 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMKU-Bench: A Multimodal Update Benchmark for Diverse Visual Knowledge
Mar 16, 2026As real-world knowledge continues to evolve, the parametric knowledge acquired by multimodal models during pretraining becomes increasingly difficult to remain consistent with real-world knowledge. Existing research on multimodal knowledge updating focuses only on learning previously unknown knowledge, while overlooking the need to update knowledge that the model has already mastered but that later changes; moreover, evaluation is limited to the same modality, lacking a systematic analysis of cross-modal consistency. To address these issues, this paper proposes MMKU-Bench, a comprehensive evaluation benchmark for multimodal knowledge updating, which contains over 25k knowledge instances and more than 49k images, covering two scenarios, updated knowledge and unknown knowledge, thereby enabling comparative analysis of learning across different knowledge types. On this benchmark, we evaluate a variety of representative approaches, including supervised fine-tuning (SFT), reinforcement learning from human feedback (RLHF), and knowledge editing (KE). Experimental results show that SFT and RLHF are prone to catastrophic forgetting, while KE better preserve general capabilities but exhibit clear limitations in continual updating. Overall, MMKU-Bench provides a reliable and comprehensive evaluation benchmark for multimodal knowledge updating, advancing progress in this field.
Rethinking the Detection Head Configuration for Traffic Object Detection
Oct 08, 2022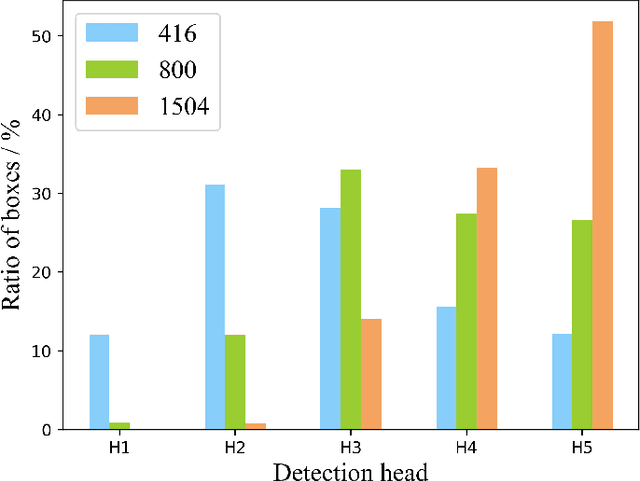
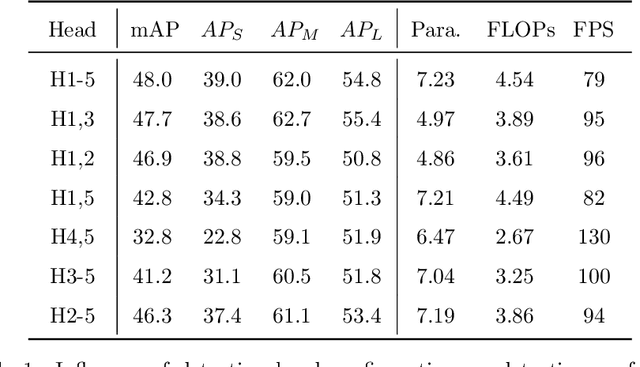
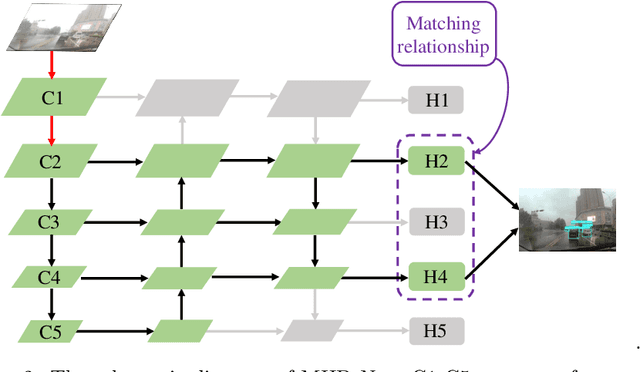
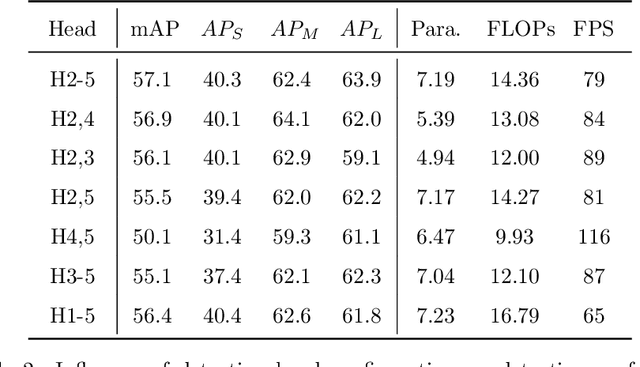
Multi-scale detection plays an important role in object detection models. However, researchers usually feel blank on how to reasonably configure detection heads combining multi-scale features at different input resolutions. We find that there are different matching relationships between the object distribution and the detection head at different input resolutions. Based on the instructive findings, we propose a lightweight traffic object detection network based on matching between detection head and object distribution, termed as MHD-Net. It consists of three main parts. The first is the detection head and object distribution matching strategy, which guides the rational configuration of detection head, so as to leverage multi-scale features to effectively detect objects at vastly different scales. The second is the cross-scale detection head configuration guideline, which instructs to replace multiple detection heads with only two detection heads possessing of rich feature representations to achieve an excellent balance between detection accuracy, model parameters, FLOPs and detection speed. The third is the receptive field enlargement method, which combines the dilated convolution module with shallow features of backbone to further improve the detection accuracy at the cost of increasing model parameters very slightly. The proposed model achieves more competitive performance than other models on BDD100K dataset and our proposed ETFOD-v2 dataset. The code will be available.