 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing CQ lower-bounds over OWL 2 through approximation to RSA
Jul 01, 2021



Conjunctive query (CQ) answering over knowledge bases is an important reasoning task. However, with expressive ontology languages such as OWL, query answering is computationally very expensive. The PAGOdA system addresses this issue by using a tractable reasoner to compute lower and upper-bound approximations, falling back to a fully-fledged OWL reasoner only when these bounds don't coincide. The effectiveness of this approach critically depends on the quality of the approximations, and in this paper we explore a technique for computing closer approximations via RSA, an ontology language that subsumes all the OWL 2 profiles while still maintaining tractability. We present a novel approximation of OWL 2 ontologies into RSA, and an algorithm to compute a closer (than PAGOdA) lower bound approximation using the RSA combined approach. We have implemented these algorithms in a prototypical CQ answering system, and we present a preliminary evaluation of our system that shows significant performance improvements w.r.t. PAGOdA.
Knowledge-aware Zero-Shot Learning: Survey and Perspective
Feb 26, 2021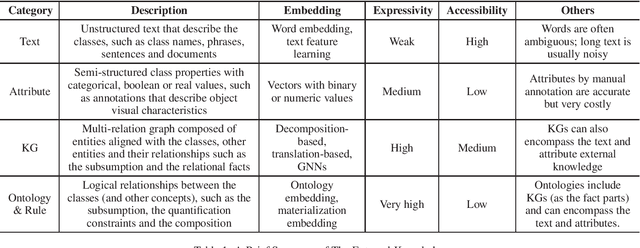
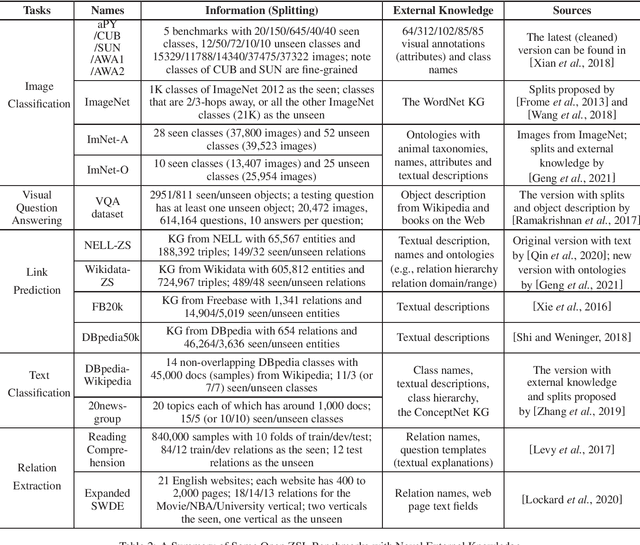
Zero-shot learning (ZSL) which aims at predicting classes that have never appeared during the training using external knowledge (a.k.a. side information) has been widely investigated. In this paper we present a literature review towards ZSL in the perspective of external knowledge, where we categorize the external knowledge, review their methods and compare different external knowledge. With the literature review, we further discuss and outlook the role of symbolic knowledge in addressing ZSL and other machine learning sample shortage issues.
