 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Deep Constrained Clustering
Jan 07, 2021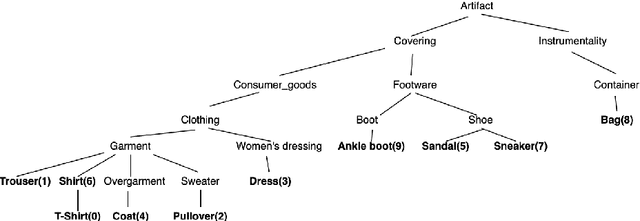

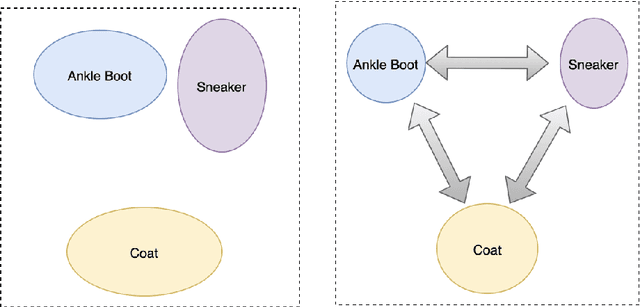
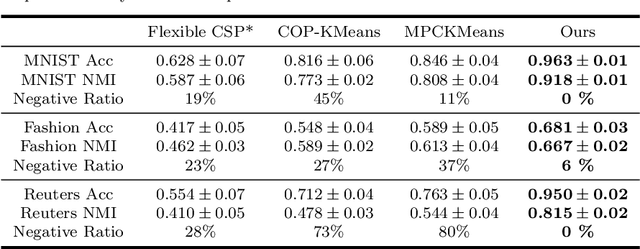
The area of constrained clustering has been extensively explored by researchers and used by practitioners. Constrained clustering formulations exist for popular algorithms such as k-means, mixture models, and spectral clustering but have several limitations. A fundamental strength of deep learning is its flexibility, and here we explore a deep learning framework for constrained clustering and in particular explore how it can extend the field of constrained clustering. We show that our framework can not only handle standard together/apart constraints (without the well documented negative effects reported earlier) generated from labeled side information but more complex constraints generated from new types of side information such as continuous values and high-level domain knowledge. Furthermore, we propose an efficient training paradigm that is generally applicable to these four types of constraints. We validate the effectiveness of our approach by empirical results on both image and text datasets. We also study the robustness of our framework when learning with noisy constraints and show how different components of our framework contribute to the final performance. Our source code is available at $\href{https://github.com/blueocean92/deep_constrained_clustering}{\text{URL}}$.
Towards Fair Deep Anomaly Detection
Dec 29, 2020


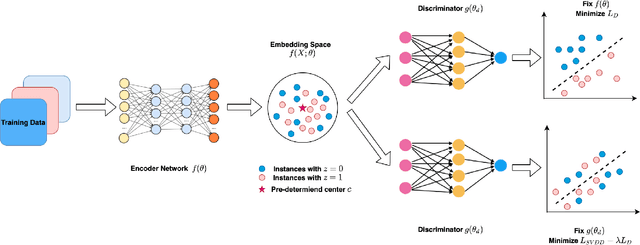
Anomaly detection aims to find instances that are considered unusual and is a fundamental problem of data science. Recently, deep anomaly detection methods were shown to achieve superior results particularly in complex data such as images. Our work focuses on deep one-class classification for anomaly detection which learns a mapping only from the normal samples. However, the non-linear transformation performed by deep learning can potentially find patterns associated with social bias. The challenge with adding fairness to deep anomaly detection is to ensure both making fair and correct anomaly predictions simultaneously. In this paper, we propose a new architecture for the fair anomaly detection approach (Deep Fair SVDD) and train it using an adversarial network to de-correlate the relationships between the sensitive attributes and the learned representations. This differs from how fairness is typically added namely as a regularizer or a constraint. Further, we propose two effective fairness measures and empirically demonstrate that existing deep anomaly detection methods are unfair. We show that our proposed approach can remove the unfairness largely with minimal loss on the anomaly detection performance. Lastly, we conduct an in-depth analysis to show the strength and limitations of our proposed model, including parameter analysis, feature visualization, and run-time analysis.
