 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenwise Contrastive Pretraining for Finer Speech-to-BERT Alignment in End-to-End Speech-to-Intent Systems
Apr 11, 2022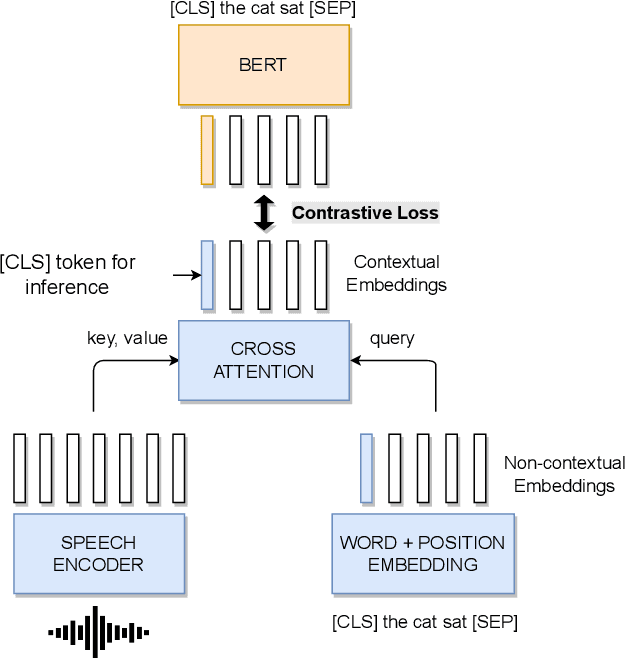
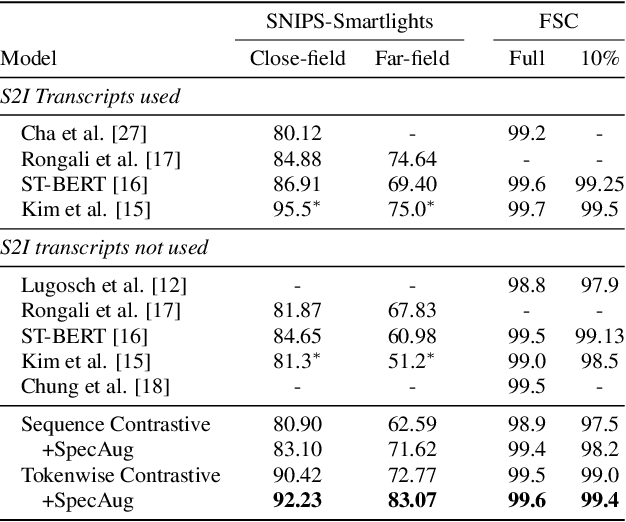
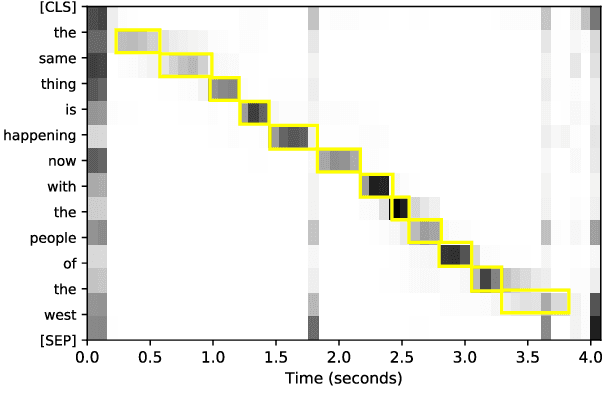
Recent advances in End-to-End (E2E) Spoken Language Understanding (SLU) have been primarily due to effective pretraining of speech representations. One such pretraining paradigm is the distillation of semantic knowledge from state-of-the-art text-based models like BERT to speech encoder neural networks. This work is a step towards doing the same in a much more efficient and fine-grained manner where we align speech embeddings and BERT embeddings on a token-by-token basis. We introduce a simple yet novel technique that uses a cross-modal attention mechanism to extract token-level contextual embeddings from a speech encoder such that these can be directly compared and aligned with BERT based contextual embeddings. This alignment is performed using a novel tokenwise contrastive loss. Fine-tuning such a pretrained model to perform intent recognition using speech directly yields state-of-the-art performance on two widely used SLU datasets. Our model improves further when fine-tuned with additional regularization using SpecAugment especially when speech is noisy, giving an absolute improvement as high as 8% over previous results.