OWL2Vec*: Embedding of OWL Ontologies
Sep 30, 2020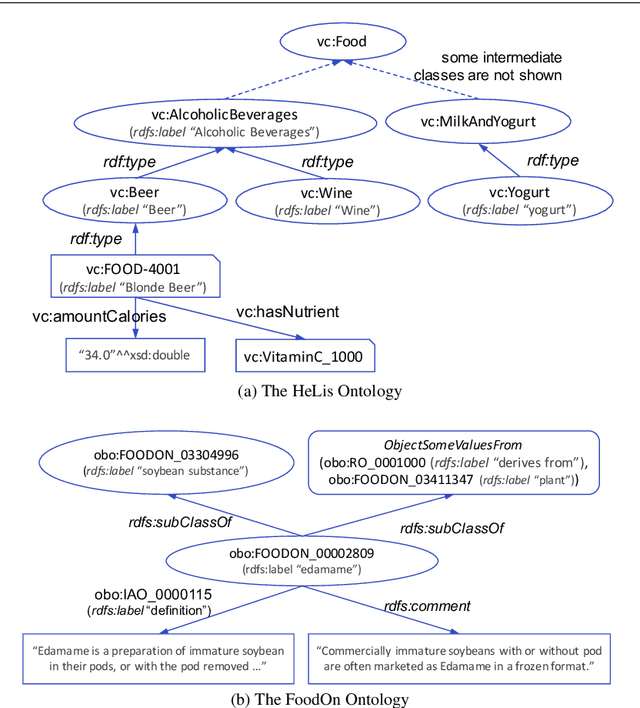

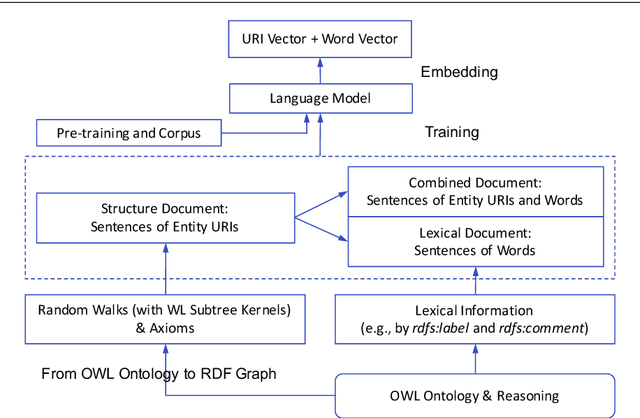

Semantic embedding of knowledge graphs has been widely studied and used for prediction and statistical analysis tasks across various domains such as Natural Language Processing and the Semantic Web. However, less attention has been paid to developing robust methods for embedding OWL (Web Ontology Language) ontologies. In this paper, we propose a language model based ontology embedding method named OWL2Vec*, which encodes the semantics of an ontology by taking into account its graph structure, lexical information and logic constructors. Our empirical evaluation with three real world datasets suggests that OWL2Vec* benefits from these three different aspects of an ontology in class membership prediction and class subsumption prediction tasks. Furthermore, OWL2Vec* often significantly outperforms the state-of-the-art methods in our experiments.
Correcting Knowledge Base Assertions
Jan 19, 2020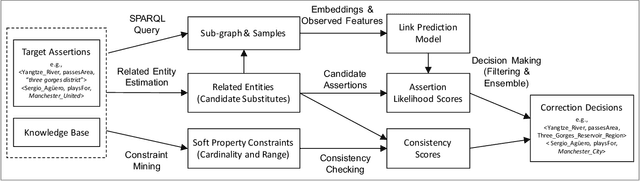
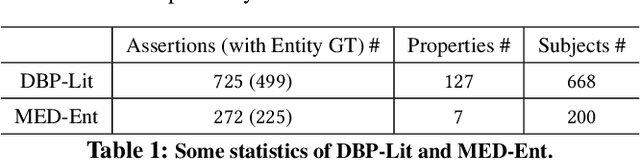
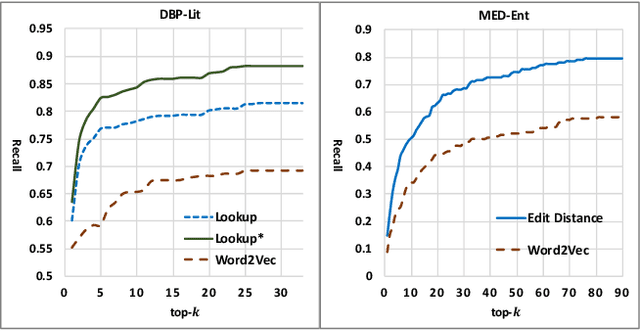
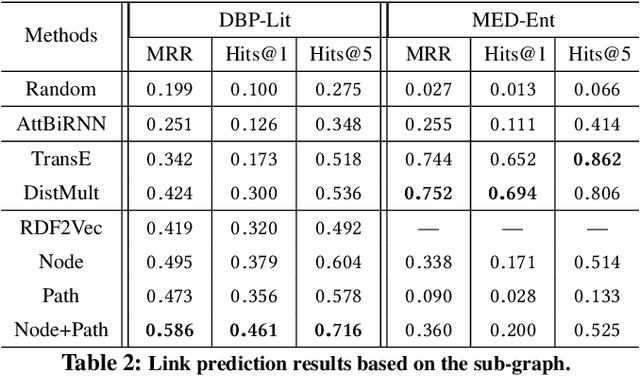
The usefulness and usability of knowledge bases (KBs) is often limited by quality issues. One common issue is the presence of erroneous assertions, often caused by lexical or semantic confusion. We study the problem of correcting such assertions, and present a general correction framework which combines lexical matching, semantic embedding, soft constraint mining and semantic consistency checking. The framework is evaluated using DBpedia and an enterprise medical KB.
Datalog Reasoning over Compressed RDF Knowledge Bases
