 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJ-Net: Randomly weighted U-Net for audio source separation
Nov 29, 2019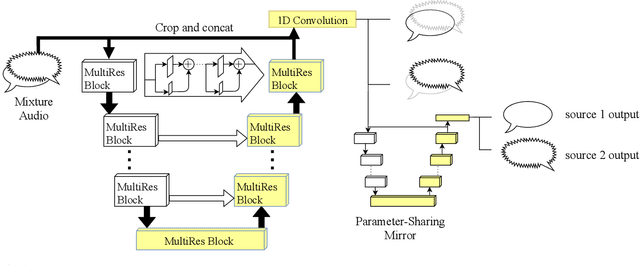
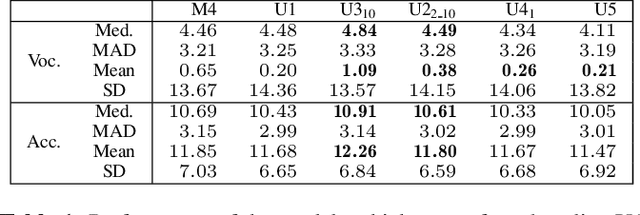
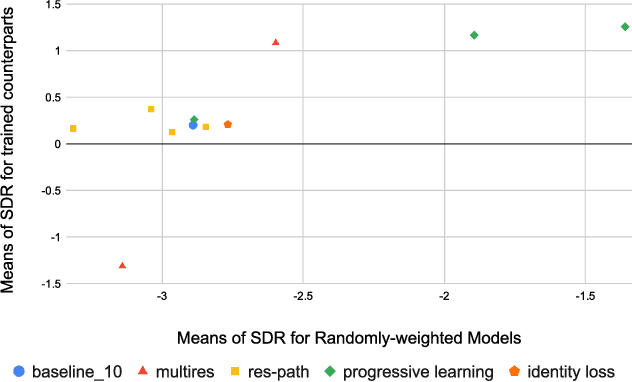
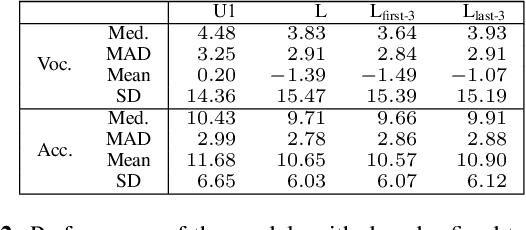
Several results in the computer vision literature have shown the potential of randomly weighted neural networks. While they perform fairly well as feature extractors for discriminative tasks, a positive correlation exists between their performance and their fully trained counterparts. According to these discoveries, we pose two questions: what is the value of randomly weighted networks in difficult generative audio tasks such as audio source separation and does such positive correlation still exist when it comes to large random networks and their trained counterparts? In this paper, we demonstrate that the positive correlation still exists. Based on this discovery, we can try out different architecture designs or tricks without training the whole model. Meanwhile, we find a surprising result that in comparison to the non-trained encoder (down-sample path) in Wave-U-Net, fixing the decoder (up-sample path) to random weights results in better performance, almost comparable to the fully trained model.
Training a code-switching language model with monolingual data
Nov 14, 2019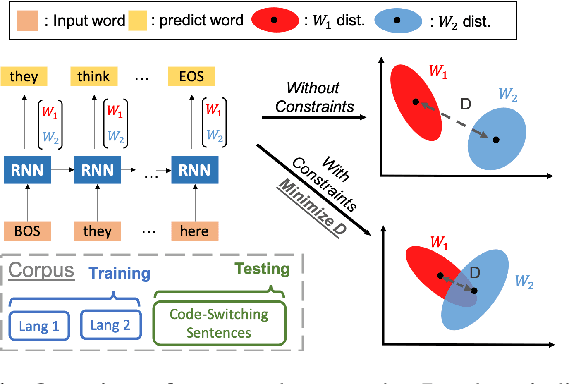
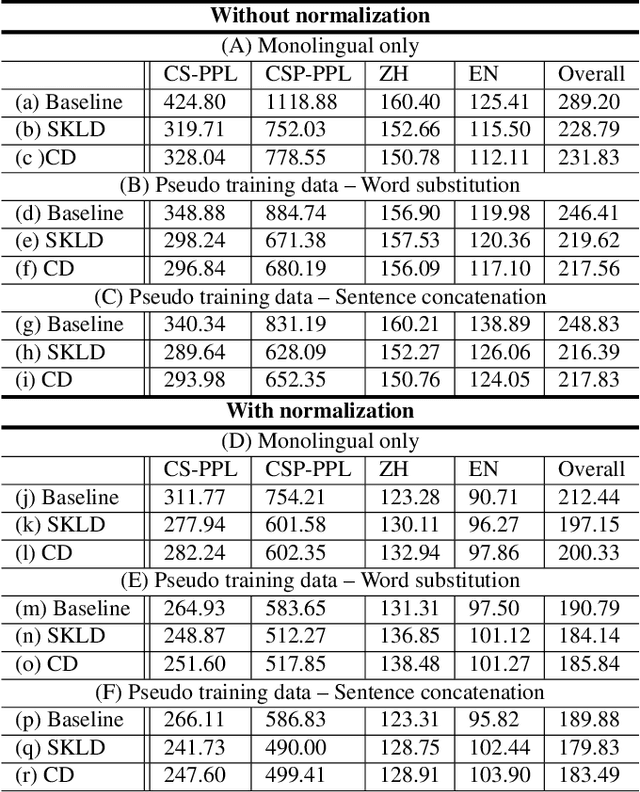
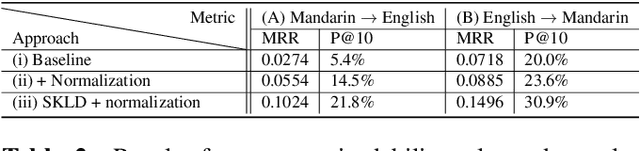
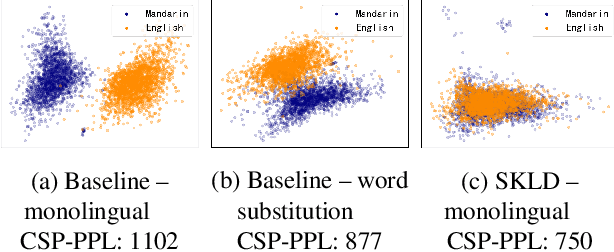
