 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath Planning for Shepherding a Swarm in a Cluttered Environment using Differential Evolution
Aug 28, 2020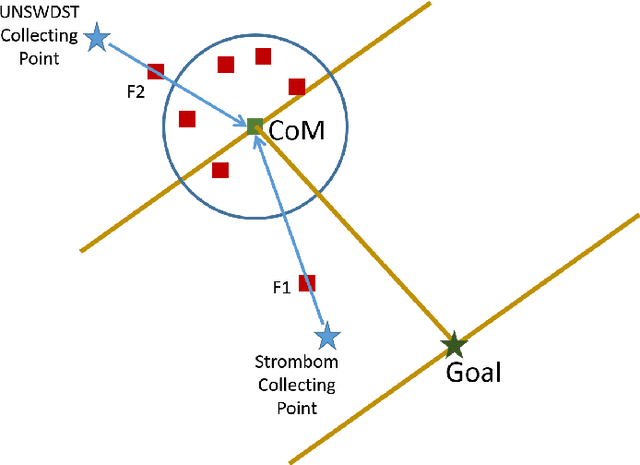
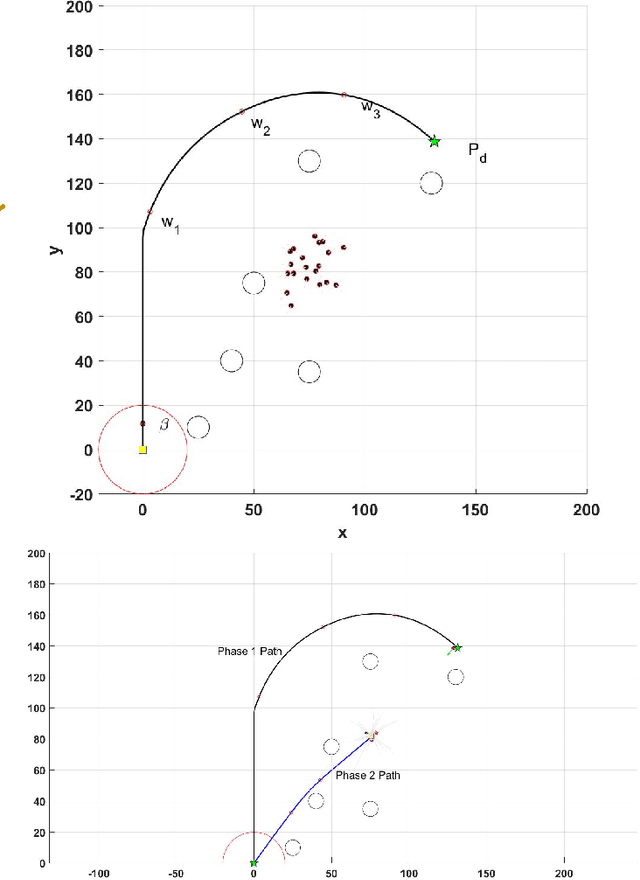
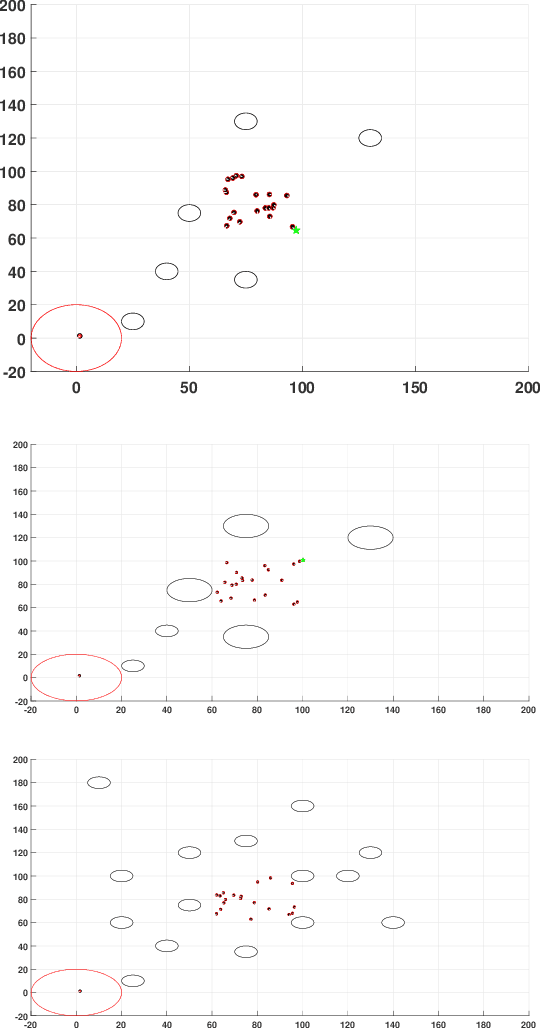
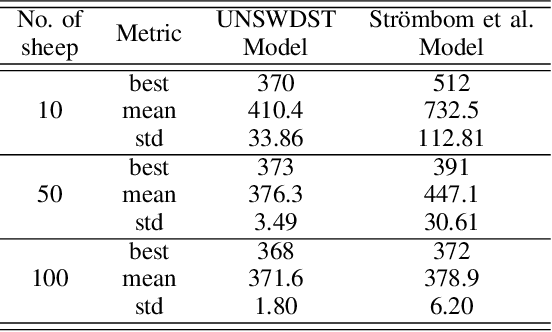
Shepherding involves herding a swarm of agents (\emph{sheep}) by another a control agent (\emph{sheepdog}) towards a goal. Multiple approaches have been documented in the literature to model this behaviour. In this paper, we present a modification to a well-known shepherding approach, and show, via simulation, that this modification improves shepherding efficacy. We then argue that given complexity arising from obstacles laden environments, path planning approaches could further enhance this model. To validate this hypothesis, we present a 2-stage evolutionary-based path planning algorithm for shepherding a swarm of agents in 2D environments. In the first stage, the algorithm attempts to find the best path for the sheepdog to move from its initial location to a strategic driving location behind the sheep. In the second stage, it calculates and optimises a path for the sheep. It does so by using \emph{way points} on that path as the sequential sub-goals for the sheepdog to aim towards. The proposed algorithm is evaluated in obstacle laden environments via simulation with further improvements achieved.
