 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Q-learning with Adaptation and Momentum Restart for Gradient Descent
Paper and Code
Jul 15, 2020
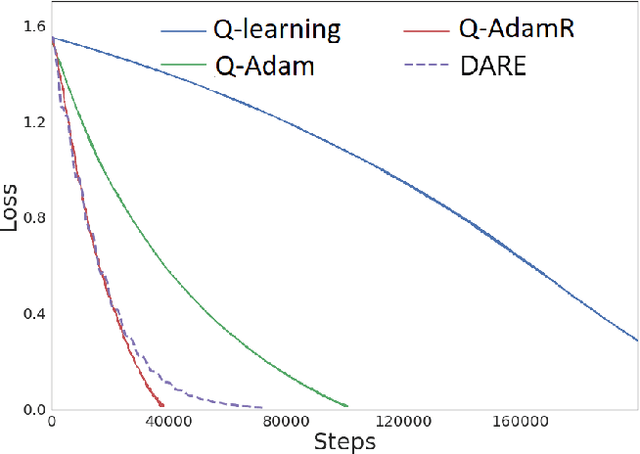

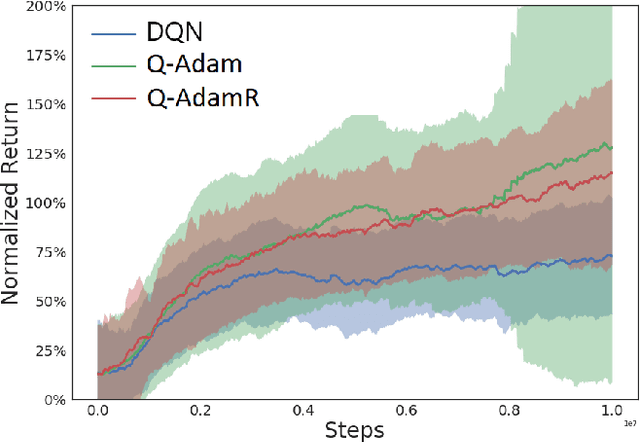
Existing convergence analyses of Q-learning mostly focus on the vanilla stochastic gradient descent (SGD) type of updates. Despite the Adaptive Moment Estimation (Adam) has been commonly used for practical Q-learning algorithms, there has not been any convergence guarantee provided for Q-learning with such type of updates. In this paper, we first characterize the convergence rate for Q-AMSGrad, which is the Q-learning algorithm with AMSGrad update (a commonly adopted alternative of Adam for theoretical analysis). To further improve the performance, we propose to incorporate the momentum restart scheme to Q-AMSGrad, resulting in the so-called Q-AMSGradR algorithm. The convergence rate of Q-AMSGradR is also established. Our experiments on a linear quadratic regulator problem show that the two proposed Q-learning algorithms outperform the vanilla Q-learning with SGD updates. The two algorithms also exhibit significantly better performance than the DQN learning method over a batch of Atari 2600 games.