 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlock Model Guided Unsupervised Feature Selection
Paper and Code
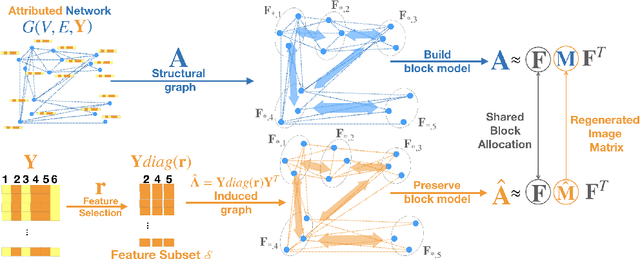
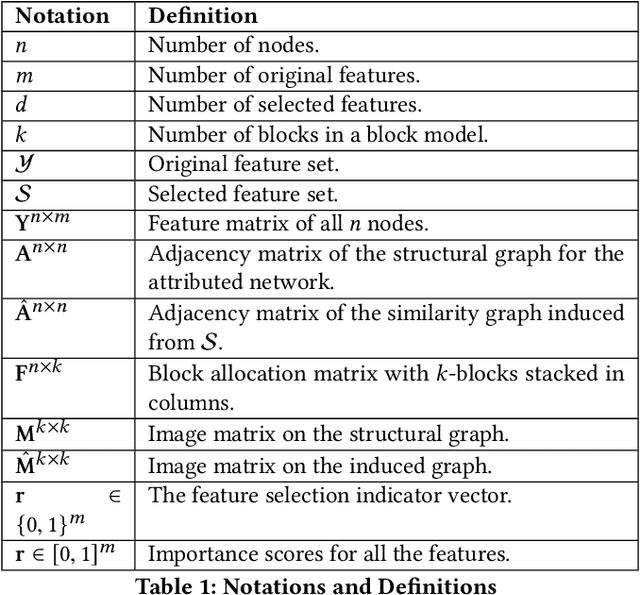
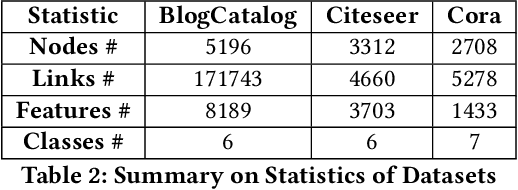
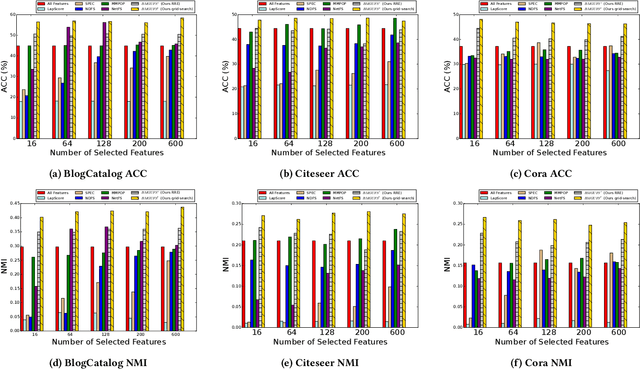
Feature selection is a core area of data mining with a recent innovation of graph-driven unsupervised feature selection for linked data. In this setting we have a dataset $\mathbf{Y}$ consisting of $n$ instances each with $m$ features and a corresponding $n$ node graph (whose adjacency matrix is $\mathbf{A}$) with an edge indicating that the two instances are similar. Existing efforts for unsupervised feature selection on attributed networks have explored either directly regenerating the links by solving for $f$ such that $f(\mathbf{y}_i,\mathbf{y}_j) \approx \mathbf{A}_{i,j}$ or finding community structure in $\mathbf{A}$ and using the features in $\mathbf{Y}$ to predict these communities. However, graph-driven unsupervised feature selection remains an understudied area with respect to exploring more complex guidance. Here we take the novel approach of first building a block model on the graph and then using the block model for feature selection. That is, we discover $\mathbf{F}\mathbf{M}\mathbf{F}^T \approx \mathbf{A}$ and then find a subset of features $\mathcal{S}$ that induces another graph to preserve both $\mathbf{F}$ and $\mathbf{M}$. We call our approach Block Model Guided Unsupervised Feature Selection (BMGUFS). Experimental results show that our method outperforms the state of the art on several real-world public datasets in finding high-quality features for clustering.