A Comprehensive Review of Shepherding as a Bio-inspired Swarm-Robotics Guidance Approach
Dec 18, 2019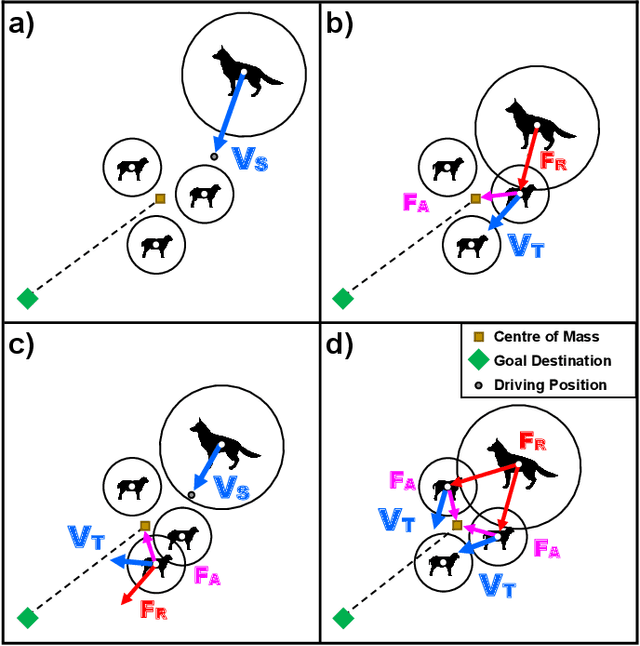
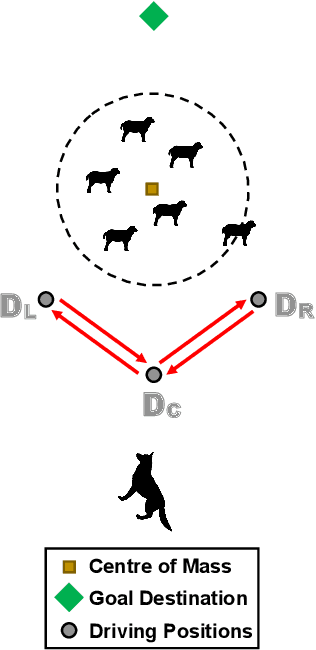
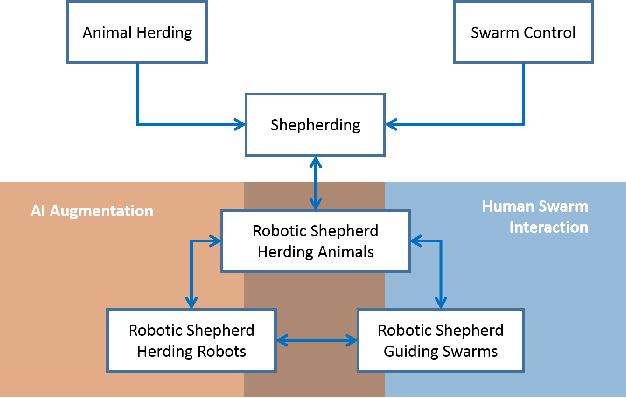
The simultaneous control of multiple coordinated robotic agents represents an elaborate problem. If solved, however, the interaction between the agents can lead to solutions to sophisticated problems. The concept of swarming, inspired by nature, can be described as the emergence of complex system-level behaviors from the interactions of relatively elementary agents. Due to the effectiveness of solutions found in nature, bio-inspired swarming-based control techniques are receiving a lot of attention in robotics. One method, known as swarm shepherding, is founded on the sheep herding behavior exhibited by sheepdogs, where a swarm of relatively simple agents are governed by a shepherd (or shepherds) which is responsible for high-level guidance and planning. Many studies have been conducted on shepherding as a control technique, ranging from the replication of sheep herding via simulation, to the control of uninhabited vehicles and robots for a variety of applications. We present a comprehensive review of the literature on swarm shepherding to reveal the advantages and potential of the approach to be applied to a plethora of robotic systems in the future.