Block Model Guided Unsupervised Feature Selection
Jul 05, 2020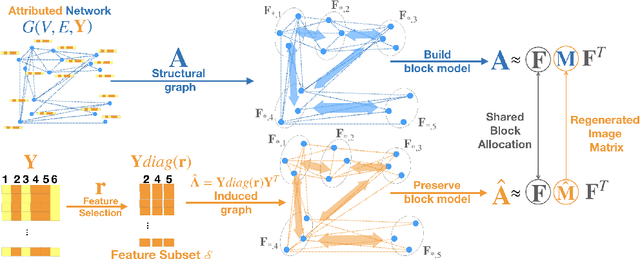
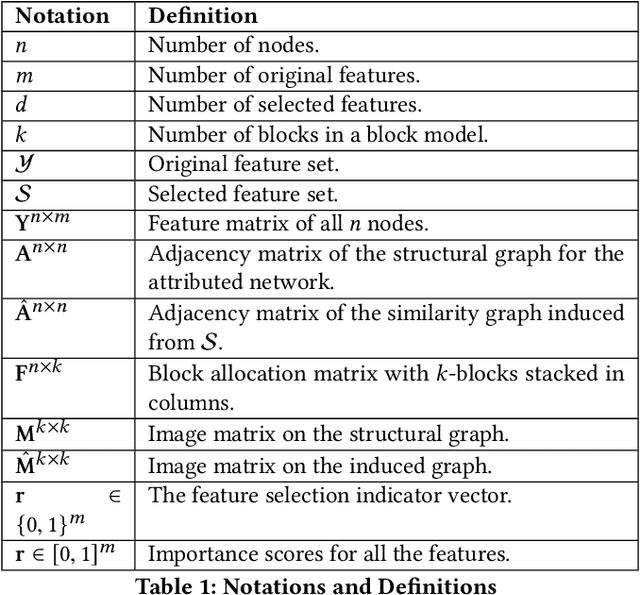
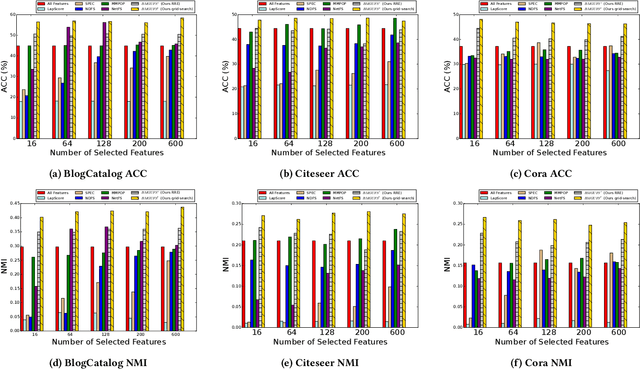
Feature selection is a core area of data mining with a recent innovation of graph-driven unsupervised feature selection for linked data. In this setting we have a dataset $\mathbf{Y}$ consisting of $n$ instances each with $m$ features and a corresponding $n$ node graph (whose adjacency matrix is $\mathbf{A}$) with an edge indicating that the two instances are similar. Existing efforts for unsupervised feature selection on attributed networks have explored either directly regenerating the links by solving for $f$ such that $f(\mathbf{y}_i,\mathbf{y}_j) \approx \mathbf{A}_{i,j}$ or finding community structure in $\mathbf{A}$ and using the features in $\mathbf{Y}$ to predict these communities. However, graph-driven unsupervised feature selection remains an understudied area with respect to exploring more complex guidance. Here we take the novel approach of first building a block model on the graph and then using the block model for feature selection. That is, we discover $\mathbf{F}\mathbf{M}\mathbf{F}^T \approx \mathbf{A}$ and then find a subset of features $\mathcal{S}$ that induces another graph to preserve both $\mathbf{F}$ and $\mathbf{M}$. We call our approach Block Model Guided Unsupervised Feature Selection (BMGUFS). Experimental results show that our method outperforms the state of the art on several real-world public datasets in finding high-quality features for clustering.
