 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
DART: A Principled Approach to Adversarially Robust Unsupervised Domain Adaptation
Feb 16, 2024Distribution shifts and adversarial examples are two major challenges for deploying machine learning models. While these challenges have been studied individually, their combination is an important topic that remains relatively under-explored. In this work, we study the problem of adversarial robustness under a common setting of distribution shift - unsupervised domain adaptation (UDA). Specifically, given a labeled source domain $D_S$ and an unlabeled target domain $D_T$ with related but different distributions, the goal is to obtain an adversarially robust model for $D_T$. The absence of target domain labels poses a unique challenge, as conventional adversarial robustness defenses cannot be directly applied to $D_T$. To address this challenge, we first establish a generalization bound for the adversarial target loss, which consists of (i) terms related to the loss on the data, and (ii) a measure of worst-case domain divergence. Motivated by this bound, we develop a novel unified defense framework called Divergence Aware adveRsarial Training (DART), which can be used in conjunction with a variety of standard UDA methods; e.g., DANN [Ganin and Lempitsky, 2015]. DART is applicable to general threat models, including the popular $\ell_p$-norm model, and does not require heuristic regularizers or architectural changes. We also release DomainRobust: a testbed for evaluating robustness of UDA models to adversarial attacks. DomainRobust consists of 4 multi-domain benchmark datasets (with 46 source-target pairs) and 7 meta-algorithms with a total of 11 variants. Our large-scale experiments demonstrate that on average, DART significantly enhances model robustness on all benchmarks compared to the state of the art, while maintaining competitive standard accuracy. The relative improvement in robustness from DART reaches up to 29.2% on the source-target domain pairs considered.
EventScore: An Automated Real-time Early Warning Score for Clinical Events
Feb 14, 2021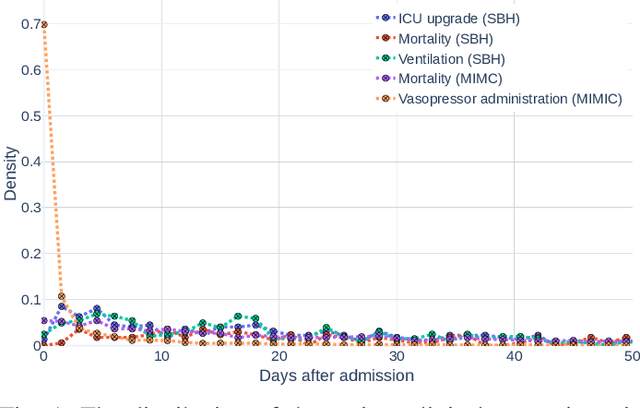
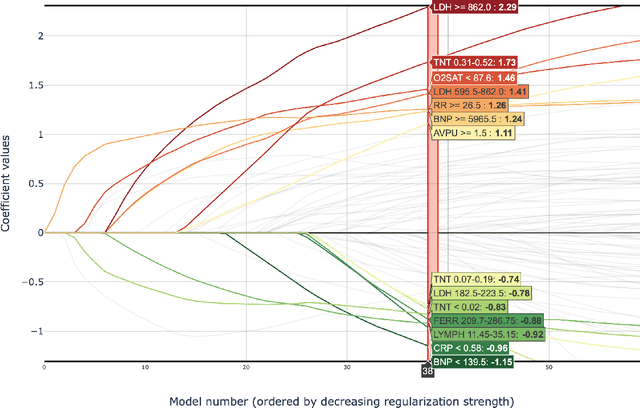
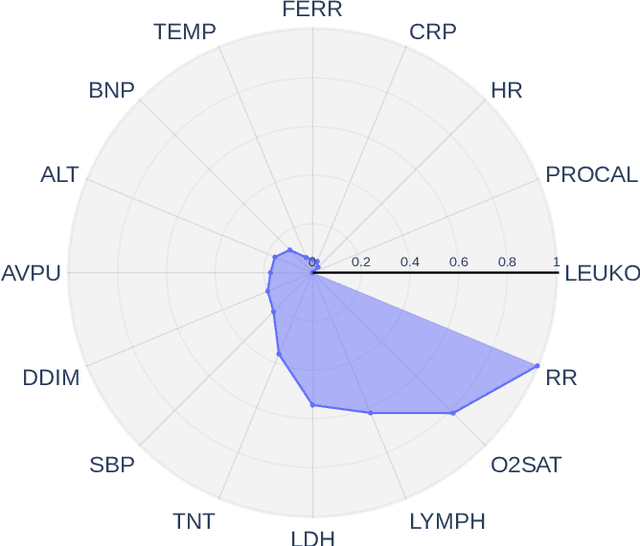
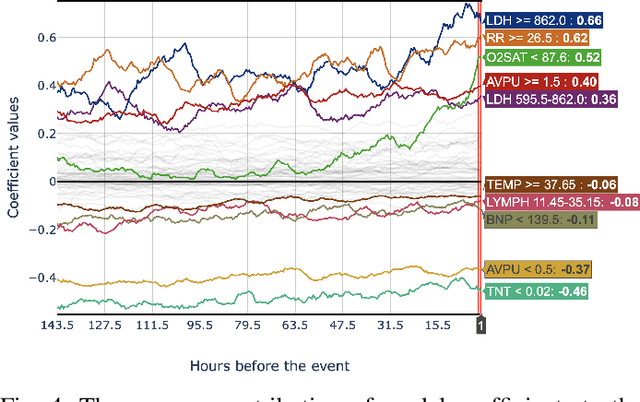
Early prediction of patients at risk of clinical deterioration can help physicians intervene and alter their clinical course towards better outcomes. In addition to the accuracy requirement, early warning systems must make the predictions early enough to give physicians enough time to intervene. Interpretability is also one of the challenges when building such systems since being able to justify the reasoning behind model decisions is desirable in clinical practice. In this work, we built an interpretable model for the early prediction of various adverse clinical events indicative of clinical deterioration. The model is evaluated on two datasets and four clinical events. The first dataset is collected in a predominantly COVID-19 positive population at Stony Brook Hospital. The second dataset is the MIMIC III dataset. The model was trained to provide early warning scores for ventilation, ICU transfer, and mortality prediction tasks on the Stony Brook Hospital dataset and to predict mortality and the need for vasopressors on the MIMIC III dataset. Our model first separates each feature into multiple ranges and then uses logistic regression with lasso penalization to select the subset of ranges for each feature. The model training is completely automated and doesn't require expert knowledge like other early warning scores. We compare our model to the Modified Early Warning Score (MEWS) and quick SOFA (qSOFA), commonly used in hospitals. We show that our model outperforms these models in the area under the receiver operating characteristic curve (AUROC) while having a similar or better median detection time on all clinical events, even when using fewer features. Unlike MEWS and qSOFA, our model can be entirely automated without requiring any manually recorded features. We also show that discretization improves model performance by comparing our model to a baseline logistic regression model.