 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
Finite-Time Analysis for Double Q-learning
Oct 12, 2020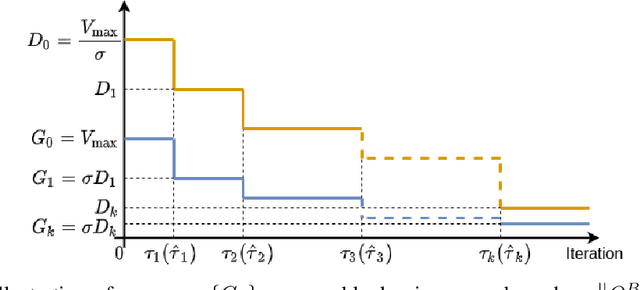
Although Q-learning is one of the most successful algorithms for finding the best action-value function (and thus the optimal policy) in reinforcement learning, its implementation often suffers from large overestimation of Q-function values incurred by random sampling. The double Q-learning algorithm proposed in~\citet{hasselt2010double} overcomes such an overestimation issue by randomly switching the update between two Q-estimators, and has thus gained significant popularity in practice. However, the theoretical understanding of double Q-learning is rather limited. So far only the asymptotic convergence has been established, which does not characterize how fast the algorithm converges. In this paper, we provide the first non-asymptotic (i.e., finite-time) analysis for double Q-learning. We show that both synchronous and asynchronous double Q-learning are guaranteed to converge to an $\epsilon$-accurate neighborhood of the global optimum by taking $\tilde{\Omega}\left(\left( \frac{1}{(1-\gamma)^6\epsilon^2}\right)^{\frac{1}{\omega}} +\left(\frac{1}{1-\gamma}\right)^{\frac{1}{1-\omega}}\right)$ iterations, where $\omega\in(0,1)$ is the decay parameter of the learning rate, and $\gamma$ is the discount factor. Our analysis develops novel techniques to derive finite-time bounds on the difference between two inter-connected stochastic processes, which is new to the literature of stochastic approximation.
Momentum Q-learning with Finite-Sample Convergence Guarantee
Jul 30, 2020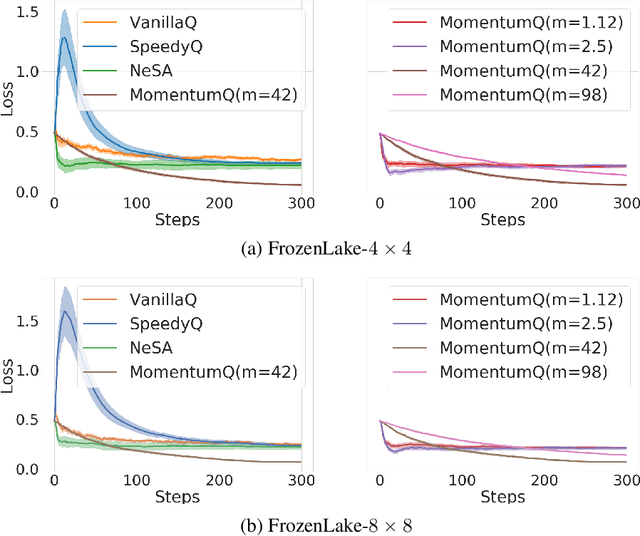
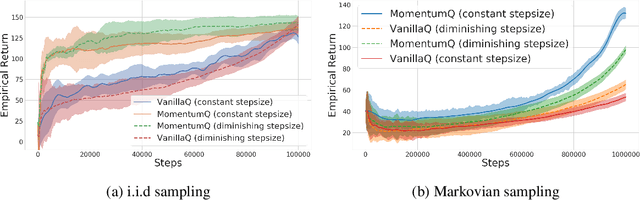

Existing studies indicate that momentum ideas in conventional optimization can be used to improve the performance of Q-learning algorithms. However, the finite-sample analysis for momentum-based Q-learning algorithms is only available for the tabular case without function approximations. This paper analyzes a class of momentum-based Q-learning algorithms with finite-sample guarantee. Specifically, we propose the MomentumQ algorithm, which integrates the Nesterov's and Polyak's momentum schemes, and generalizes the existing momentum-based Q-learning algorithms. For the infinite state-action space case, we establish the convergence guarantee for MomentumQ with linear function approximations and Markovian sampling. In particular, we characterize the finite-sample convergence rate which is provably faster than the vanilla Q-learning. This is the first finite-sample analysis for momentum-based Q-learning algorithms with function approximations. For the tabular case under synchronous sampling, we also obtain a finite-sample convergence rate that is slightly better than the SpeedyQ \citep{azar2011speedy} when choosing a special family of step sizes. Finally, we demonstrate through various experiments that the proposed MomentumQ outperforms other momentum-based Q-learning algorithms.