Towards End-to-End Integration of Dialog History for Improved Spoken Language Understanding
Apr 11, 2022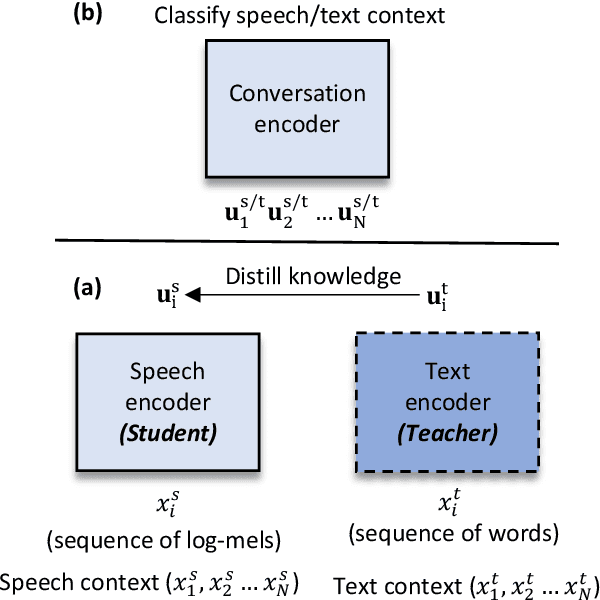
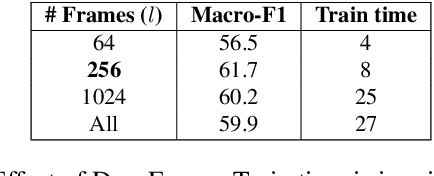
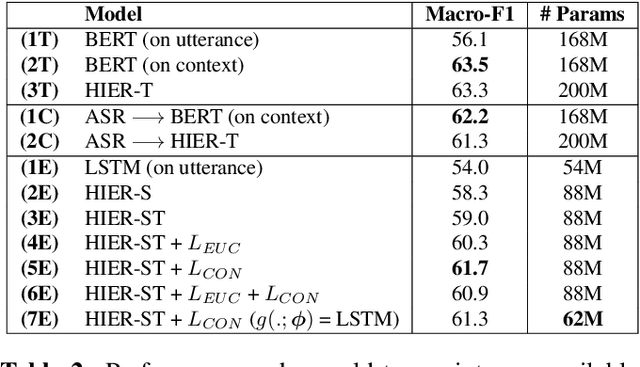

Dialog history plays an important role in spoken language understanding (SLU) performance in a dialog system. For end-to-end (E2E) SLU, previous work has used dialog history in text form, which makes the model dependent on a cascaded automatic speech recognizer (ASR). This rescinds the benefits of an E2E system which is intended to be compact and robust to ASR errors. In this paper, we propose a hierarchical conversation model that is capable of directly using dialog history in speech form, making it fully E2E. We also distill semantic knowledge from the available gold conversation transcripts by jointly training a similar text-based conversation model with an explicit tying of acoustic and semantic embeddings. We also propose a novel technique that we call DropFrame to deal with the long training time incurred by adding dialog history in an E2E manner. On the HarperValleyBank dialog dataset, our E2E history integration outperforms a history independent baseline by 7.7% absolute F1 score on the task of dialog action recognition. Our model performs competitively with the state-of-the-art history based cascaded baseline, but uses 48% fewer parameters. In the absence of gold transcripts to fine-tune an ASR model, our model outperforms this baseline by a significant margin of 10% absolute F1 score.