Machine Teaching in Hierarchical Genetic Reinforcement Learning: Curriculum Design of Reward Functions for Swarm Shepherding
Jan 04, 2019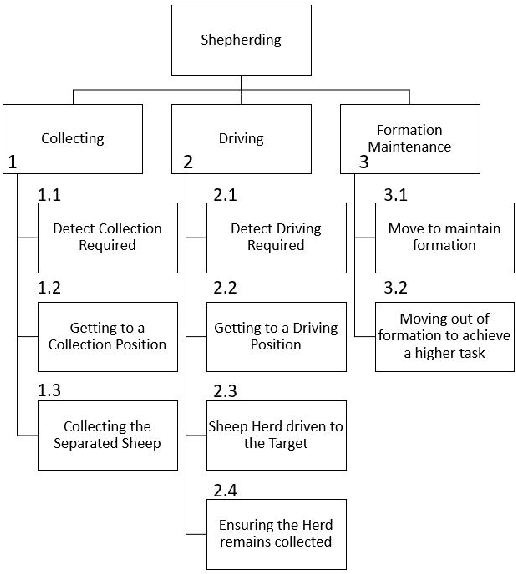
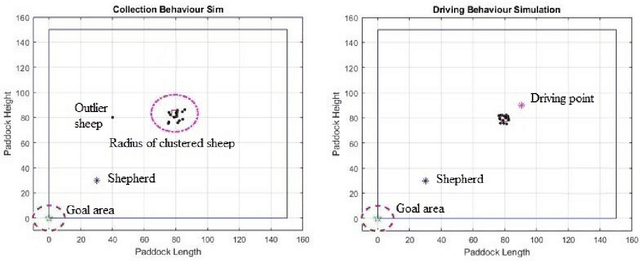
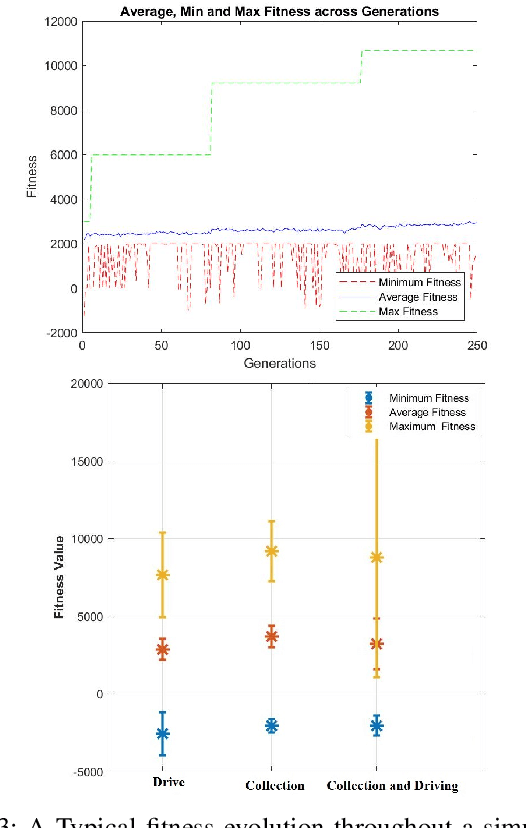
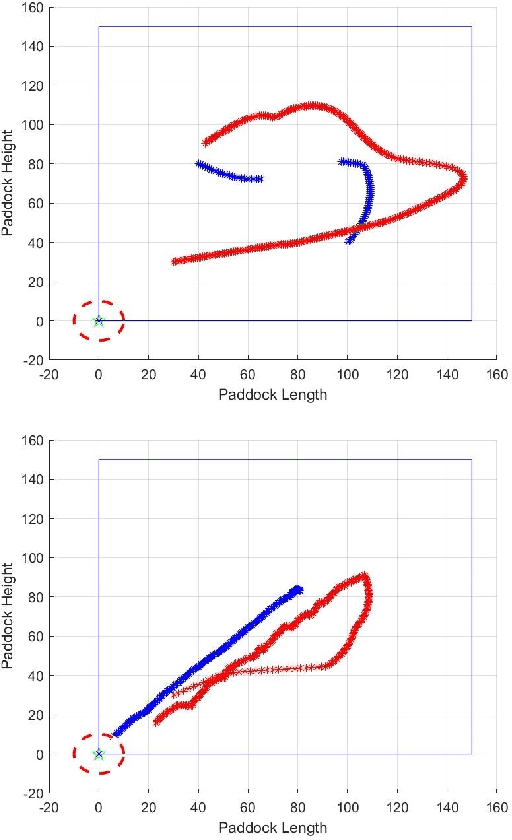
The design of reward functions in reinforcement learning is a human skill that comes with experience. Unfortunately, there is not any methodology in the literature that could guide a human to design the reward function or to allow a human to transfer the skills developed in designing reward functions to another human and in a systematic manner. In this paper, we use Systematic Instructional Design, an approach in human education, to engineer a machine education methodology to design reward functions for reinforcement learning. We demonstrate the methodology in designing a hierarchical genetic reinforcement learner that adopts a neural network representation to evolve a swarm controller for an agent shepherding a boids-based swarm. The results reveal that the methodology is able to guide the design of hierarchical reinforcement learners, with each model in the hierarchy learning incrementally through a multi-part reward function. The hierarchy acts as a decision fusion function that combines the individual behaviours and skills learnt by each instruction to create a smart shepherd to control the swarm.