A lack of code-switching data complicates the training of code-switching (CS) language models. We propose an approach to train such CS language models on monolingual data only. By constraining and normalizing the output projection matrix in RNN-based language models, we bring embeddings of different languages closer to each other. Numerical and visualization results show that the proposed approaches remarkably improve the performance of CS language models trained on monolingual data. The proposed approaches are comparable or even better than training CS language models with artificially generated CS data. We additionally use unsupervised bilingual word translation to analyze whether semantically equivalent words in different languages are mapped together.
What does a network layer hear? Analyzing hidden representations of end-to-end ASR through speech synthesis
Nov 04, 2019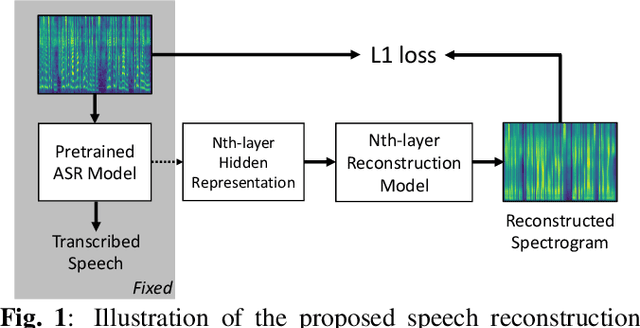
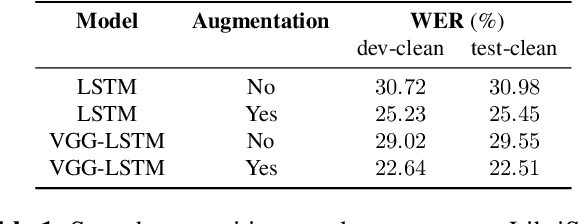
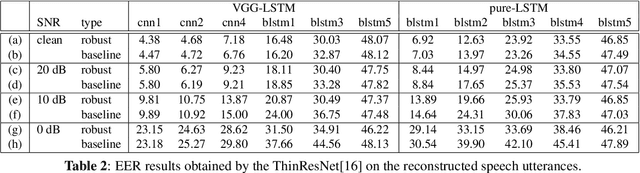
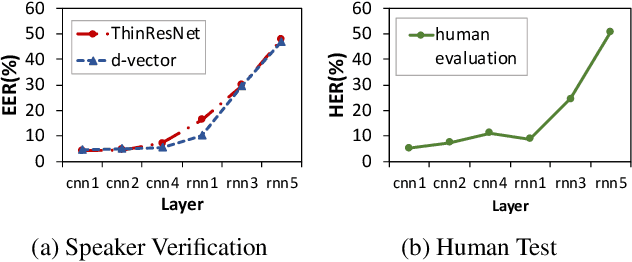
End-to-end speech recognition systems have achieved competitive results compared to traditional systems. However, the complex transformations involved between layers given highly variable acoustic signals are hard to analyze. In this paper, we present our ASR probing model, which synthesizes speech from hidden representations of end-to-end ASR to examine the information maintain after each layer calculation. Listening to the synthesized speech, we observe gradual removal of speaker variability and noise as the layer goes deeper, which aligns with the previous studies on how deep network functions in speech recognition. This paper is the first study analyzing the end-to-end speech recognition model by demonstrating what each layer hears. Speaker verification and speech enhancement measurements on synthesized speech are also conducted to confirm our observation further.
