 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025



Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
FRIB: Low-poisoning Rate Invisible Backdoor Attack based on Feature Repair
Jul 26, 2022

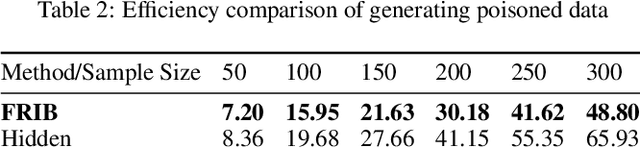
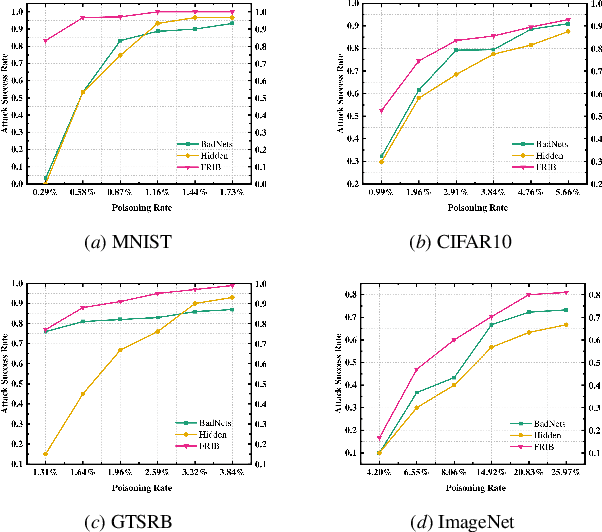
During the generation of invisible backdoor attack poisoned data, the feature space transformation operation tends to cause the loss of some poisoned features and weakens the mapping relationship between source images with triggers and target labels, resulting in the need for a higher poisoning rate to achieve the corresponding backdoor attack success rate. To solve the above problems, we propose the idea of feature repair for the first time and introduce the blind watermark technique to repair the poisoned features lost during the generation of poisoned data. Under the premise of ensuring consistent labeling, we propose a low-poisoning rate invisible backdoor attack based on feature repair, named FRIB. Benefiting from the above design concept, the new method enhances the mapping relationship between the source images with triggers and the target labels, and increases the degree of misleading DNNs, thus achieving a high backdoor attack success rate with a very low poisoning rate. Ultimately, the detailed experimental results show that the goal of achieving a high success rate of backdoor attacks with a very low poisoning rate is achieved on all MNIST, CIFAR10, GTSRB, and ImageNet datasets.
AdvSmo: Black-box Adversarial Attack by Smoothing Linear Structure of Texture
Jun 22, 2022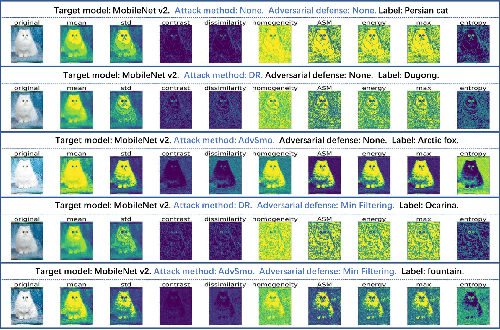
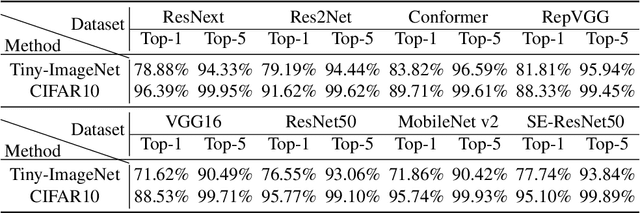
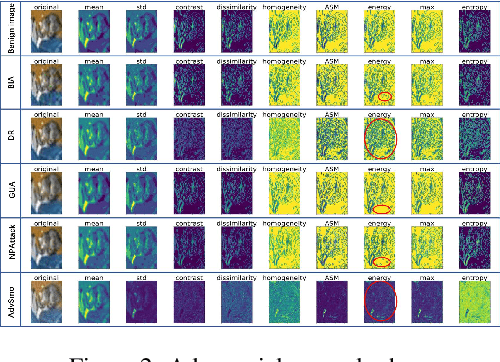
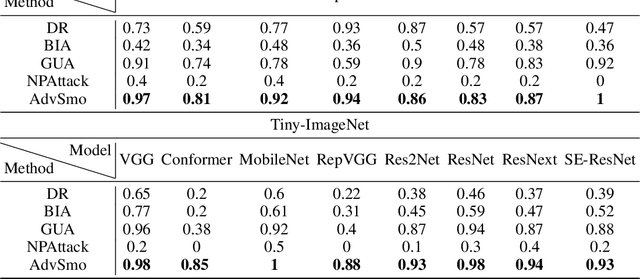
Black-box attacks usually face two problems: poor transferability and the inability to evade the adversarial defense. To overcome these shortcomings, we create an original approach to generate adversarial examples by smoothing the linear structure of the texture in the benign image, called AdvSmo. We construct the adversarial examples without relying on any internal information to the target model and design the imperceptible-high attack success rate constraint to guide the Gabor filter to select appropriate angles and scales to smooth the linear texture from the input images to generate adversarial examples. Benefiting from the above design concept, AdvSmo will generate adversarial examples with strong transferability and solid evasiveness. Finally, compared to the four advanced black-box adversarial attack methods, for the eight target models, the results show that AdvSmo improves the average attack success rate by 9% on the CIFAR-10 and 16% on the Tiny-ImageNet dataset compared to the best of these attack methods.
SSMI: How to Make Objects of Interest Disappear without Accessing Object Detectors?
Jun 22, 2022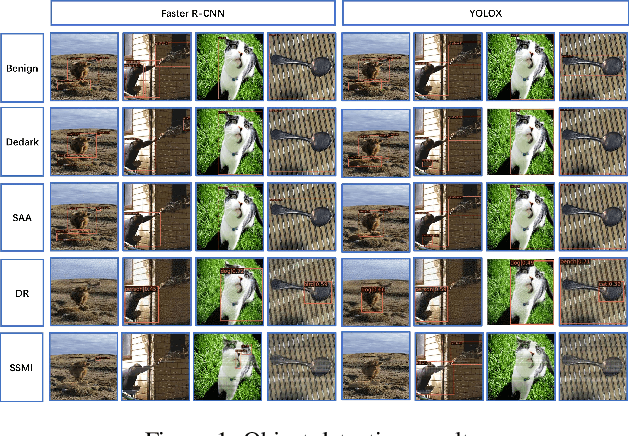


