 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Road Area Semantic Segmentation with Auxiliary Steering Task
Dec 19, 2022Robustness of different pattern recognition methods is one of the key challenges in autonomous driving, especially when driving in the high variety of road environments and weather conditions, such as gravel roads and snowfall. Although one can collect data from these adverse conditions using cars equipped with sensors, it is quite tedious to annotate the data for training. In this work, we address this limitation and propose a CNN-based method that can leverage the steering wheel angle information to improve the road area semantic segmentation. As the steering wheel angle data can be easily acquired with the associated images, one could improve the accuracy of road area semantic segmentation by collecting data in new road environments without manual data annotation. We demonstrate the effectiveness of the proposed approach on two challenging data sets for autonomous driving and show that when the steering task is used in our segmentation model training, it leads to a 0.1-2.9% gain in the road area mIoU (mean Intersection over Union) compared to the corresponding reference transfer learning model.
* 11 pages, 4 figures (Supplementary material 6 pages, 3 figures). Author's accepted version of the contribution included in proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP), 2022
Digging Into Self-Supervised Learning of Feature Descriptors
Oct 10, 2021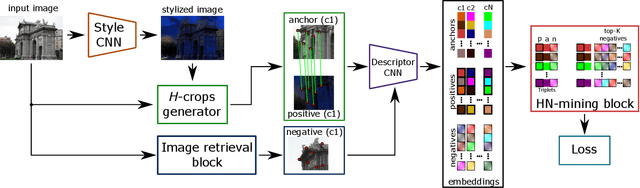
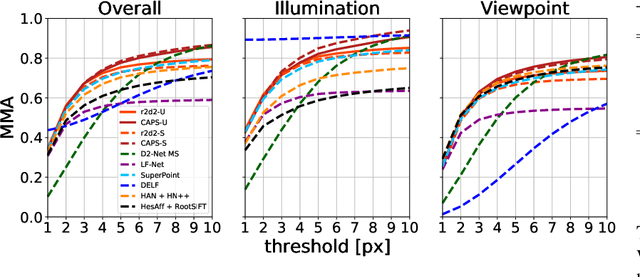
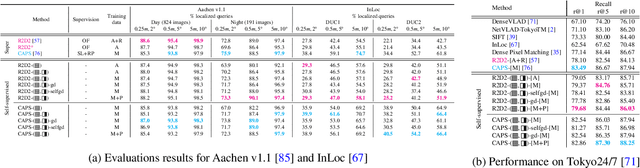

Fully-supervised CNN-based approaches for learning local image descriptors have shown remarkable results in a wide range of geometric tasks. However, most of them require per-pixel ground-truth keypoint correspondence data which is difficult to acquire at scale. To address this challenge, recent weakly- and self-supervised methods can learn feature descriptors from relative camera poses or using only synthetic rigid transformations such as homographies. In this work, we focus on understanding the limitations of existing self-supervised approaches and propose a set of improvements that combined lead to powerful feature descriptors. We show that increasing the search space from in-pair to in-batch for hard negative mining brings consistent improvement. To enhance the discriminativeness of feature descriptors, we propose a coarse-to-fine method for mining local hard negatives from a wider search space by using global visual image descriptors. We demonstrate that a combination of synthetic homography transformation, color augmentation, and photorealistic image stylization produces useful representations that are viewpoint and illumination invariant. The feature descriptors learned by the proposed approach perform competitively and surpass their fully- and weakly-supervised counterparts on various geometric benchmarks such as image-based localization, sparse feature matching, and image retrieval.