Aug 29, 2019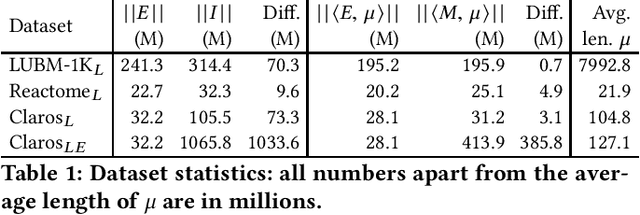


Materialisation is often used in RDF systems as a preprocessing step to derive all facts implied by given RDF triples and rules. Although widely used, materialisation considers all possible rule applications and can use a lot of memory for storing the derived facts, which can hinder performance. We present a novel materialisation technique that compresses the RDF triples so that the rules can sometimes be applied to multiple facts at once, and the derived facts can be represented using structure sharing. Our technique can thus require less space, as well as skip certain rule applications. Our experiments show that our technique can be very effective: when the rules are relatively simple, our system is both faster and requires less memory than prominent state-of-the-art RDF systems.
Canonicalizing Knowledge Base Literals
Jun 26, 2019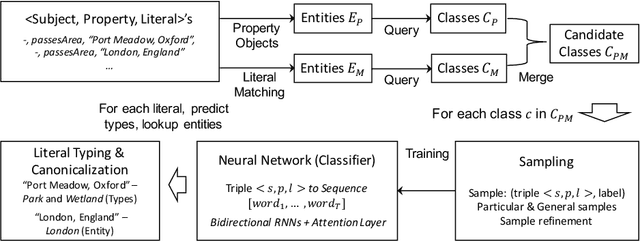

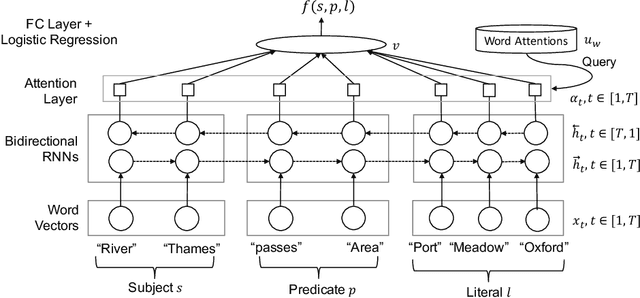
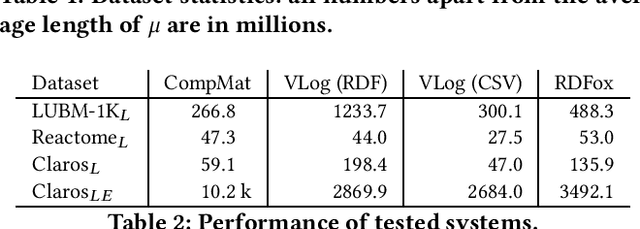
Ontology-based knowledge bases (KBs) like DBpedia are very valuable resources, but their usefulness and usability is limited by various quality issues. One such issue is the use of string literals instead of semantically typed entities. In this paper we study the automated canonicalization of such literals, i.e., replacing the literal with an existing entity from the KB or with a new entity that is typed using classes from the KB. We propose a framework that combines both reasoning and machine learning in order to predict the relevant entities and types, and we evaluate this framework against state-of-the-art baselines for both semantic typing and entity matching.
