 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Geometry Mismatch: Frequency-Aware Anisotropic Serialization for Thin-Structure SSMs
Mar 30, 2026The segmentation of thin linear structures is inherently topology allowbreak-critical, where minor local errors can sever long-range connectivity. While recent State-Space Models (SSMs) offer efficient long-range modeling, their isotropic serialization (e.g., raster scanning) creates a geometry mismatch for anisotropic targets, causing state propagation across rather than along the structure trajectories. To address this, we propose FGOS-Net, a framework based on frequency allowbreak-geometric disentanglement. We first decompose features into a stable topology carrier and directional high-frequency bands, leveraging the latter to explicitly correct spatial misalignments induced by downsampling. Building on this calibrated topology, we introduce frequency-aligned scanning that elevates serialization to a geometry-conditioned decision, preserving direction-consistent traces. Coupled with an active probing strategy to selectively inject high-frequency details and suppress texture ambiguity, FGOS-Net consistently outperforms strong baselines across four challenging benchmarks. Notably, it achieves 91.3% mIoU and 97.1% clDice on DeepCrack while running at 80 FPS with only 7.87 GFLOPs.
IP-SAM: Prompt-Space Conditioning for Prompt-Absent Camouflaged Object Detection
Mar 28, 2026Prompt-conditioned foundation segmenters have emerged as a dominant paradigm for image segmentation, where explicit spatial prompts (e.g., points, boxes, masks) guide mask decoding. However, many real-world deployments require fully automatic segmentation, creating a structural mismatch: the decoder expects prompts that are unavailable at inference. Existing adaptations typically modify intermediate features, inadvertently bypassing the model's native prompt interface and weakening prompt-conditioned decoding. We propose IP-SAM, which revisits adaptation from a prompt-space perspective through prompt-space conditioning. Specifically, a Self-Prompt Generator (SPG) distills image context into complementary intrinsic prompts that serve as coarse regional anchors. These cues are projected through SAM2's frozen prompt encoder, restoring prompt-guided decoding without external intervention. To suppress background-induced false positives, Prompt-Space Gating (PSG) leverages the intrinsic background prompt as an asymmetric suppressive constraint prior to decoding. Under a deterministic no-external-prompt protocol, IP-SAM achieves state-of-the-art performance across four camouflaged object detection benchmarks (e.g., MAE 0.017 on COD10K) with only 21.26M trainable parameters (optimizing SPG, PSG, and a task-specific mask decoder trained from scratch, alongside image-encoder LoRA while keeping the prompt encoder frozen). Furthermore, the proposed conditioning strategy generalizes beyond COD to medical polyp segmentation, where a model trained solely on Kvasir-SEG exhibits strong zero-shot transfer to both CVC-ClinicDB and ETIS.
Fluxamba: Topology-Aware Anisotropic State Space Models for Geological Lineament Segmentation in Multi-Source Remote Sensing
Jan 24, 2026The precise segmentation of geological linear features, spanning from planetary lineaments to terrestrial fractures, demands capturing long-range dependencies across complex anisotropic topologies. Although State Space Models (SSMs) offer near-linear computational complexity, their dependence on rigid, axis-aligned scanning trajectories induces a fundamental topological mismatch with curvilinear targets, resulting in fragmented context and feature erosion. To bridge this gap, we propose Fluxamba, a lightweight architecture that introduces a topology-aware feature rectification framework. Central to our design is the Structural Flux Block (SFB), which orchestrates an anisotropic information flux by integrating an Anisotropic Structural Gate (ASG) with a Prior-Modulated Flow (PMF). This mechanism decouples feature orientation from spatial location, dynamically gating context aggregation along the target's intrinsic geometry rather than rigid paths. Furthermore, to mitigate serialization-induced noise in low-contrast environments, we incorporate a Hierarchical Spatial Regulator (HSR) for multi-scale semantic alignment and a High-Fidelity Focus Unit (HFFU) to explicitly maximize the signal-to-noise ratio of faint features. Extensive experiments on diverse geological benchmarks (LROC-Lineament, LineaMapper, and GeoCrack) demonstrate that Fluxamba establishes a new state-of-the-art. Notably, on the challenging LROC-Lineament dataset, it achieves an F1-score of 89.22% and mIoU of 89.87%. Achieving a real-time inference speed of over 24 FPS with only 3.4M parameters and 6.3G FLOPs, Fluxamba reduces computational costs by up to two orders of magnitude compared to heavy-weight baselines, thereby establishing a new Pareto frontier between segmentation fidelity and onboard deployment feasibility.