* Published at KDD2020
Efficient Algorithms for Generating Provably Near-Optimal Cluster Descriptors for Explainability
Feb 06, 2020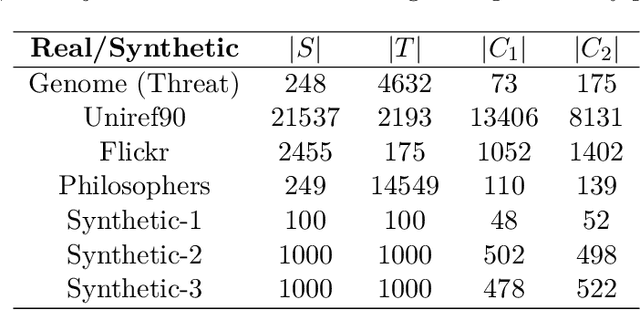
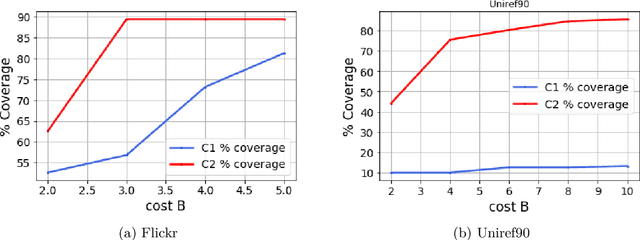
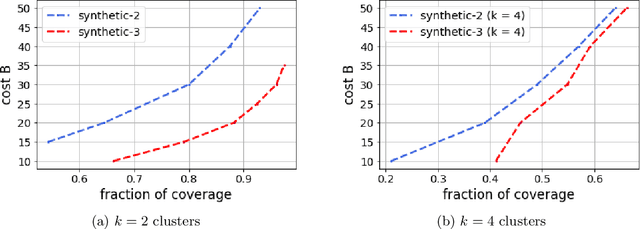
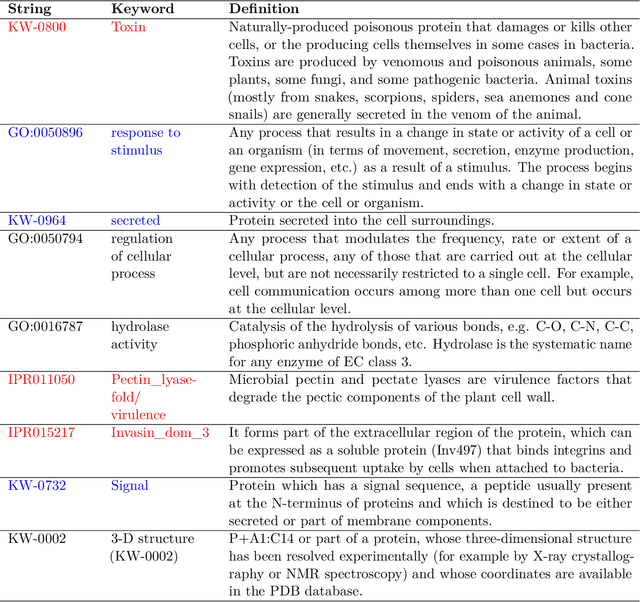
Improving the explainability of the results from machine learning methods has become an important research goal. Here, we study the problem of making clusters more interpretable by extending a recent approach of [Davidson et al., NeurIPS 2018] for constructing succinct representations for clusters. Given a set of objects $S$, a partition $\pi$ of $S$ (into clusters), and a universe $T$ of tags such that each element in $S$ is associated with a subset of tags, the goal is to find a representative set of tags for each cluster such that those sets are pairwise-disjoint and the total size of all the representatives is minimized. Since this problem is NP-hard in general, we develop approximation algorithms with provable performance guarantees for the problem. We also show applications to explain clusters from datasets, including clusters of genomic sequences that represent different threat levels.