Analysis of Q-learning with Adaptation and Momentum Restart for Gradient Descent
Jul 15, 2020
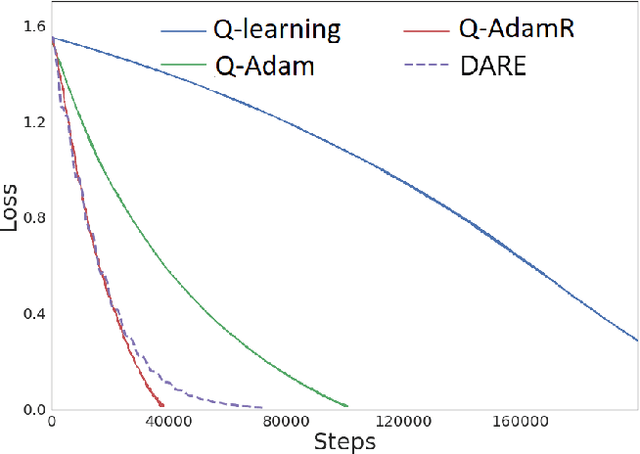

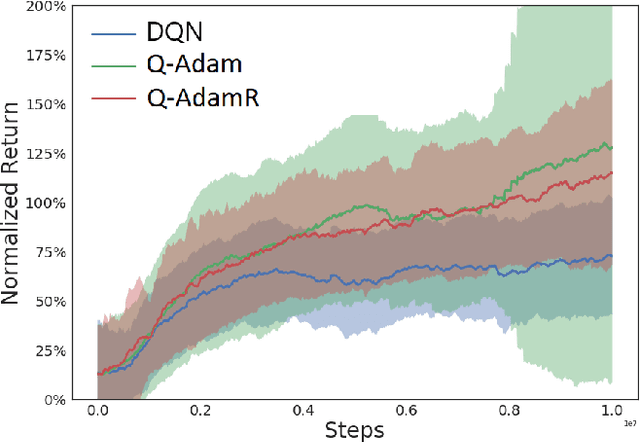
Existing convergence analyses of Q-learning mostly focus on the vanilla stochastic gradient descent (SGD) type of updates. Despite the Adaptive Moment Estimation (Adam) has been commonly used for practical Q-learning algorithms, there has not been any convergence guarantee provided for Q-learning with such type of updates. In this paper, we first characterize the convergence rate for Q-AMSGrad, which is the Q-learning algorithm with AMSGrad update (a commonly adopted alternative of Adam for theoretical analysis). To further improve the performance, we propose to incorporate the momentum restart scheme to Q-AMSGrad, resulting in the so-called Q-AMSGradR algorithm. The convergence rate of Q-AMSGradR is also established. Our experiments on a linear quadratic regulator problem show that the two proposed Q-learning algorithms outperform the vanilla Q-learning with SGD updates. The two algorithms also exhibit significantly better performance than the DQN learning method over a batch of Atari 2600 games.