Lifelong Testing of Smart Autonomous Systems by Shepherding a Swarm of Watchdog Artificial Intelligence Agents
Dec 21, 2018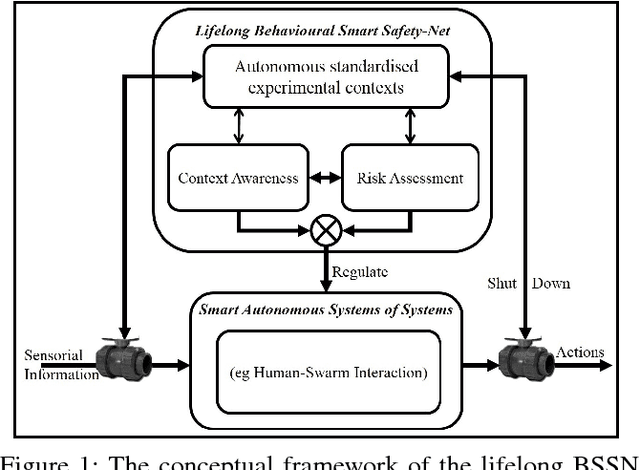
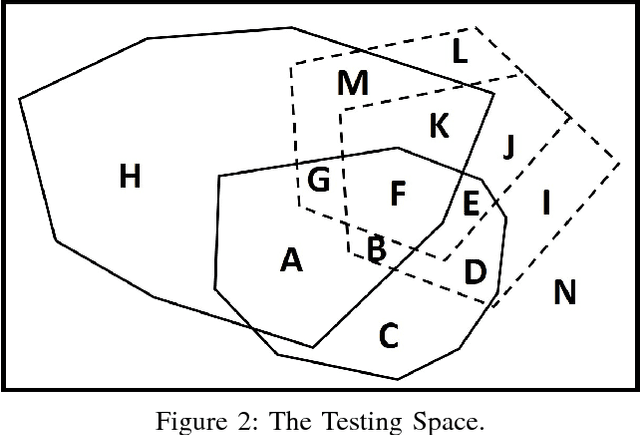
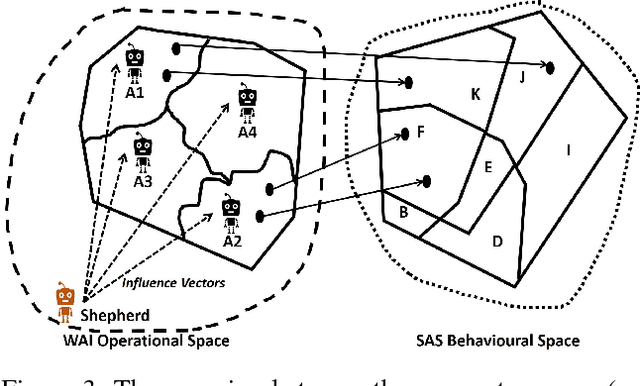
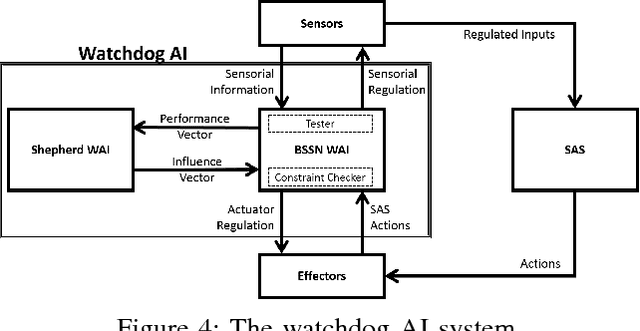
Artificial Intelligence (AI) technologies could be broadly categorised into Analytics and Autonomy. Analytics focuses on algorithms offering perception, comprehension, and projection of knowledge gleaned from sensorial data. Autonomy revolves around decision making, and influencing and shaping the environment through action production. A smart autonomous system (SAS) combines analytics and autonomy to understand, learn, decide and act autonomously. To be useful, SAS must be trusted and that requires testing. Lifelong learning of a SAS compounds the testing process. In the remote chance that it is possible to fully test and certify the system pre-release, which is theoretically an undecidable problem, it is near impossible to predict the future behaviours that these systems, alone or collectively, will exhibit. While it may be feasible to severely restrict such systems\textquoteright \ learning abilities to limit the potential unpredictability of their behaviours, an undesirable consequence may be severely limiting their utility. In this paper, we propose the architecture for a watchdog AI (WAI) agent dedicated to lifelong functional testing of SAS. We further propose system specifications including a level of abstraction whereby humans shepherd a swarm of WAI agents to oversee an ecosystem made of humans and SAS. The discussion extends to the challenges, pros, and cons of the proposed concept.