Continual Learning for Image-Based Camera Localization
Aug 20, 2021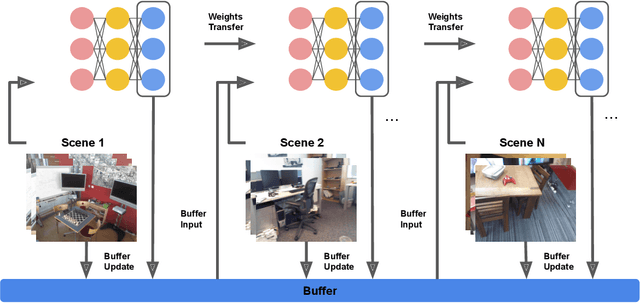
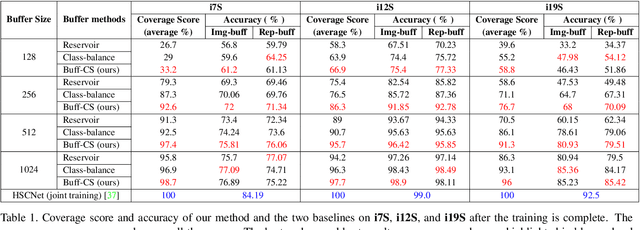
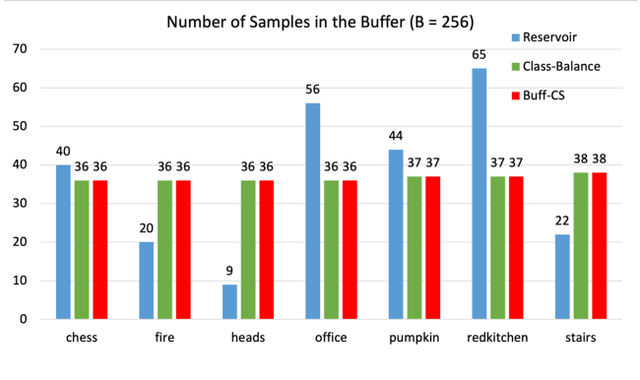

For several emerging technologies such as augmented reality, autonomous driving and robotics, visual localization is a critical component. Directly regressing camera pose/3D scene coordinates from the input image using deep neural networks has shown great potential. However, such methods assume a stationary data distribution with all scenes simultaneously available during training. In this paper, we approach the problem of visual localization in a continual learning setup -- whereby the model is trained on scenes in an incremental manner. Our results show that similar to the classification domain, non-stationary data induces catastrophic forgetting in deep networks for visual localization. To address this issue, a strong baseline based on storing and replaying images from a fixed buffer is proposed. Furthermore, we propose a new sampling method based on coverage score (Buff-CS) that adapts the existing sampling strategies in the buffering process to the problem of visual localization. Results demonstrate consistent improvements over standard buffering methods on two challenging datasets -- 7Scenes, 12Scenes, and also 19Scenes by combining the former scenes.
Multimodal End-to-End Learning for Autonomous Steering in Adverse Road and Weather Conditions
Oct 28, 2020
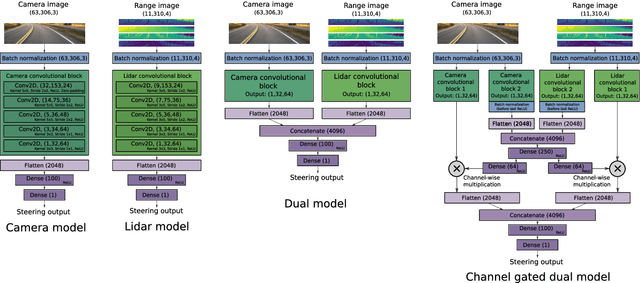
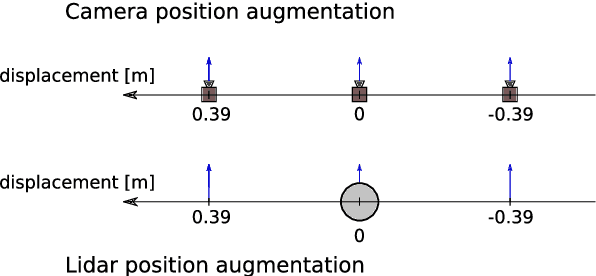

Autonomous driving is challenging in adverse road and weather conditions in which there might not be lane lines, the road might be covered in snow and the visibility might be poor. We extend the previous work on end-to-end learning for autonomous steering to operate in these adverse real-life conditions with multimodal data. We collected 28 hours of driving data in several road and weather conditions and trained convolutional neural networks to predict the car steering wheel angle from front-facing color camera images and lidar range and reflectance data. We compared the CNN model performances based on the different modalities and our results show that the lidar modality improves the performances of different multimodal sensor-fusion models. We also performed on-road tests with different models and they support this observation.