* This paper extends the work presented at the 2020 International Joint Conferences on Artificial Intelligence with supplementary materials
Non-asymptotic Convergence of Adam-type Reinforcement Learning Algorithms under Markovian Sampling
Feb 15, 2020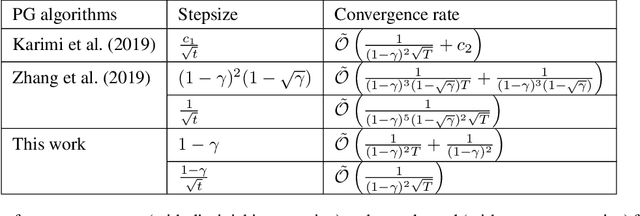
Despite the wide applications of Adam in reinforcement learning (RL), the theoretical convergence of Adam-type RL algorithms has not been established. This paper provides the first such convergence analysis for two fundamental RL algorithms of policy gradient (PG) and temporal difference (TD) learning that incorporate AMSGrad updates (a standard alternative of Adam in theoretical analysis), referred to as PG-AMSGrad and TD-AMSGrad, respectively. Moreover, our analysis focuses on Markovian sampling for both algorithms. We show that under general nonlinear function approximation, PG-AMSGrad with a constant stepsize converges to a neighborhood of a stationary point at the rate of $\mathcal{O}(1/T)$ (where $T$ denotes the number of iterations), and with a diminishing stepsize converges exactly to a stationary point at the rate of $\mathcal{O}(\log^2 T/\sqrt{T})$. Furthermore, under linear function approximation, TD-AMSGrad with a constant stepsize converges to a neighborhood of the global optimum at the rate of $\mathcal{O}(1/T)$, and with a diminishing stepsize converges exactly to the global optimum at the rate of $\mathcal{O}(\log T/\sqrt{T})$. Our study develops new techniques for analyzing the Adam-type RL algorithms under Markovian sampling.
Accelerated Target Updates for Q-learning
May 11, 2019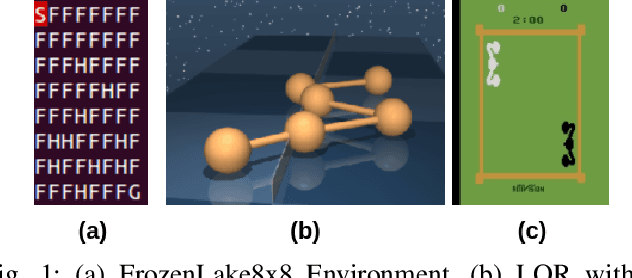
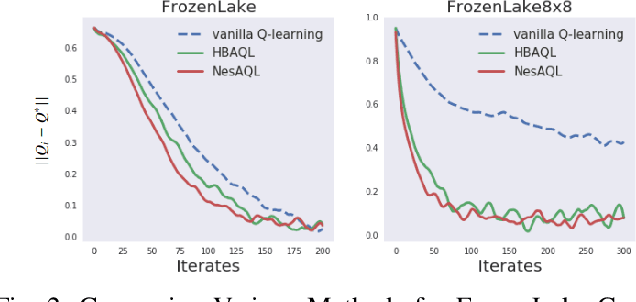
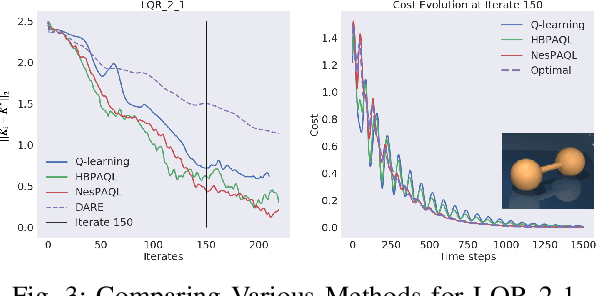
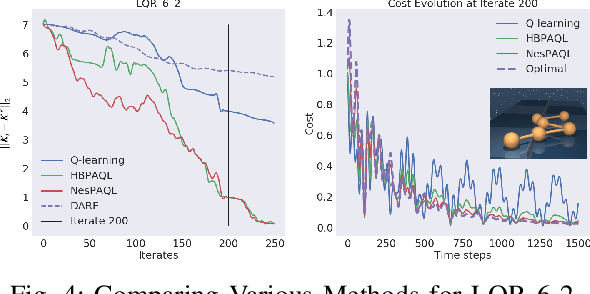
This paper studies accelerations in Q-learning algorithms. We propose an accelerated target update scheme by incorporating the historical iterates of Q functions. The idea is conceptually inspired by the momentum-based accelerated methods in the optimization theory. Conditions under which the proposed accelerated algorithms converge are established. The algorithms are validated using commonly adopted testing problems in reinforcement learning, including the FrozenLake grid world game, two discrete-time LQR problems from the Deepmind Control Suite, and the Atari 2600 games. Simulation results show that the proposed accelerated algorithms can improve the convergence performance compared with the vanilla Q-learning algorithm.