SpeechBERT: Cross-Modal Pre-trained Language Model for End-to-end Spoken Question Answering
Oct 25, 2019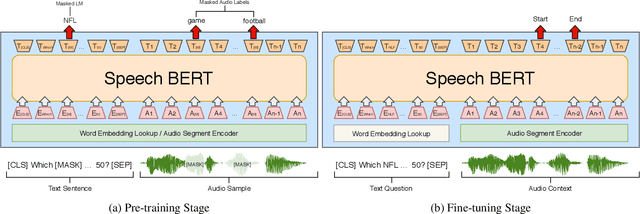
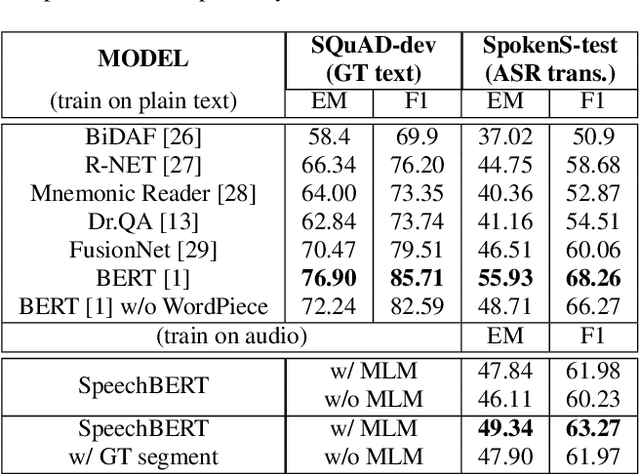
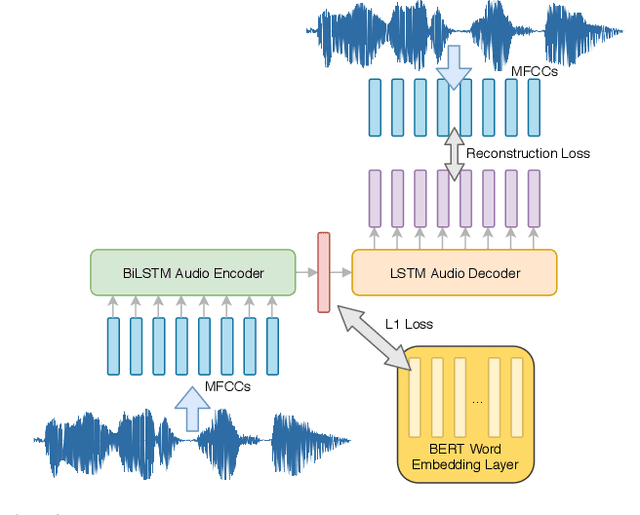
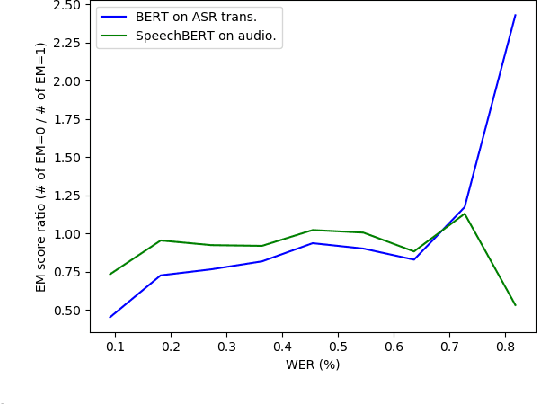
While end-to-end models for spoken language understanding tasks have been explored recently, there is still no end-to-end model for spoken question answering (SQA) tasks, which would be catastrophically influenced by speech recognition errors. Meanwhile, pre-trained language models, such as BERT, have performed successfully in text question answering. To bring this advantage of pre-trained language models into spoken question answering, we propose SpeechBERT, a cross-modal transformer-based pre-trained language model. As the first exploration in end-to-end SQA models, our results matched the performance of conventional approaches that fed with output text from ASR and only slightly fell behind pre-trained language models, showing the potential of end-to-end SQA models.