Image Stylization for Robust Features
Aug 16, 2020



Local features that are robust to both viewpoint and appearance changes are crucial for many computer vision tasks. In this work we investigate if photorealistic image stylization improves robustness of local features to not only day-night, but also weather and season variations. We show that image stylization in addition to color augmentation is a powerful method of learning robust features. We evaluate learned features on visual localization benchmarks, outperforming state of the art baseline models despite training without ground-truth 3D correspondences using synthetic homographies only. We use trained feature networks to compete in Long-Term Visual Localization and Map-based Localization for Autonomous Driving challenges achieving competitive scores.
KNEEL: Knee Anatomical Landmark Localization Using Hourglass Networks
Sep 06, 2019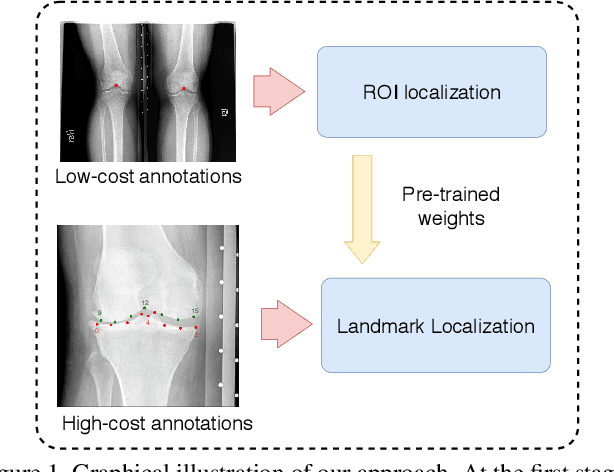
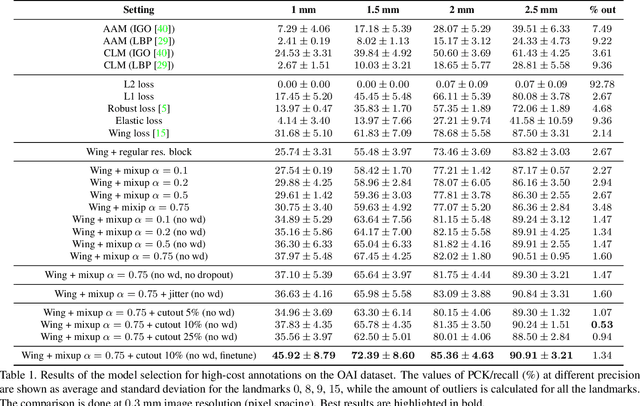
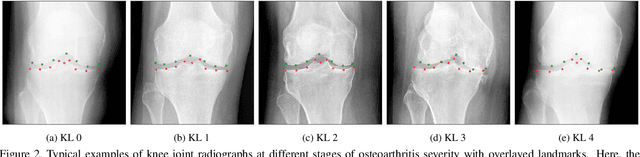
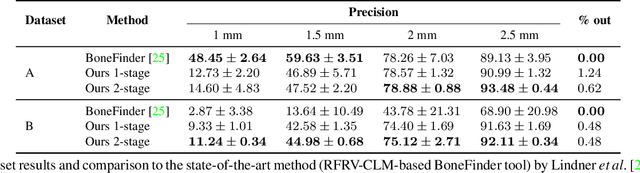
This paper addresses the challenge of localization of anatomical landmarks in knee X-ray images at different stages of osteoarthritis (OA). Landmark localization can be viewed as regression problem, where the landmark position is directly predicted by using the region of interest or even full-size images leading to large memory footprint, especially in case of high resolution medical images. In this work, we propose an efficient deep neural networks framework with an hourglass architecture utilizing a soft-argmax layer to directly predict normalized coordinates of the landmark points. We provide an extensive evaluation of different regularization techniques and various loss functions to understand their influence on the localization performance. Furthermore, we introduce the concept of transfer learning from low-budget annotations, and experimentally demonstrate that such approach is improving the accuracy of landmark localization. Compared to the prior methods, we validate our model on two datasets that are independent from the train data and assess the performance of the method for different stages of OA severity. The proposed approach demonstrates better generalization performance compared to the current state-of-the-art.
