 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding the Generative AI Design Space through Structured Prompting and Multimodal Interfaces
Apr 22, 2025



Text-based prompting remains the predominant interaction paradigm in generative AI, yet it often introduces friction for novice users such as small business owners (SBOs), who struggle to articulate creative goals in domain-specific contexts like advertising. Through a formative study with six SBOs in the United Kingdom, we identify three key challenges: difficulties in expressing brand intuition through prompts, limited opportunities for fine-grained adjustment and refinement during and after content generation, and the frequent production of generic content that lacks brand specificity. In response, we present ACAI (AI Co-Creation for Advertising and Inspiration), a multimodal generative AI tool designed to support novice designers by moving beyond traditional prompt interfaces. ACAI features a structured input system composed of three panels: Branding, Audience and Goals, and the Inspiration Board. These inputs allow users to convey brand-relevant context and visual preferences. This work contributes to HCI research on generative systems by showing how structured interfaces can foreground user-defined context, improve alignment, and enhance co-creative control in novice creative workflows.
Applying Feature Underspecified Lexicon Phonological Features in Multilingual Text-to-Speech
Apr 14, 2022
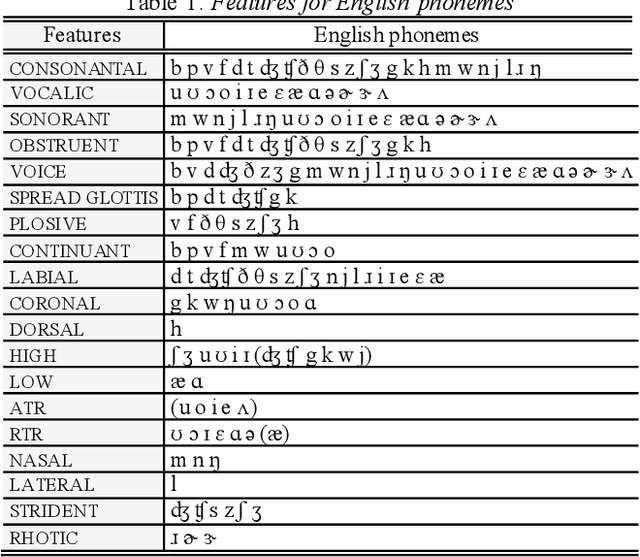

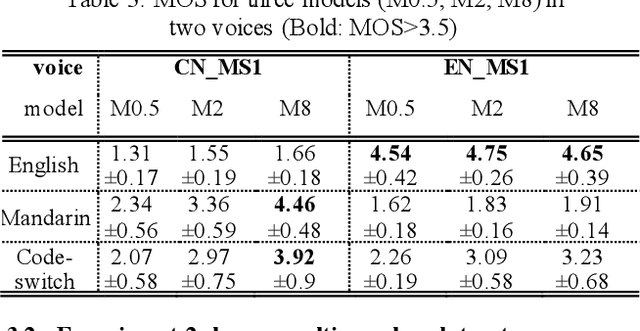
This study investigates whether the phonological features derived from the Featurally Underspecified Lexicon model can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. This mapping was tested for whether it could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results supported that phonological features could be used as a feasible input system for languages in or not in the train data, although further investigation is needed to improve model performance. The results lend support to FUL by presenting successfully synthesised output, and by having the output carrying a source-language accent when synthesising a language not in the training data. The TTS process stimulated human second language acquisition process and thus also confirm FUL's ability to account for acquisition.
Applying Phonological Features in Multilingual Text-To-Speech
Oct 10, 2021
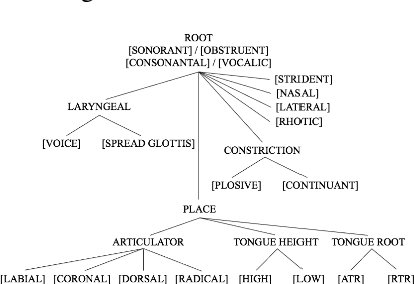

This study investigates whether phonological features can be applied in text-to-speech systems to generate native and non-native speech in English and Mandarin. We present a mapping of ARPABET/pinyin to SAMPA/SAMPA-SC and then to phonological features. We tested whether this mapping could lead to the successful generation of native, non-native, and code-switched speech in the two languages. We ran two experiments, one with a small dataset and one with a larger dataset. The results proved that phonological features could be used as a feasible input system, although further investigation is needed to improve model performance. The accented output generated by the TTS models also helps with understanding human second language acquisition processes.