Tree Transformer: Integrating Tree Structures into Self-Attention
Sep 14, 2019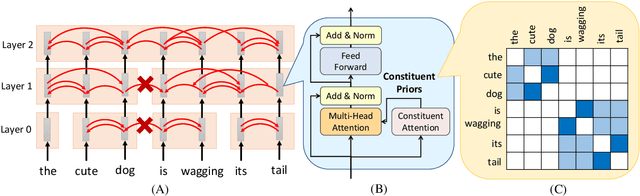
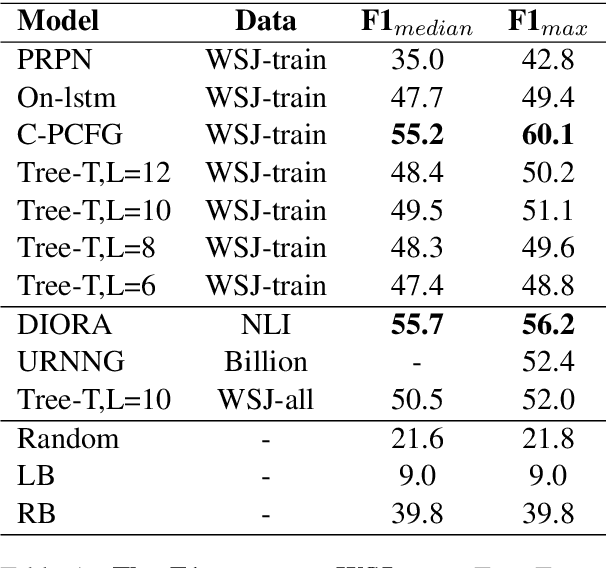
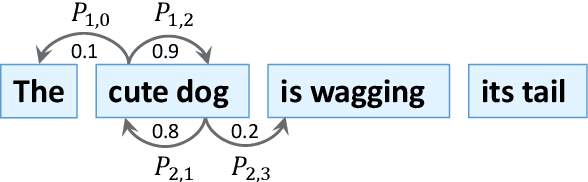
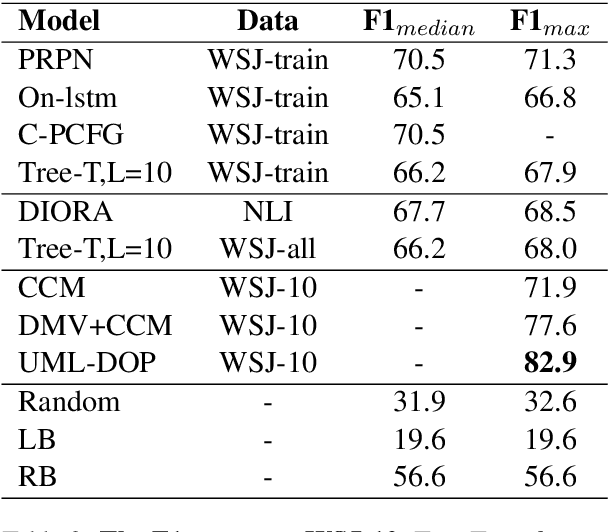
Pre-training Transformer from large-scale raw texts and fine-tuning on the desired task have achieved state-of-the-art results on diverse NLP tasks. However, it is unclear what the learned attention captures. The attention computed by attention heads seems not to match human intuitions about hierarchical structures. This paper proposes Tree Transformer, which adds an extra constraint to attention heads of the bidirectional Transformer encoder in order to encourage the attention heads to follow tree structures. The tree structures can be automatically induced from raw texts by our proposed ``Constituent Attention'' module, which is simply implemented by self-attention between two adjacent words. With the same training procedure identical to BERT, the experiments demonstrate the effectiveness of Tree Transformer in terms of inducing tree structures, better language modeling, and further learning more explainable attention scores.
