning and random labels training. We find that both training objects and augmentations may have different complexity in the sense of how SimCLR learns them. Moreover, we show that SimCLR is similar to random labels training in terms of the distribution of training objects complexity.