A Graph-Based Approach for Active Learning in Regression
Jan 30, 2020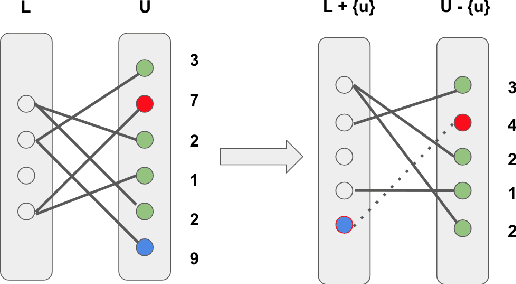
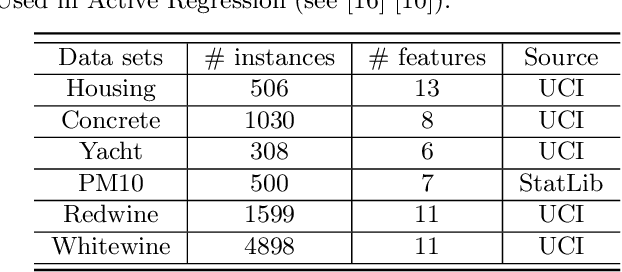
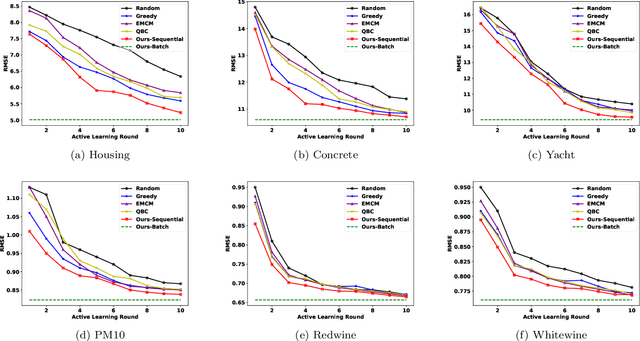
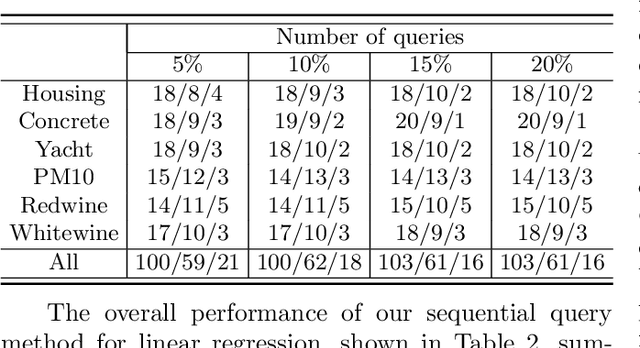
Active learning aims to reduce labeling efforts by selectively asking humans to annotate the most important data points from an unlabeled pool and is an example of human-machine interaction. Though active learning has been extensively researched for classification and ranking problems, it is relatively understudied for regression problems. Most existing active learning for regression methods use the regression function learned at each active learning iteration to select the next informative point to query. This introduces several challenges such as handling noisy labels, parameter uncertainty and overcoming initially biased training data. Instead, we propose a feature-focused approach that formulates both sequential and batch-mode active regression as a novel bipartite graph optimization problem. We conduct experiments on both noise-free and noisy settings. Our experimental results on benchmark data sets demonstrate the effectiveness of our proposed approach.