Order-free Learning Alleviating Exposure Bias in Multi-label Classification
Sep 08, 2019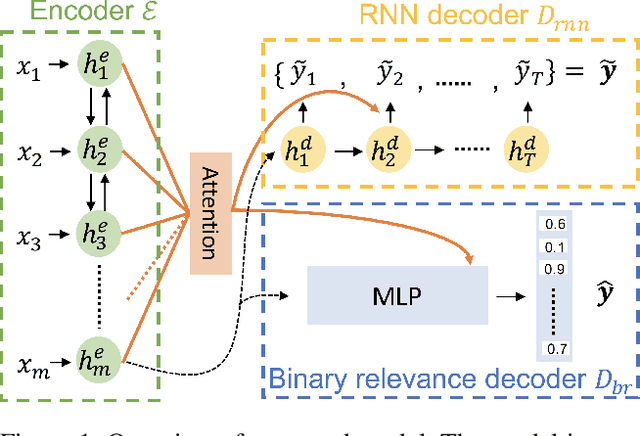
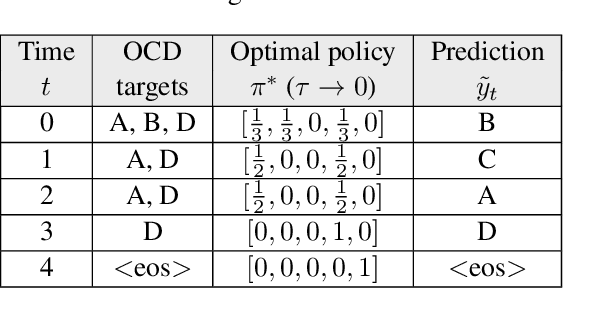
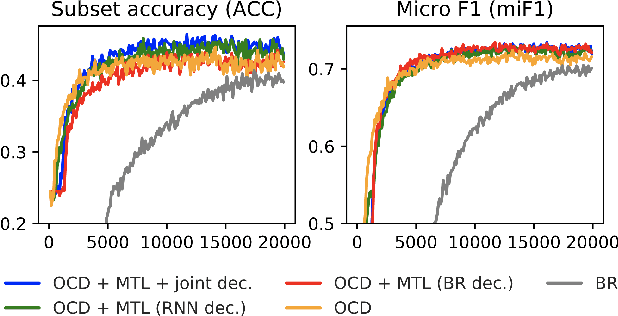
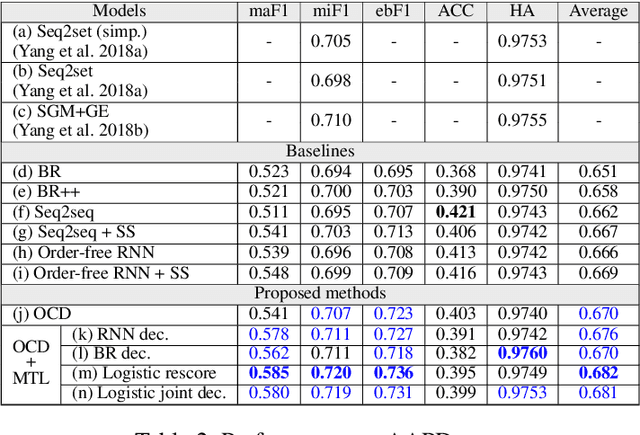
Multi-label classification (MLC) assigns multiple labels to each sample. Prior studies show that MLC can be transformed to a sequence prediction problem with a recurrent neural network (RNN) decoder to model the label dependency. However, training a RNN decoder requires a predefined order of labels, which is not directly available in the MLC specification. Besides, RNN thus trained tends to overfit the label combinations in the training set and have difficulty generating unseen label sequences. In this paper, we propose a new framework for MLC which does not rely on a predefined label order and thus alleviates exposure bias. The experimental results on three multi-label classification benchmark datasets show that our method outperforms competitive baselines by a large margin. We also find the proposed approach has a higher probability of generating label combinations not seen during training than the baseline models. The result shows that the proposed approach has better generalization capability.
LAMAL: LAnguage Modeling Is All You Need for Lifelong Language Learning
Sep 07, 2019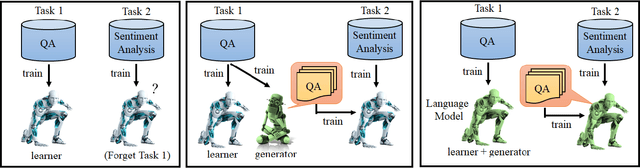
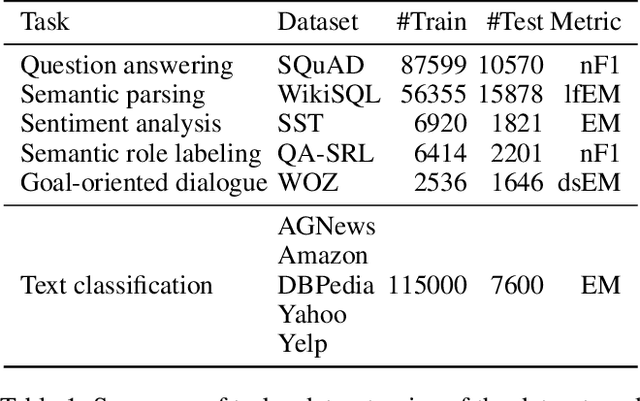
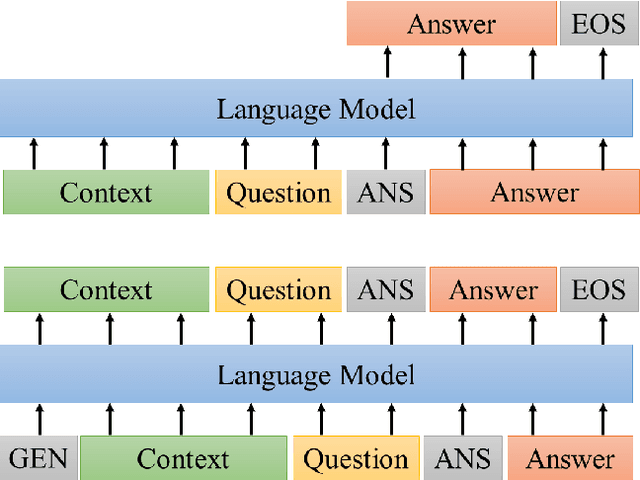
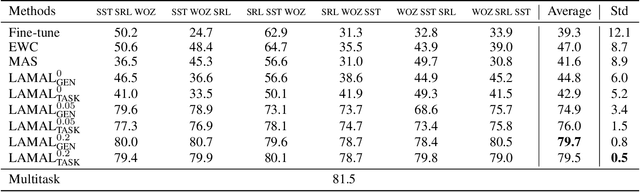
Most research on lifelong learning (LLL) applies to images or games, but not language. Here, we introduce LAMAL, a simple yet effective method for LLL based on language modeling. LAMAL replays pseudo samples of previous tasks while requiring no extra memory or model capacity. To be specific, LAMAL is a language model learning to solve the task and generate training samples at the same time. At the beginning of training a new task, the model generates some pseudo samples of previous