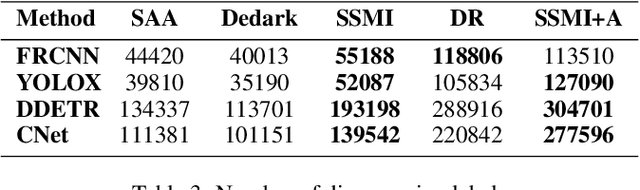
Most black-box adversarial attack schemes for object detectors mainly face two shortcomings: requiring access to the target model and generating inefficient adversarial examples (failing to make objects disappear in large numbers). To overcome these shortcomings, we propose a black-box adversarial attack scheme based on semantic segmentation and model inversion (SSMI). We first locate the position of the target object using semantic segmentation techniques. Next, we design a neighborhood background pixel replacement to replace the target region pixels with background pixels to ensure that the pixel modifications are not easily detected by human vision. Finally, we reconstruct a machine-recognizable example and use the mask matrix to select pixels in the reconstructed example to modify the benign image to generate an adversarial example. Detailed experimental results show that SSMI can generate efficient adversarial examples to evade human-eye perception and make objects of interest disappear. And more importantly, SSMI outperforms existing same kinds of attacks. The maximum increase in new and disappearing labels is 16%, and the maximum decrease in mAP metrics for object detection is 36%.