Bayesian Feature Pyramid Networks for Automatic Multi-Label Segmentation of Chest X-rays and Assessment of Cardio-Thoratic Ratio
Aug 08, 2019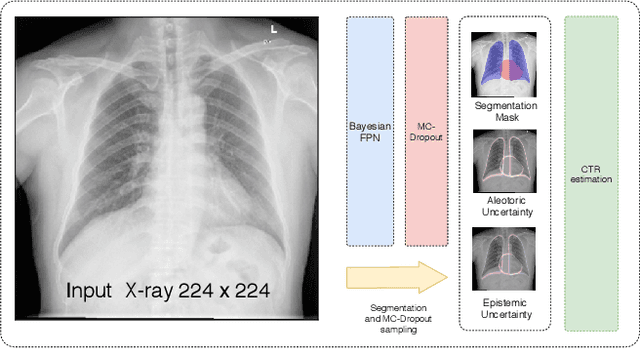
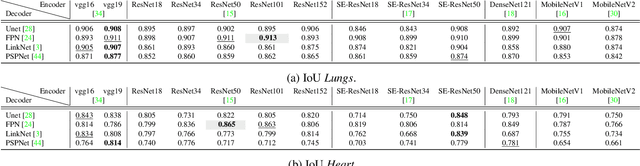
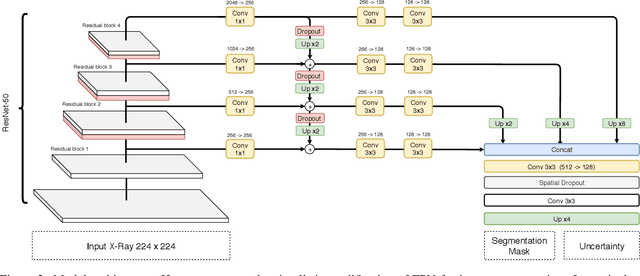
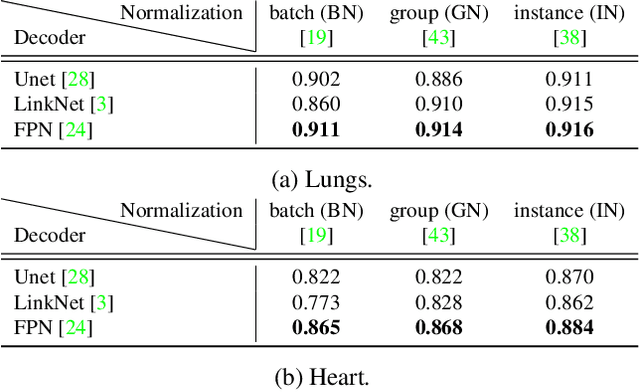
Cardiothoratic ratio (CTR) estimated from chest radiographs is a marker indicative of cardiomegaly, the presence of which is in the criteria for heart failure diagnosis. Existing methods for automatic assessment of CTR are driven by Deep Learning-based segmentation. However, these techniques produce only point estimates of CTR but clinical decision making typically assumes the uncertainty. In this paper, we propose a novel method for chest X-ray segmentation and CTR assessment in an automatic manner. In contrast to the previous art, we, for the first time, propose to estimate CTR with uncertainty bounds. Our method is based on Deep Convolutional Neural Network with Feature Pyramid Network (FPN) decoder. We propose two modifications of FPN: replace the batch normalization with instance normalization and inject the dropout which allows to obtain the Monte-Carlo estimates of the segmentation maps at test time. Finally, using the predicted segmentation mask samples, we estimate CTR with uncertainty. In our experiments we demonstrate that the proposed method generalizes well to three different test sets. Finally, we make the annotations produced by two radiologists for all our datasets publicly available.