tasks to train alongside the data of the new task. The results show that LAMAL prevents catastrophic forgetting without any sign of intransigence and can solve up to five very different language tasks sequentially with only one model. Overall, LAMAL outperforms previous methods by a considerable margin and is only 2-3\% worse than multitasking which is usually considered as the upper bound of LLL. Our source code is available at https://github.com/xxx.
Cross-Lingual Transfer Learning for Question Answering
Jul 13, 2019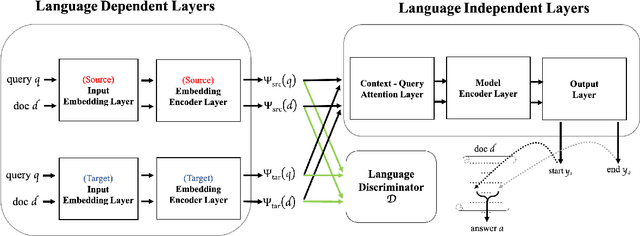

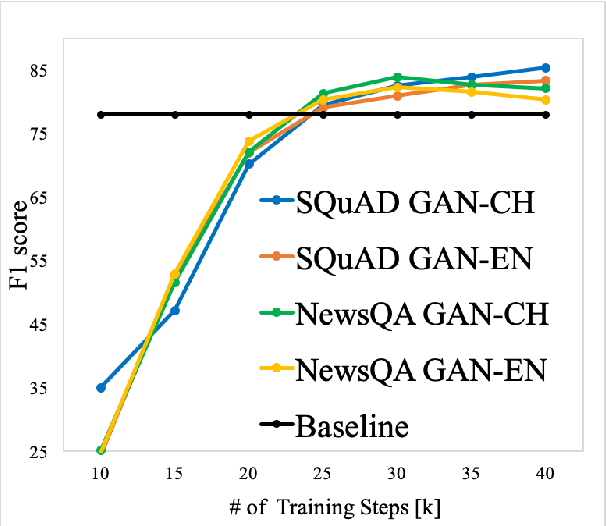
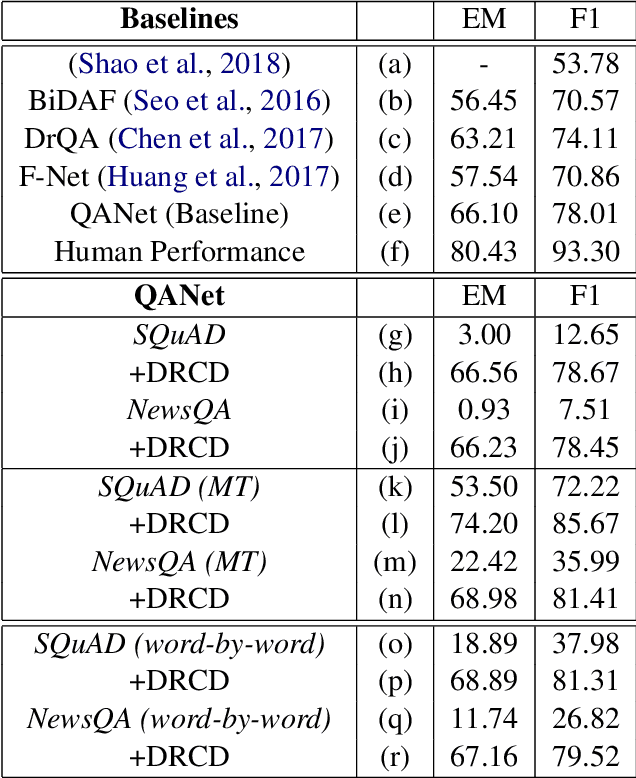
Deep learning based question answering (QA) on English documents has achieved success because there is a large amount of English training examples. However, for most languages, training examples for high-quality QA models are not available. In this paper, we explore the problem of cross-lingual transfer learning for QA, where a source language task with plentiful annotations is utilized to improve the performance of a QA model on a target language task with limited available annotations. We examine two different approaches. A machine translation (MT) based approach translates the source language into the target language, or vice versa. Although the MT-based approach brings improvement, it assumes the availability of a sentence-level translation system. A GAN-based approach incorporates a language discriminator to learn language-universal feature representations, and consequentially transfer knowledge from the source language. The GAN-based approach rivals the performance of the MT-based approach with fewer linguistic resources. Applying both approaches simultaneously yield the best results. We use two English benchmark datasets, SQuAD and NewsQA, as source language data, and show significant improvements over a number of established baselines on a Chinese QA task. We achieve the new state-of-the-art on the Chinese QA dataset.