Coverage-based Outlier Explanation
Nov 06, 2019
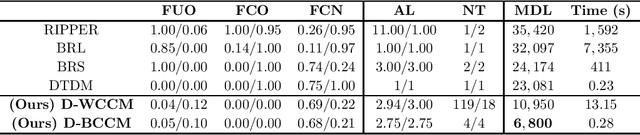

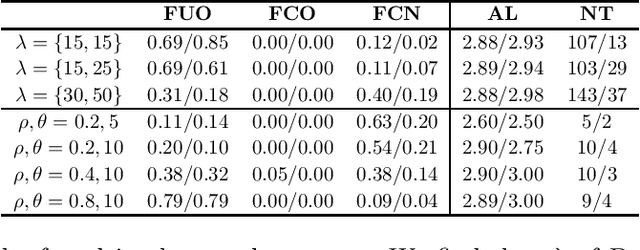
Outlier detection is a core task in data mining with a plethora of algorithms that have enjoyed wide scale usage. Existing algorithms are primarily focused on detection, that is the identification of outliers in a given dataset. In this paper we explore the relatively under-studied problem of the outlier explanation problem. Our goal is, given a dataset that is already divided into outliers and normal instances, explain what characterizes the outliers. We explore the novel direction of a semantic explanation that a domain expert or policy maker is able to understand. We formulate this as an optimization problem to find explanations that are both interpretable and pure. Through experiments on real-world data sets, we quantitatively show that our method can efficiently generate better explanations compared with rule-based learners.
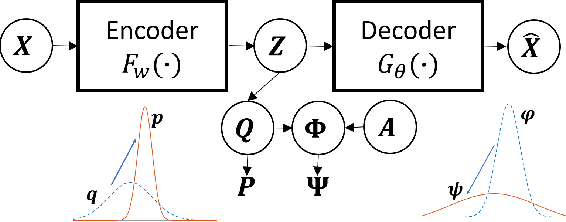
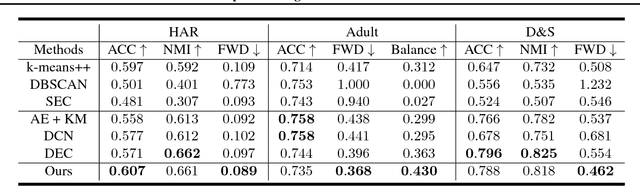
Deep Constrained Clustering - Algorithms and Advances
Jan 29, 2019


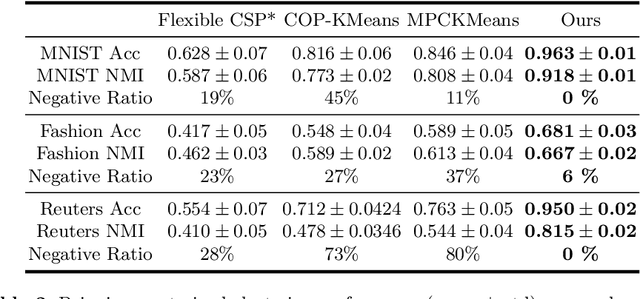
The area of constrained clustering has been extensively explored by researchers and used by practitioners. Constrained clustering formulations exist for popular algorithms such as k-means, mixture models, and spectral clustering but have several limitations. We explore a deep learning formulation of constrained clustering and in particular explore how it can extend the field of constrained clustering. We show that our formulation can not only handle standard together/apart constraints without the well documented negative effects reported but can also model instance level constraints (level-of-difficulty), cluster level constraints (balancing cluster size) and triplet constraints. The first two are new ways for domain experts to enforce guidance whilst the later importantly allows generating ordering constraints from continuous side-information.
Towards Fair Deep Clustering With Multi-State Protected Variables
Jan 29, 2019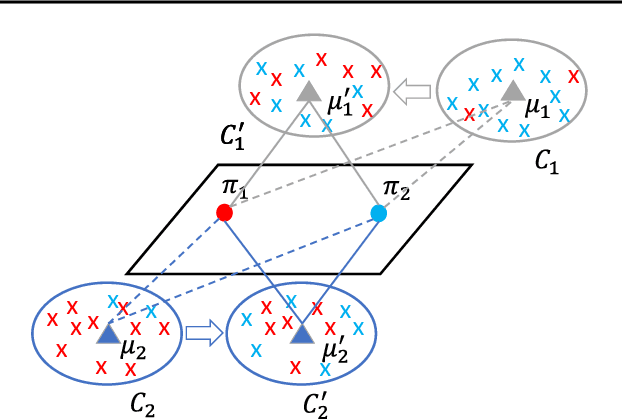

Fair clustering under the disparate impact doctrine requires that population of each protected group should be approximately equal in every cluster. Previous work investigated a difficult-to-scale pre-processing step for $k$-center and $k$-median style algorithms for the special case of this problem when the number of protected groups is two. In this work, we consider a more general and practical setting where there can be many protected groups. To this end, we propose Deep Fair Clustering, which learns a discriminative but fair cluster assignment function. The experimental results on three public datasets with different types of protected attribute show that our approach can steadily improve the degree of fairness while only having minor loss in terms of clustering quality.
