 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgusCogito: Chain-of-Thought for Cross-Modal Synergy and Omnidirectional Reasoning in Camouflaged Object Segmentation
Aug 25, 2025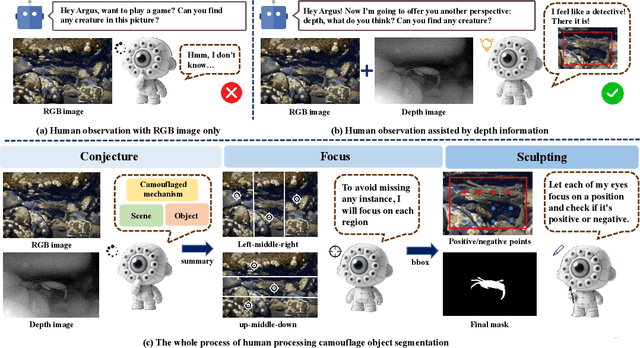
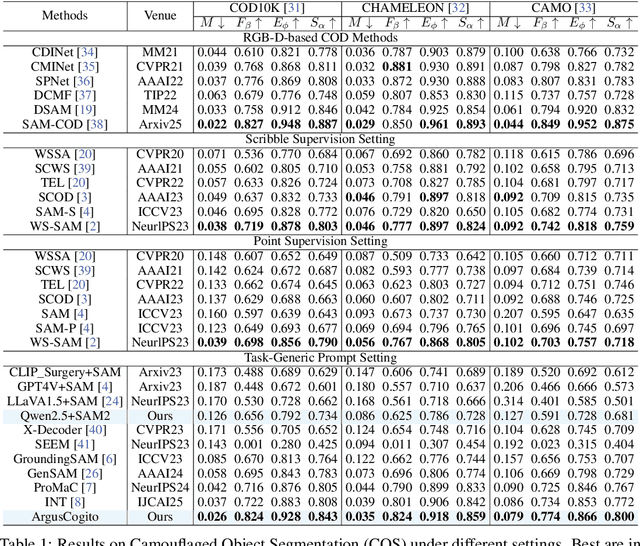
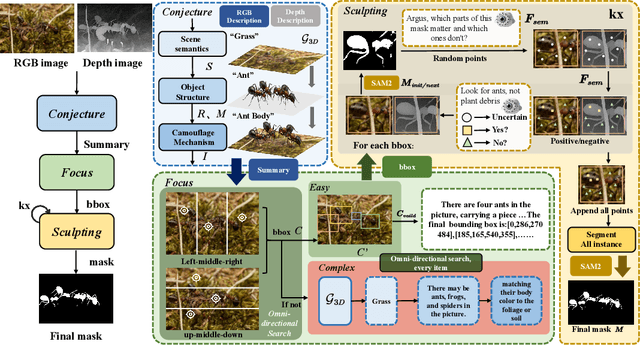
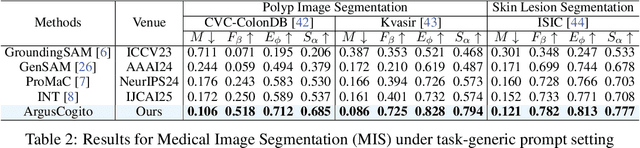
Camouflaged Object Segmentation (COS) poses a significant challenge due to the intrinsic high similarity between targets and backgrounds, demanding models capable of profound holistic understanding beyond superficial cues. Prevailing methods, often limited by shallow feature representation, inadequate reasoning mechanisms, and weak cross-modal integration, struggle to achieve this depth of cognition, resulting in prevalent issues like incomplete target separation and imprecise segmentation. Inspired by the perceptual strategy of the Hundred-eyed Giant-emphasizing holistic observation, omnidirectional focus, and intensive scrutiny-we introduce ArgusCogito, a novel zero-shot, chain-of-thought framework underpinned by cross-modal synergy and omnidirectional reasoning within Vision-Language Models (VLMs). ArgusCogito orchestrates three cognitively-inspired stages: (1) Conjecture: Constructs a strong cognitive prior through global reasoning with cross-modal fusion (RGB, depth, semantic maps), enabling holistic scene understanding and enhanced target-background disambiguation. (2) Focus: Performs omnidirectional, attention-driven scanning and focused reasoning, guided by semantic priors from Conjecture, enabling precise target localization and region-of-interest refinement. (3) Sculpting: Progressively sculpts high-fidelity segmentation masks by integrating cross-modal information and iteratively generating dense positive/negative point prompts within focused regions, emulating Argus' intensive scrutiny. Extensive evaluations on four challenging COS benchmarks and three Medical Image Segmentation (MIS) benchmarks demonstrate that ArgusCogito achieves state-of-the-art (SOTA) performance, validating the framework's exceptional efficacy, superior generalization capability, and robustness.