Apprenticeship Bootstrapping Via Deep Learning with a Safety Net for UAV-UGV Interaction
Oct 10, 2018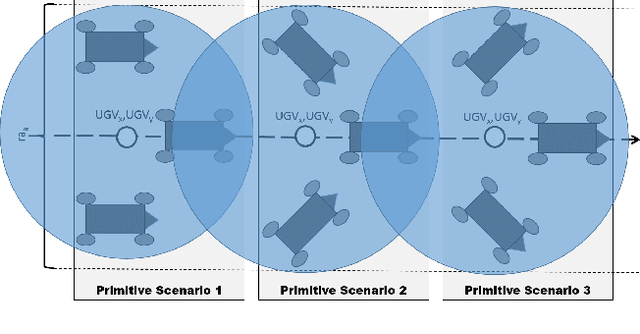

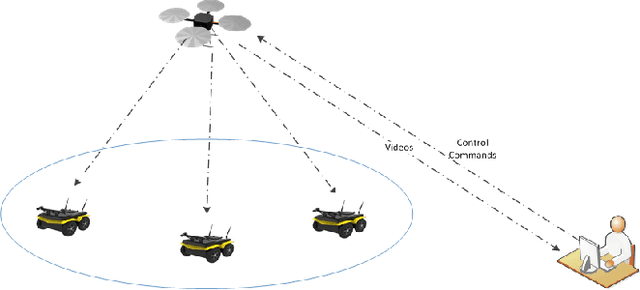

In apprenticeship learning (AL), agents learn by watching or acquiring human demonstrations on some tasks of interest. However, the lack of human demonstrations in novel tasks where they may not be a human expert yet, or when it is too expensive and/or time consuming to acquire human demonstrations motivated a new algorithm: Apprenticeship bootstrapping (ABS). The basic idea is to learn from demonstrations on sub-tasks then autonomously bootstrap a model on the main, more complex, task. The original ABS used inverse reinforcement learning (ABS-IRL). However, the approach is not suitable for continuous action spaces. In this paper, we propose ABS via Deep learning (ABS-DL). It is first validated in a simulation environment on an aerial and ground coordination scenario, where an Unmanned Aerial Vehicle (UAV) is required to maintain three Unmanned Ground Vehicles (UGVs) within a field of view of the UAV 's camera (FoV). Moving a machine learning algorithm from a simulation environment to an actual physical platform is challenging because `mistakes' made by the algorithm while learning could lead to the damage of the platform. We then take this extra step to test the algorithm in a physical environment. We propose a safety-net as a protection layer to ensure that the autonomy of the algorithm in learning does not compromise the safety of the platform. The tests of ABS-DL in the real environment can guarantee a damage-free, collision avoidance behaviour of autonomous bodies. The results show that performance of the proposed approach is comparable to that of a human, and competitive to the traditional approach using expert demonstrations performed on the composite task. The proposed safety-net approach demonstrates its advantages when it enables the UAV to operate more safely under the control of the ABS-DL algorithm.