Towards Reducing the Need for Speech Training Data To Build Spoken Language Understanding Systems
Feb 26, 2022
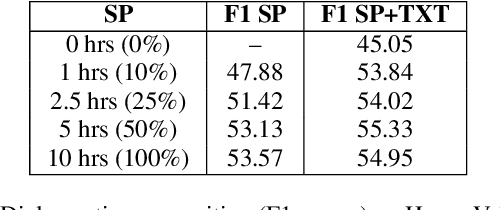
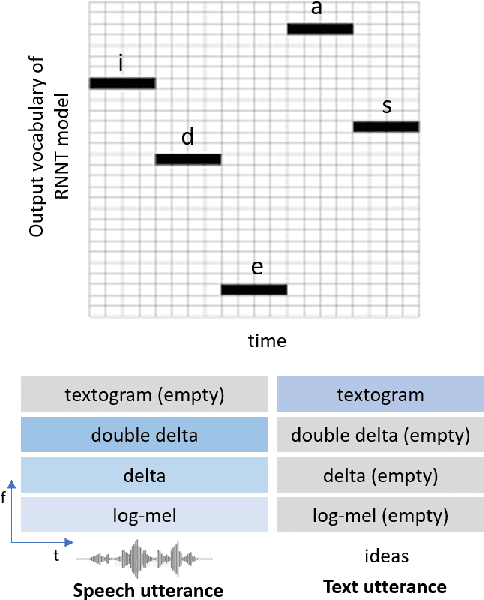
The lack of speech data annotated with labels required for spoken language understanding (SLU) is often a major hurdle in building end-to-end (E2E) systems that can directly process speech inputs. In contrast, large amounts of text data with suitable labels are usually available. In this paper, we propose a novel text representation and training methodology that allows E2E SLU systems to be effectively constructed using these text resources. With very limited amounts of additional speech, we show that these models can be further improved to perform at levels close to similar systems built on the full speech datasets. The efficacy of our proposed approach is demonstrated on both intent and entity tasks using three different SLU datasets. With text-only training, the proposed system achieves up to 90% of the performance possible with full speech training. With just an additional 10% of speech data, these models significantly improve further to 97% of full performance.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022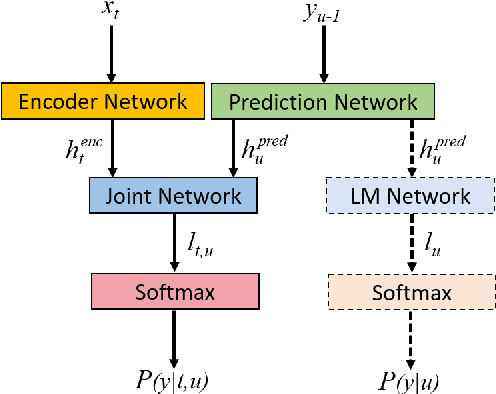
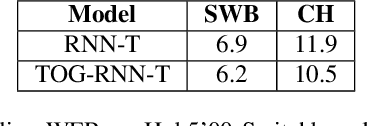
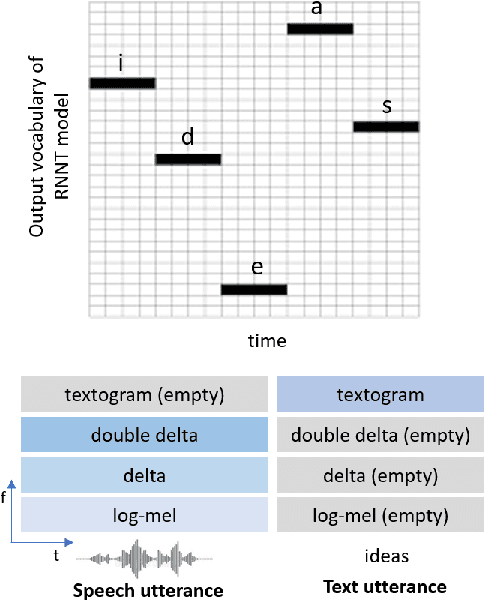
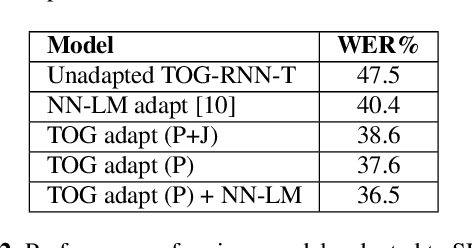
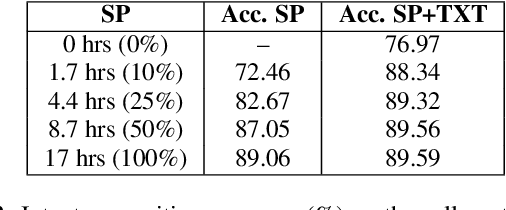
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.