On The Equivalence of Tries and Dendrograms - Efficient Hierarchical Clustering of Traffic Data
Oct 12, 2018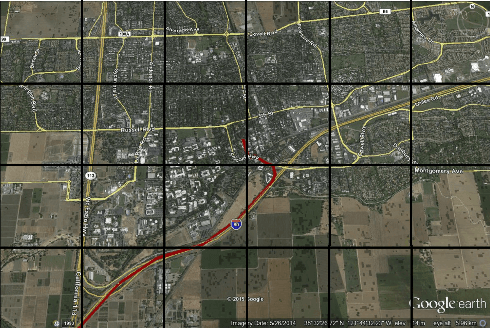
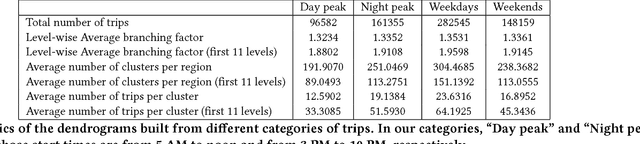
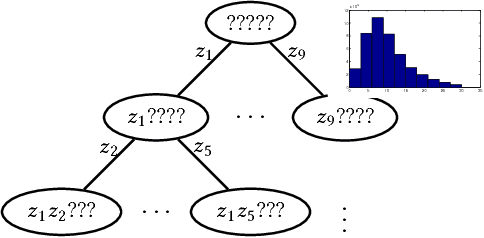

The widespread use of GPS-enabled devices generates voluminous and continuous amounts of traffic data but analyzing such data for interpretable and actionable insights poses challenges. A hierarchical clustering of the trips has many uses such as discovering shortest paths, common routes and often traversed areas. However, hierarchical clustering typically has time complexity of $O(n^2 \log n)$ where $n$ is the number of instances, and is difficult to scale to large data sets associated with GPS data. Furthermore, incremental hierarchical clustering is still a developing area. Prefix trees (also called tries) can be efficiently constructed and updated in linear time (in $n$). We show how a specially constructed trie can compactly store the trips and further show this trie is equivalent to a dendrogram that would have been built by classic agglomerative hierarchical algorithms using a specific distance metric. This allows creating hierarchical clusterings of GPS trip data and updating this hierarchy in linear time. %we can extract a meaningful kernel and can also interpret the structure as clusterings of differing granularity as one progresses down the tree. We demonstrate the usefulness of our proposed approach on a real world data set of half a million taxis' GPS traces, well beyond the capabilities of agglomerative clustering methods. Our work is not limited to trip data and can be used with other data with a string representation.