Learning Semantic Annotations for Tabular Data
May 30, 2019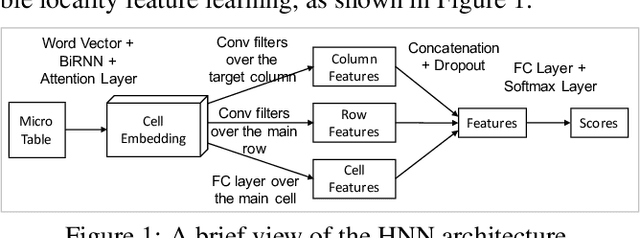
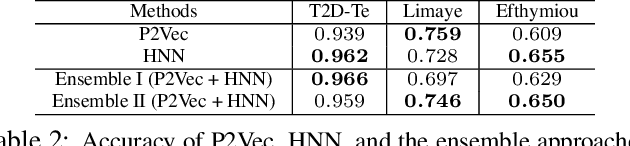
The usefulness of tabular data such as web tables critically depends on understanding their semantics. This study focuses on column type prediction for tables without any meta data. Unlike traditional lexical matching-based methods, we propose a deep prediction model that can fully exploit a table's contextual semantics, including table locality features learned by a Hybrid Neural Network (HNN), and inter-column semantics features learned by a knowledge base (KB) lookup and query answering algorithm.It exhibits good performance not only on individual table sets, but also when transferring from one table set to another.
* 7 pages
Modular Materialisation of Datalog Programs
Nov 13, 2018
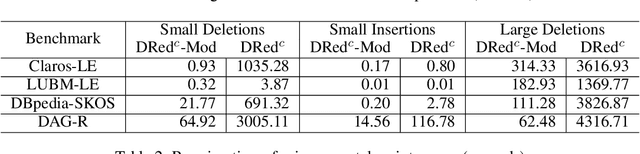
The semina\"ive algorithm can materialise all consequences of arbitrary datalog rules, and it also forms the basis for incremental algorithms that update a materialisation as the input facts change. Certain (combinations of) rules, however, can be handled much more efficiently using custom algorithms. To integrate such algorithms into a general reasoning approach that can handle arbitrary rules, we propose a modular framework for materialisation computation and its maintenance. We split a datalog program into modules that can be handled using specialised algorithms, and handle the remaining rules using the semina\"ive algorithm. We also present two algorithms for computing the transitive and the symmetric-transitive closure of a relation that can be used within our framework. Finally, we show empirically that our framework can handle arbitrary datalog programs while outperforming existing approaches, often by orders of magnitude.