Mitigating the Impact of Speech Recognition Errors on Spoken Question Answering by Adversarial Domain Adaptation
Apr 16, 2019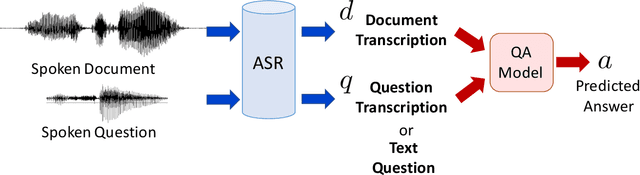
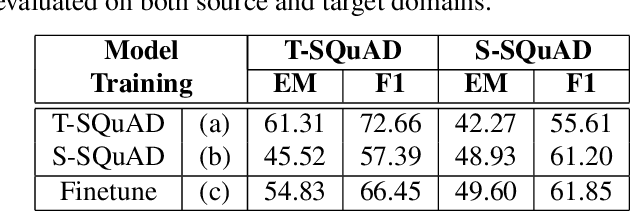
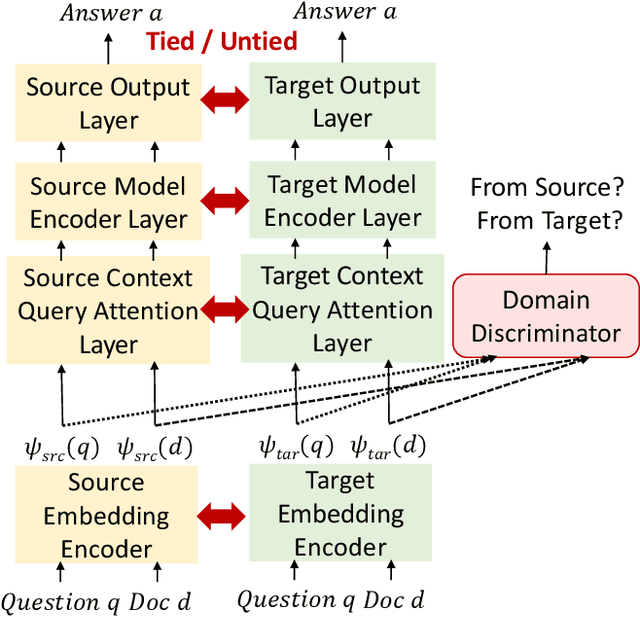
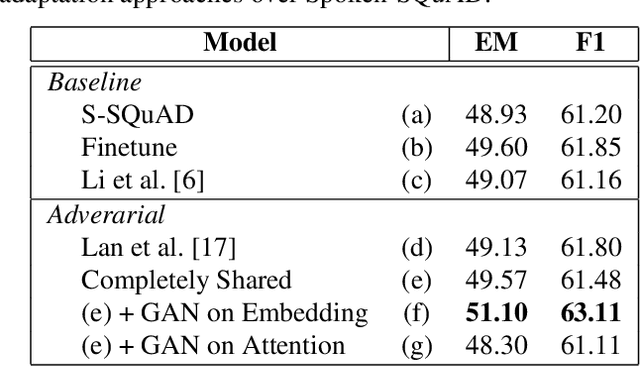
Spoken question answering (SQA) is challenging due to complex reasoning on top of the spoken documents. The recent studies have also shown the catastrophic impact of automatic speech recognition (ASR) errors on SQA. Therefore, this work proposes to mitigate the ASR errors by aligning the mismatch between ASR hypotheses and their corresponding reference transcriptions. An adversarial model is applied to this domain adaptation task, which forces the model to learn domain-invariant features the QA model can effectively utilize in order to improve the SQA results. The experiments successfully demonstrate the effectiveness of our proposed model, and the results are better than the previous best model by 2% EM score.