Geometric Image Correspondence Verification by Dense Pixel Matching
Apr 15, 2019
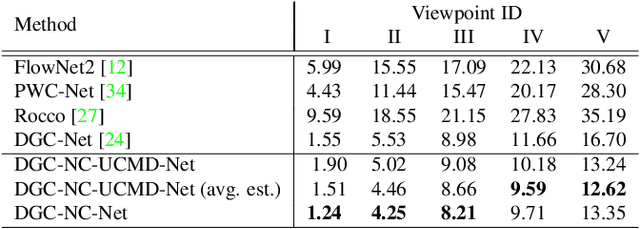
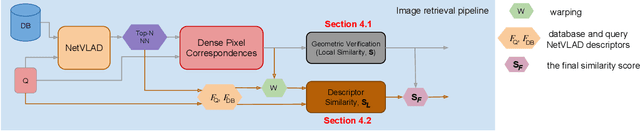
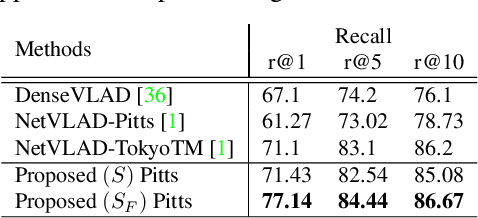
This paper addresses the problem of determining dense pixel correspondences between two images and its application to geometric correspondence verification in image retrieval. The main contribution is a geometric correspondence verification approach for re-ranking a shortlist of retrieved database images based on their dense pair-wise matching with the query image at a pixel level. We determine a set of cyclically consistent dense pixel matches between the pair of images and evaluate local similarity of matched pixels using neural network based image descriptors. Final re-ranking is based on a novel similarity function, which fuses the local similarity metric with a global similarity metric and a geometric consistency measure computed for the matched pixels. For dense matching our approach utilizes a modified version of a recently proposed dense geometric correspondence network (DGC-Net), which we also improve by optimizing the architecture. The proposed model and similarity metric compare favourably to the state-of-the-art image retrieval methods. In addition, we apply our method to the problem of long-term visual localization demonstrating promising results and generalization across datasets.
DGC-Net: Dense Geometric Correspondence Network
Oct 22, 2018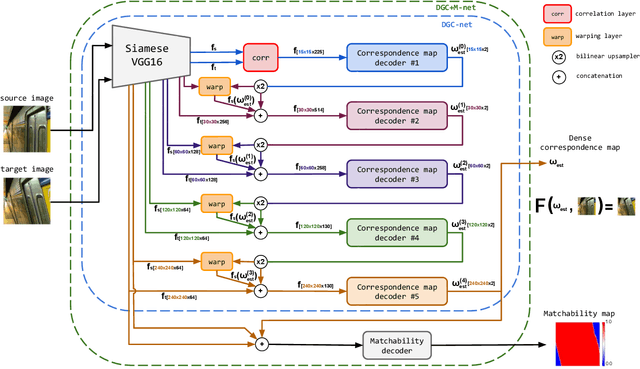
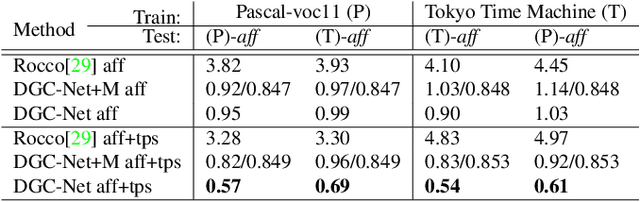

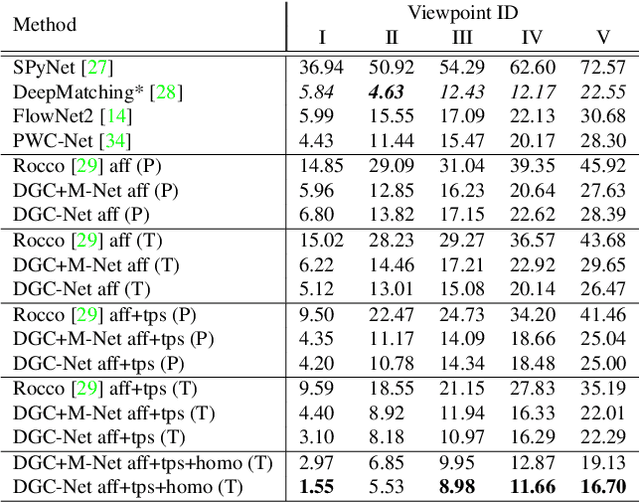
This paper addresses the challenge of dense pixel correspondence estimation between two images. This problem is closely related to optical flow estimation task where ConvNets (CNNs) have recently achieved significant progress. While optical flow methods produce very accurate results for the small pixel translation and limited appearance variation