Probabilistic Formulations of Regression with Mixed Guidance
Apr 01, 2018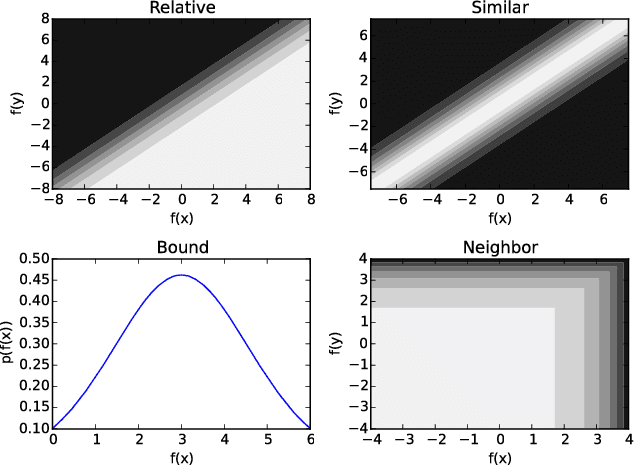
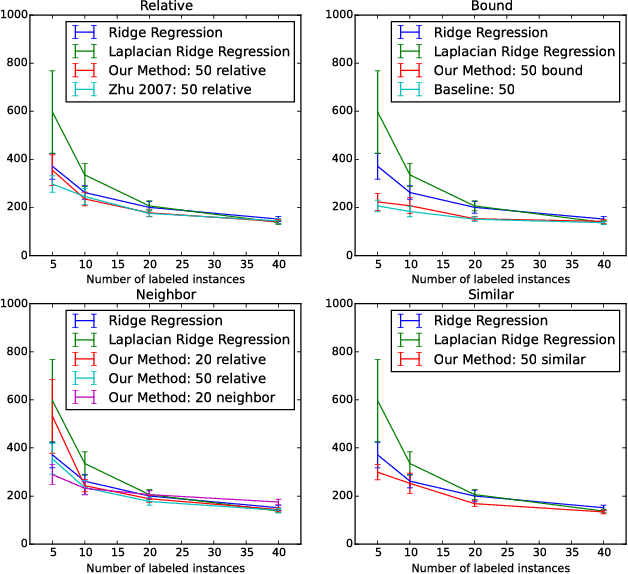
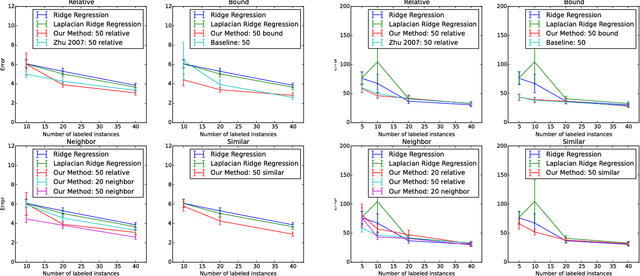
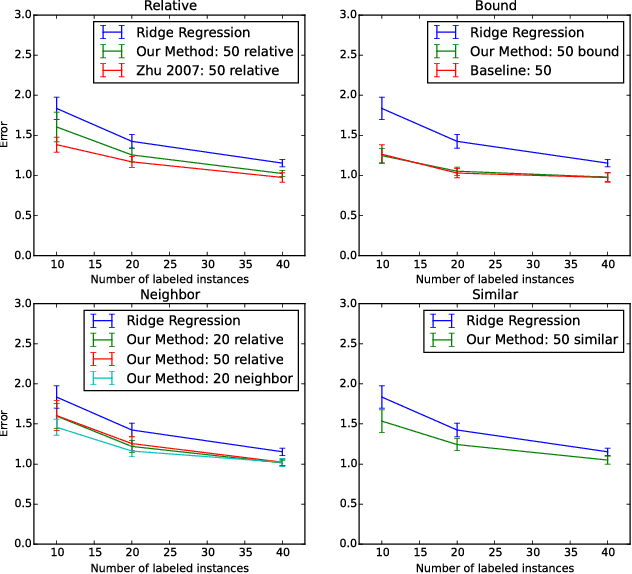
Regression problems assume every instance is annotated (labeled) with a real value, a form of annotation we call \emph{strong guidance}. In order for these annotations to be accurate, they must be the result of a precise experiment or measurement. However, in some cases additional \emph{weak guidance} might be given by imprecise measurements, a domain expert or even crowd sourcing. Current formulations of regression are unable to use both types of guidance. We propose a regression framework that can also incorporate weak guidance based on relative orderings, bounds, neighboring and similarity relations. Consider learning to predict ages from portrait images, these new types of guidance allow weaker forms of guidance such as stating a person is in their 20s or two people are similar in age. These types of annotations can be easier to generate than strong guidance. We introduce a probabilistic formulation for these forms of weak guidance and show that the resulting optimization problems are convex. Our experimental results show the benefits of these formulations on several data sets.