ColNet: Embedding the Semantics of Web Tables for Column Type Prediction
Nov 04, 2018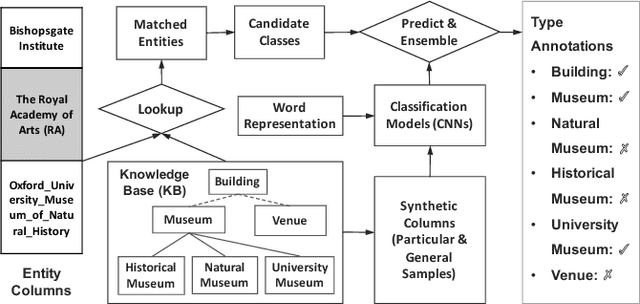

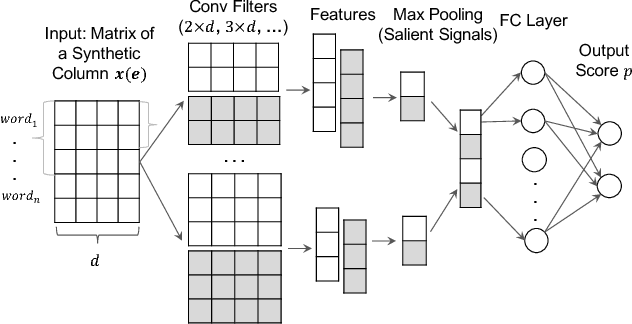
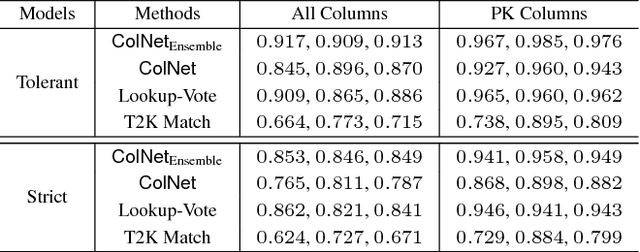
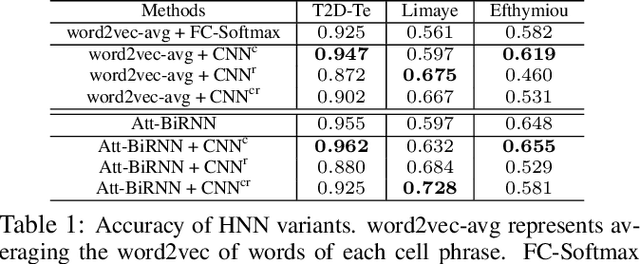
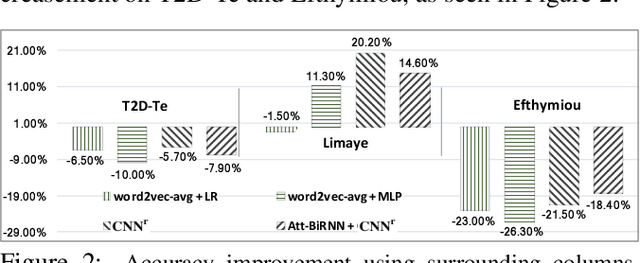
Automatically annotating column types with knowledge base (KB) concepts is a critical task to gain a basic understanding of web tables. Current methods rely on either table metadata like column name or entity correspondences of cells in the KB, and may fail to deal with growing web tables with incomplete meta information. In this paper we propose a neural network based column type annotation framework named ColNet which is able to integrate KB reasoning and lookup with machine learning and can automatically train Convolutional Neural Networks for prediction. The prediction model not only considers the contextual semantics within a cell using word representation, but also embeds the semantic of a column by learning locality features from multiple cells. The method is evaluated with DBPedia and two different web table datasets, T2Dv2 from the general Web and Limaye from Wikipedia pages, and achieves higher performance than the state-of-the-art approaches.
The Window Validity Problem in Rule-Based Stream Reasoning
Aug 07, 2018Rule-based temporal query languages provide the expressive power and flexibility required to capture in a natural way complex analysis tasks over streaming data. Stream processing applications, however, typically require near real-time response using limited resources. In particular, it becomes essential that the underpinning query language has favourable computational properties and that stream processing algorithms are able to keep only a small number of previously received facts in memory at any point in time without sacrificing correctness. In this paper, we propose a recursive fragment of temporal Datalog with tractable data complexity and study the properties of a generic stream reasoning algorithm for this fragment. We focus on the window validity problem as a way to minimise the number of time points for which the stream reasoning algorithm needs to keep data in memory at any point in time.