Networking the Boids is More Robust Against Adversarial Learning
Feb 27, 2018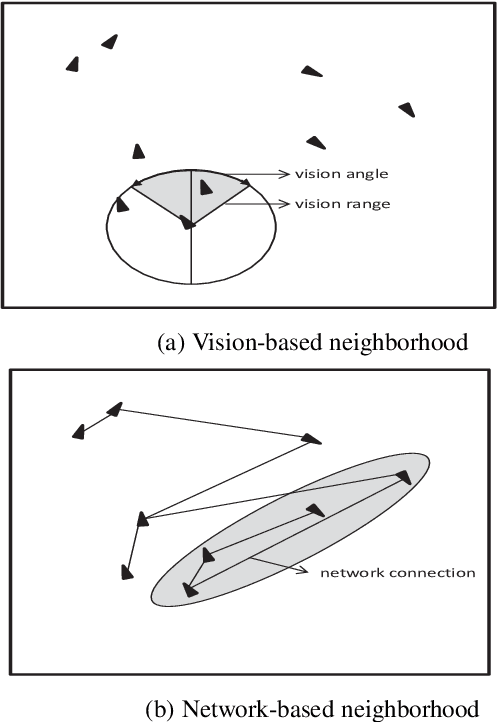
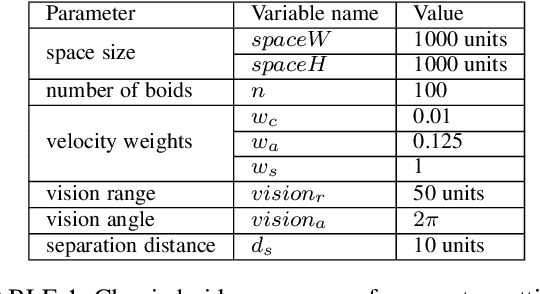
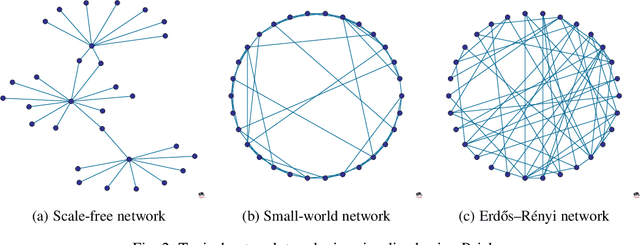

Swarm behavior using Boids-like models has been studied primarily using close-proximity spatial sensory information (e.g. vision range). In this study, we propose a novel approach in which the classic definition of boids\textquoteright \ neighborhood that relies on sensory perception and Euclidian space locality is replaced with graph-theoretic network-based proximity mimicking communication and social networks. We demonstrate that networking the boids leads to faster swarming and higher quality of the formation. We further investigate the effect of adversarial learning, whereby an observer attempts to reverse engineer the dynamics of the swarm through observing its behavior. The results show that networking the swarm demonstrated a more robust approach against adversarial learning than a local-proximity neighborhood structure.
A Multi-Disciplinary Review of Knowledge Acquisition Methods: From Human to Autonomous Eliciting Agents
Feb 27, 2018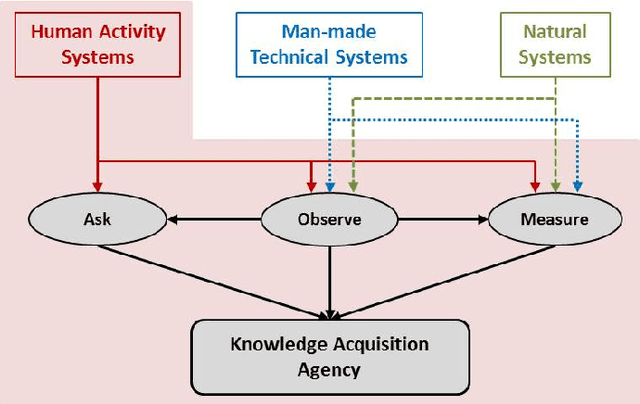

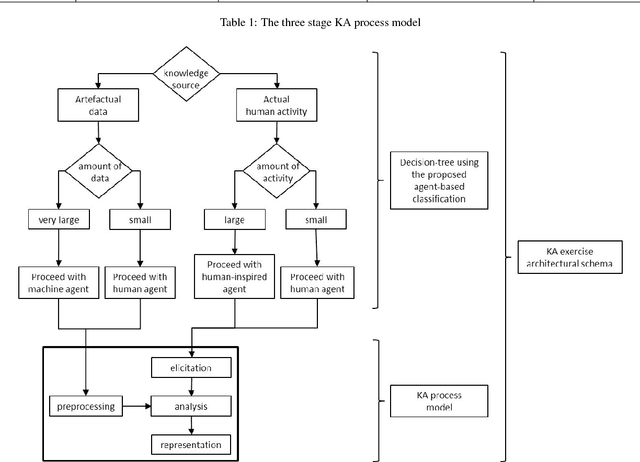
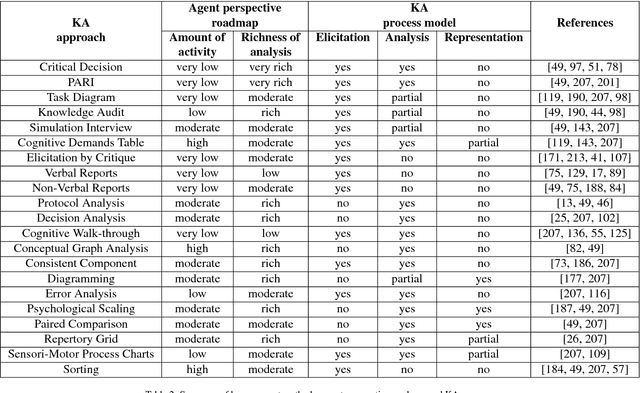
This paper offers a multi-disciplinary review of knowledge acquisition methods in human activity systems. The review captures the degree of involvement of various types of agencies in the knowledge acquisition process, and proposes a classification with three categories of methods: the human agent, the human-inspired agent, and the autonomous machine agent methods. In the first two categories, the acquisition of knowledge is seen as a cognitive task analysis exercise, while in the third category knowledge acquisition is treated as an autonomous knowledge-discovery endeavour. The motivation for this classification stems from the continuous change over time of the structure, meaning and purpose of human activity systems, which are seen as the factor that fuelled researchers' and practitioners' efforts in knowledge acquisition for more than a century. We show through this review that the KA field is increasingly active due to the higher and higher pace of change in human activity, and conclude by discussing the emergence of a fourth category of knowledge acquisition methods, which are based on red-teaming and co-evolution.
