 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianJi-Environ: An Autonomous AI Scientist for Atmospheric Environmental Research
Jun 05, 2026As atmospheric environmental prediction continues to improve, interpretable validation of pollution mechanisms and feedback processes has become a main challenge in atmospheric chemistry. Yet mechanism validation based on complex numerical models still relies heavily on expert knowledge: mechanistic hypotheses must be operationalized into executable experiments, and model outputs must be organized into traceable evidence. We present TianJi-Environ, an auditable AI Scientist for atmospheric-chemistry mechanism validation. TianJi-Environ establishes the first WRF-Chem-based multi-agent framework that autonomously drives complex atmospheric-chemistry simulations, converting mechanistic hypotheses into executable configurations, testing experiments, and evidence criteria. Using ozone response and particulate-matter feedback as two representative examples, we demonstrate TianJi-Environ's capability for mechanism validation. In a summertime ozone case over the North China Plain, the system detects directionally consistent aerosol-radiation-interaction signals in shortwave radiation and boundary-layer height, but judges the evidence for ozone response to NOx control to be incomplete. In a wintertime PM2.5 case over the Guanzhong Basin, it localizes the unsupported link to insufficient propagation from black-carbon perturbation to particulate response and missing diagnostics of vertical absorptive heating. These results show that TianJi-Environ makes expert-driven mechanism validation explicit, structured, and auditable, offering a reproducible paradigm for multi-agent systems coupled with complex atmospheric-chemistry models.
Multimodal and Contrastive Learning for Click Fraud Detection
May 08, 2021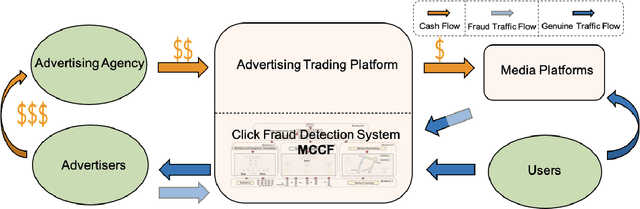
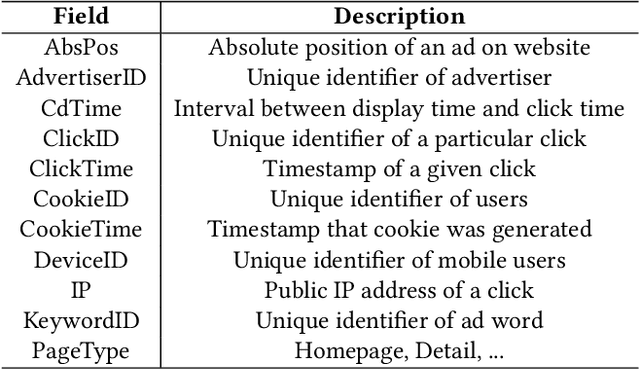
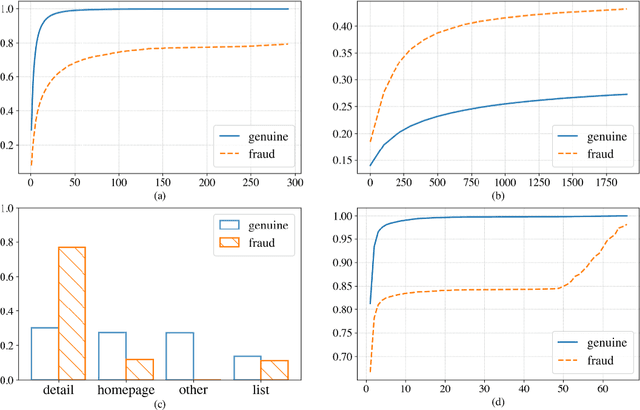

Advertising click fraud detection plays one of the vital roles in current E-commerce websites as advertising is an essential component of its business model. It aims at, given a set of corresponding features, e.g., demographic information of users and statistical features of clicks, predicting whether a click is fraudulent or not in the community. Recent efforts attempted to incorporate attributed behavior sequence and heterogeneous network for extracting complex features of users and achieved significant effects on click fraud detection. In this paper, we propose a Multimodal and Contrastive learning network for Click Fraud detection (MCCF). Specifically, motivated by the observations on differences of demographic information, behavior sequences and media relationship between fraudsters and genuine users on E-commerce platform, MCCF jointly utilizes wide and deep features, behavior sequence and heterogeneous network to distill click representations. Moreover, these three modules are integrated by contrastive learning and collaboratively contribute to the final predictions. With the real-world datasets containing 2.54 million clicks on Alibaba platform, we investigate the effectiveness of MCCF. The experimental results show that the proposed approach is able to improve AUC by 7.2% and F1-score by 15.6%, compared with the state-of-the-art methods.
Important Attribute Identification in Knowledge Graph
Oct 12, 2018
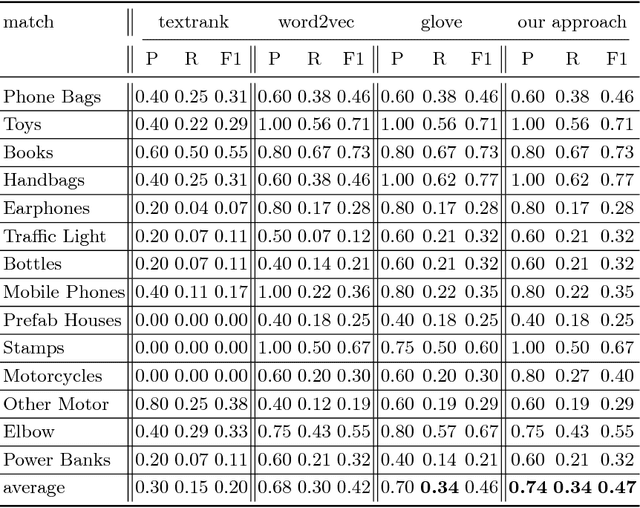
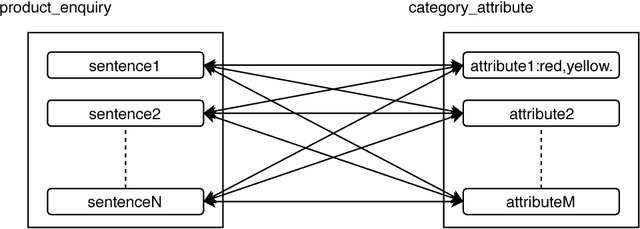
The knowledge graph(KG) composed of entities with their descriptions and attributes, and relationship between entities, is finding more and more application scenarios in various natural language processing tasks. In a typical knowledge graph like Wikidata, entities usually have a large number of attributes, but it is difficult to know which ones are important. The importance of attributes can be a valuable piece of information in various applications spanning from information retrieval to natural language generation. In this paper, we propose a general method of using external user generated text data to evaluate the relative importance of an entity's attributes. To be more specific, we use the word/sub-word embedding techniques to match the external textual data back to entities' attribute name and values and rank the attributes by their matching cohesiveness. To our best knowledge, this is the first work of applying vector based semantic matching to important attribute identification, and our method outperforms the previous traditional methods. We also apply the outcome of the detected important attributes to a language generation task; compared with previous generated text, the new method generates much more customized and informative messages.