scenarios, they hardly deal with the strong geometric transformations that we consider in this work. In this paper, we propose a coarse-to-fine CNN-based framework that can leverage the advantages of optical flow approaches and extend them to the case of large transformations providing dense and subpixel accurate estimates. It is trained on synthetic transformations and demonstrates very good performance to unseen, realistic, data. Further, we apply our method to the problem of relative camera pose estimation and demonstrate that the model outperforms existing dense approaches.
Image Patch Matching Using Convolutional Descriptors with Euclidean Distance
Oct 31, 2017
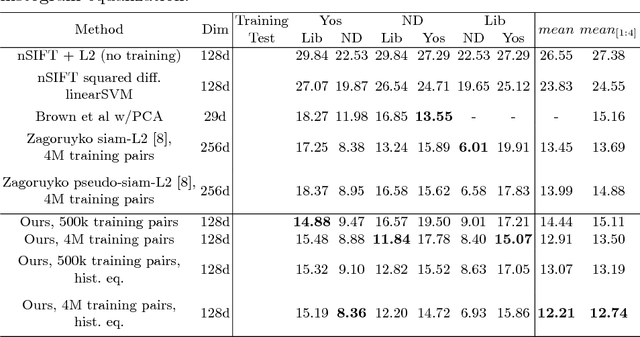
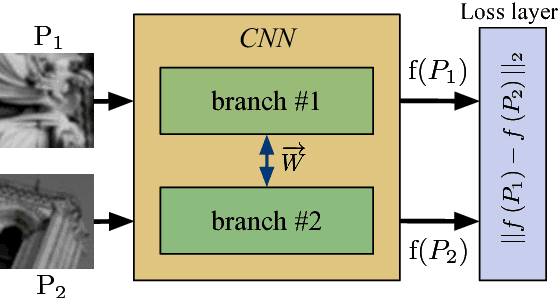
In this work we propose a neural network based image descriptor suitable for image patch matching, which is an important task in many computer vision applications. Our approach is influenced by recent success of deep convolutional neural networks (CNNs) in object detection and classification tasks. We develop a model which maps the raw input patch to a low dimensional feature vector so that the distance between representations is small for similar patches and large otherwise. As a distance metric we utilize L2 norm, i.e. Euclidean distance, which is fast to evaluate and used in most popular hand-crafted descriptors, such as SIFT. According to the results, our approach outperforms state-of-the-art L2-based descriptors and can be considered as a direct replacement of SIFT. In addition, we conducted experiments with batch normalization and histogram equalization as a preprocessing method of the input data. The results confirm that these techniques further improve the performance of the proposed descriptor. Finally, we show promising preliminary results by appending our CNNs with recently proposed spatial transformer networks and provide a visualisation and interpretation of their impact.