Computational Red Teaming in a Sudoku Solving Context: Neural Network Based Skill Representation and Acquisition
Feb 27, 2018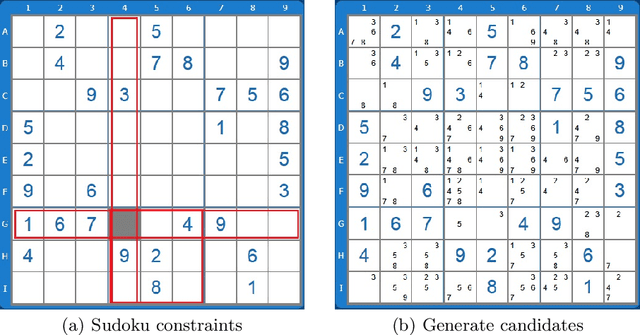

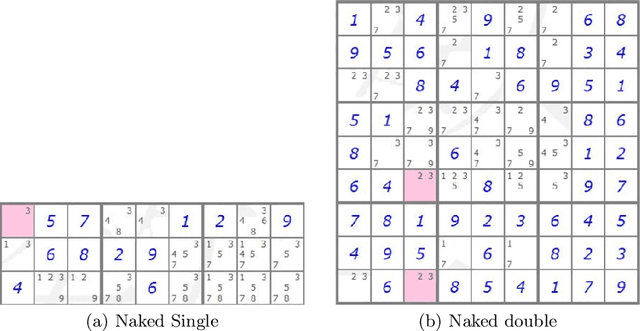

In this paper we provide an insight into the skill representation, where skill representation is seen as an essential part of the skill assessment stage in the Computational Red Teaming process. Skill representation is demonstrated in the context of Sudoku puzzle, for which the real human skills used in Sudoku solving, along with their acquisition, are represented computationally in a cognitively plausible manner, by using feed-forward neural networks with back-propagation, and supervised learning. The neural network based skills are then coupled with a hard-coded constraint propagation computational Sudoku solver, in which the solving sequence is kept hard-coded, and the skills are represented through neural networks. The paper demonstrates that the modified solver can achieve different levels of proficiency, depending on the amount of skills acquired through the neural networks. Results are encouraging for developing more complex skill and skill acquisition models usable in general frameworks related to the skill assessment aspect of Computational Red Teaming.
Shaping Influence and Influencing Shaping: A Computational Red Teaming Trust-based Swarm Intelligence Model
Feb 26, 2018
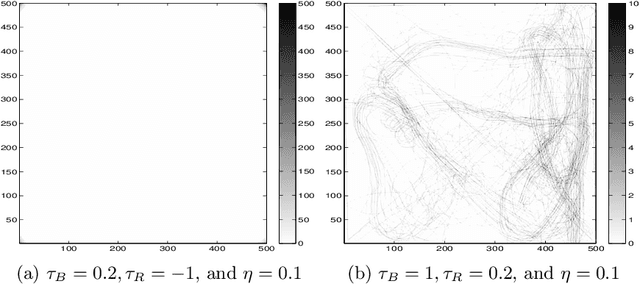
Sociotechnical systems are complex systems, where nonlinear interaction among different players can obscure causal relationships. The absence of mechanisms to help us understand how to create a change in the system makes it hard to manage these systems. Influencing and shaping are social operators acting on sociotechnical systems to design a change. However, the two operators are usually discussed in an ad-hoc manner, without proper guiding models and metrics which assist in adopting these models successfully. Moreover, both social operators rely on accurate understanding of the concept of trust. Without such understanding, neither of these operators can create the required level to create a change in a desirable direction. In this paper, we define these concepts in a concise manner suitable for modelling the concepts and understanding their dynamics. We then introduce a model for influencing and shaping and use Computational Red Teaming principles to design and demonstrate how this model operates. We validate the results computationally through a simulation environment to show social influencing and shaping in an artificial society.