Improved Speech Separation with Time-and-Frequency Cross-domain Joint Embedding and Clustering
Apr 16, 2019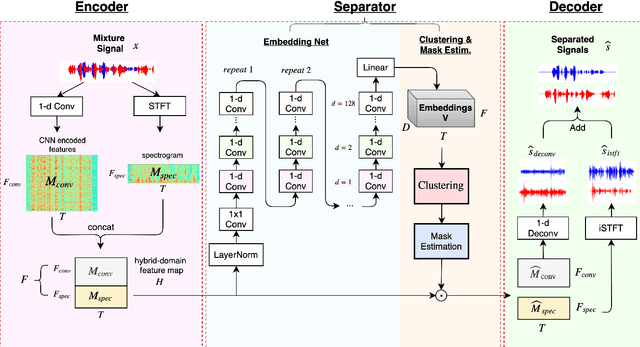
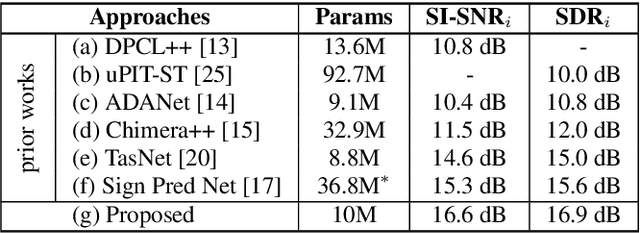
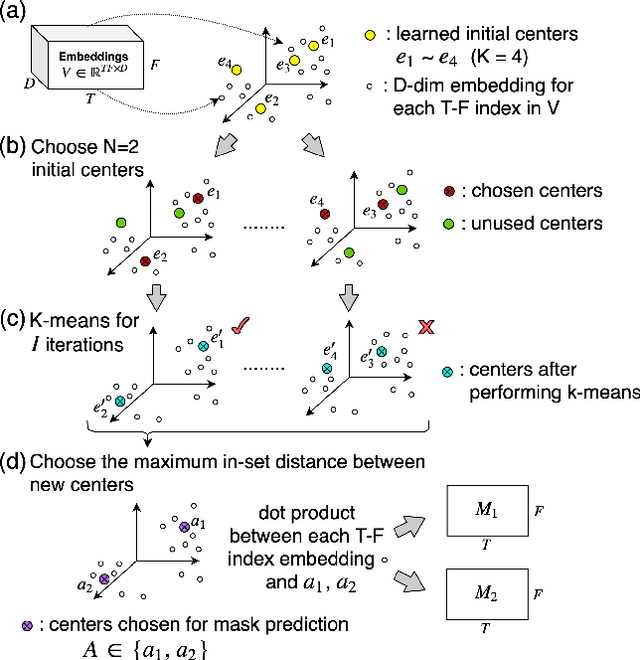
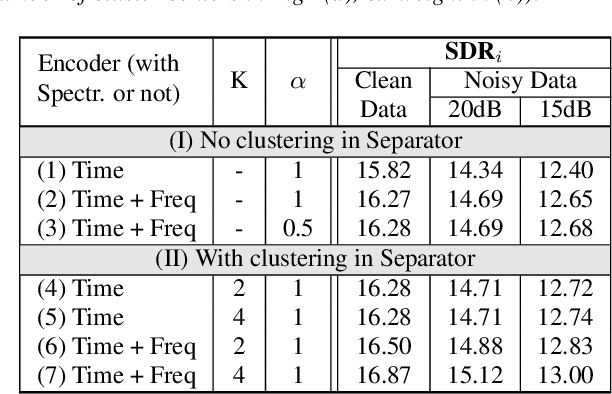
Speech separation has been very successful with deep learning techniques. Substantial effort has been reported based on approaches over spectrogram, which is well known as the standard time-and-frequency cross-domain representation for speech signals. It is highly correlated to the phonetic structure of speech, or "how the speech sounds" when perceived by human, but primarily frequency domain features carrying temporal behaviour. Very impressive work achieving speech separation over time domain was reported recently, probably because waveforms in time domain may describe the different realizations of speech in a more precise way than spectrogram. In this paper, we propose a framework properly integrating the above two directions, hoping to achieve both purposes. We construct a time-and-frequency feature map by concatenating the 1-dim convolution encoded feature map (for time domain) and the spectrogram (for frequency domain), which was then processed by an embedding network and clustering approaches very similar to those used in time and frequency domain prior works. In this way, the information in the time and frequency domains, as well as the interactions between them, can be jointly considered during embedding and clustering. Very encouraging results (state-of-the-art to our knowledge) were obtained with WSJ0-2mix dataset in preliminary experiments.