 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting English Speech in the Air Traffic Control Voice Communication
Apr 06, 2021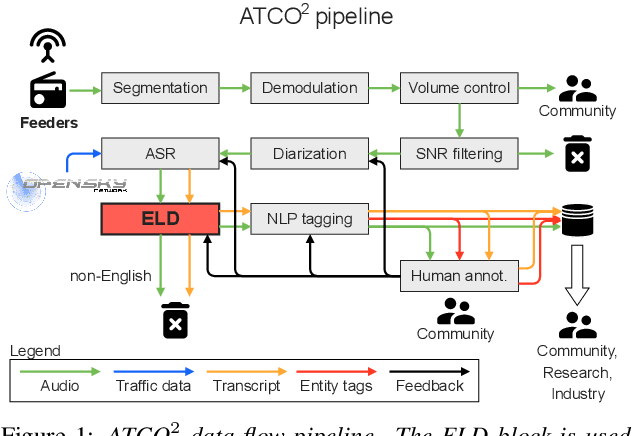
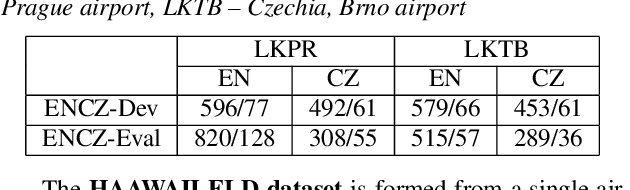
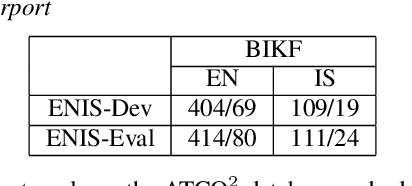

We launched a community platform for collecting the ATC speech world-wide in the ATCO2 project. Filtering out unseen non-English speech is one of the main components in the data processing pipeline. The proposed English Language Detection (ELD) system is based on the embeddings from Bayesian subspace multinomial model. It is trained on the word confusion network from an ASR system. It is robust, easy to train, and light weighted. We achieved 0.0439 equal-error-rate (EER), a 50% relative reduction as compared to the state-of-the-art acoustic ELD system based on x-vectors, in the in-domain scenario. Further, we achieved an EER of 0.1352, a 33% relative reduction as compared to the acoustic ELD, in the unseen language (out-of-domain) condition. We plan to publish the evaluation dataset from the ATCO2 project.