Robustness and Adaptiveness Analysis of Future Fleets
Jul 03, 2009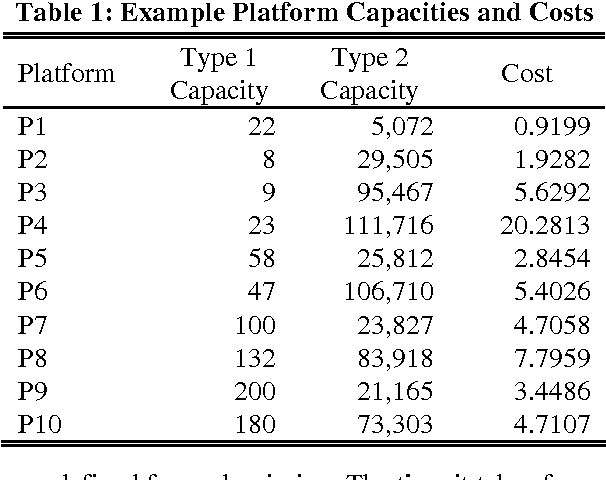
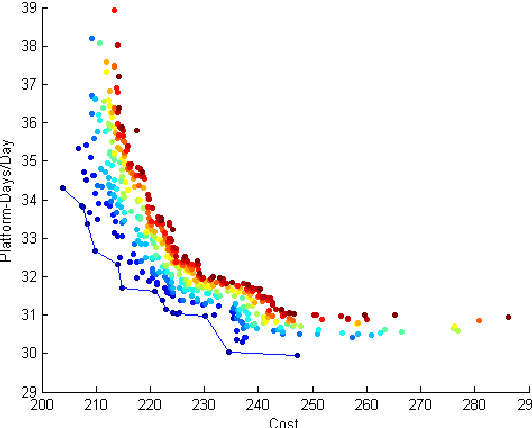
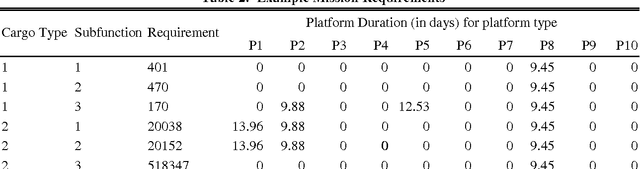
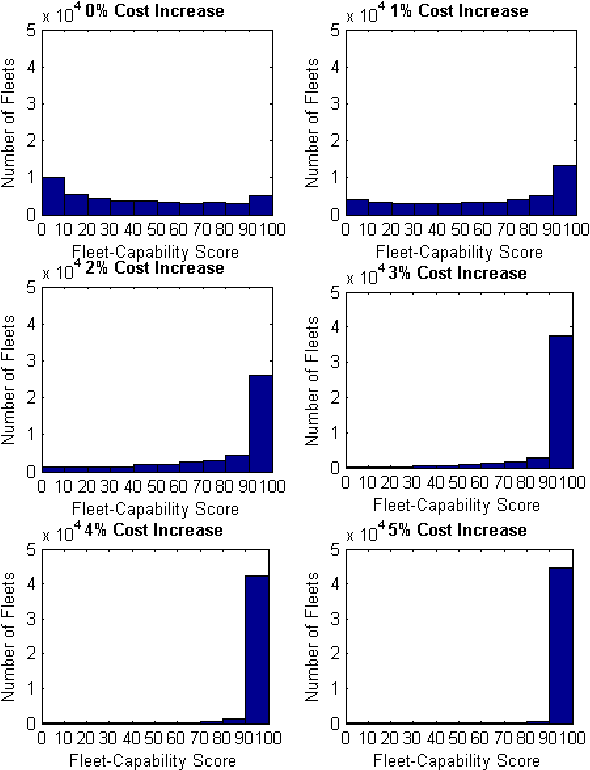
Making decisions about the structure of a future military fleet is a challenging task. Several issues need to be considered such as the existence of multiple competing objectives and the complexity of the operating environment. A particular challenge is posed by the various types of uncertainty that the future might hold. It is uncertain what future events might be encountered; how fleet design decisions will influence and shape the future; and how present and future decision makers will act based on available information, their personal biases regarding the importance of different objectives, and their economic preferences. In order to assist strategic decision-making, an analysis of future fleet options needs to account for conditions in which these different classes of uncertainty are exposed. It is important to understand what assumptions a particular fleet is robust to, what the fleet can readily adapt to, and what conditions present clear risks to the fleet. We call this the analysis of a fleet's strategic positioning. This paper introduces how strategic positioning can be evaluated using computer simulations. Our main aim is to introduce a framework for capturing information that can be useful to a decision maker and for defining the concepts of robustness and adaptiveness in the context of future fleet design. We demonstrate our conceptual framework using simulation studies of an air transportation fleet. We capture uncertainty by employing an explorative scenario-based approach. Each scenario represents a sampling of different future conditions, different model assumptions, and different economic preferences. Proposed changes to a fleet are then analysed based on their influence on the fleet's robustness, adaptiveness, and risk to different scenarios.