ArgusCogito: Chain-of-Thought for Cross-Modal Synergy and Omnidirectional Reasoning in Camouflaged Object Segmentation
Aug 25, 2025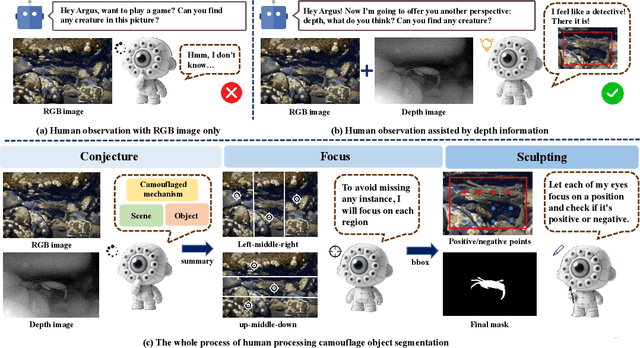
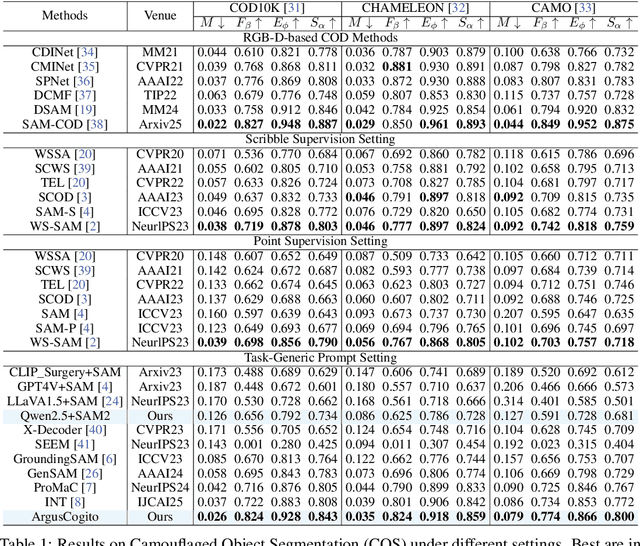
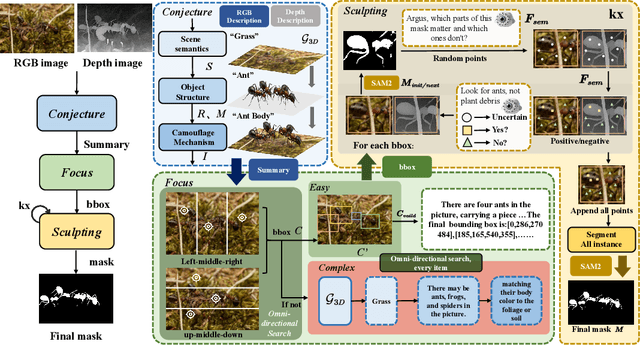
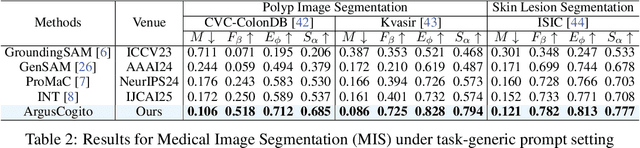
Camouflaged Object Segmentation (COS) poses a significant challenge due to the intrinsic high similarity between targets and backgrounds, demanding models capable of profound holistic understanding beyond superficial cues. Prevailing methods, often limited by shallow feature representation, inadequate reasoning mechanisms, and weak cross-modal integration, struggle to achieve this depth of cognition, resulting in prevalent issues like incomplete target separation and imprecise segmentation. Inspired by the perceptual strategy of the Hundred-eyed Giant-emphasizing holistic observation, omnidirectional focus, and intensive scrutiny-we introduce ArgusCogito, a novel zero-shot, chain-of-thought framework underpinned by cross-modal synergy and omnidirectional reasoning within Vision-Language Models (VLMs). ArgusCogito orchestrates three cognitively-inspired stages: (1) Conjecture: Constructs a strong cognitive prior through global reasoning with cross-modal fusion (RGB, depth, semantic maps), enabling holistic scene understanding and enhanced target-background disambiguation. (2) Focus: Performs omnidirectional, attention-driven scanning and focused reasoning, guided by semantic priors from Conjecture, enabling precise target localization and region-of-interest refinement. (3) Sculpting: Progressively sculpts high-fidelity segmentation masks by integrating cross-modal information and iteratively generating dense positive/negative point prompts within focused regions, emulating Argus' intensive scrutiny. Extensive evaluations on four challenging COS benchmarks and three Medical Image Segmentation (MIS) benchmarks demonstrate that ArgusCogito achieves state-of-the-art (SOTA) performance, validating the framework's exceptional efficacy, superior generalization capability, and robustness.