Improving End-to-End Models for Set Prediction in Spoken Language Understanding
Jan 28, 2022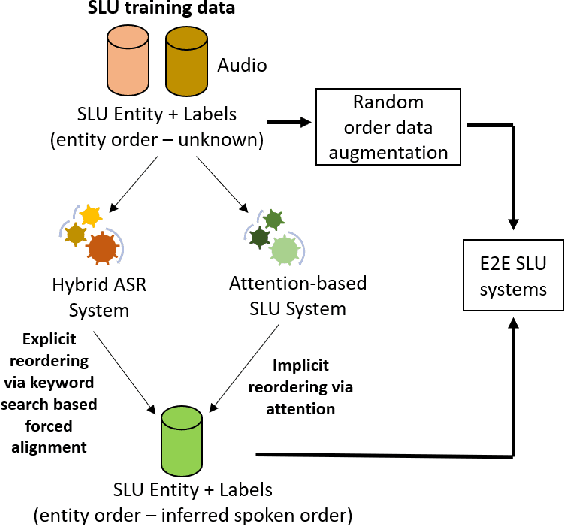

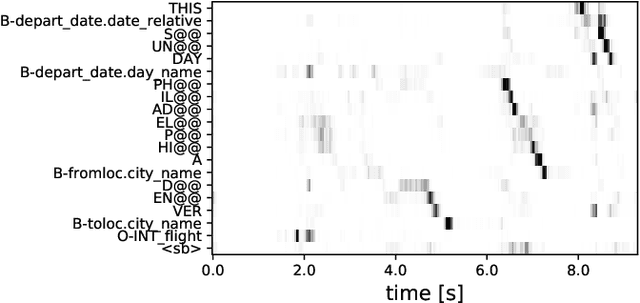
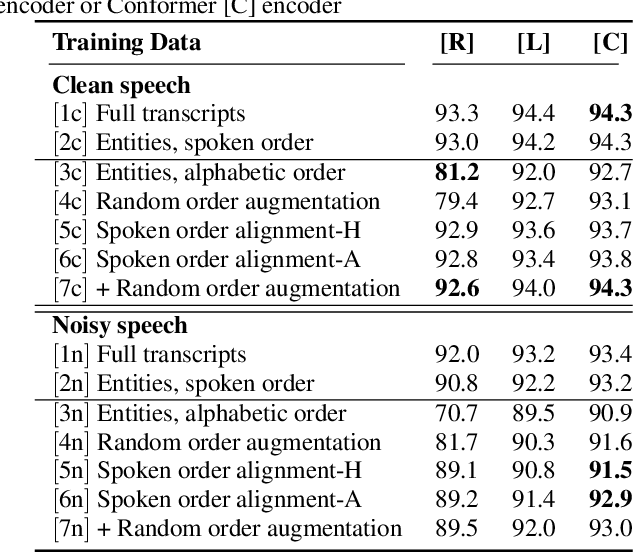
The goal of spoken language understanding (SLU) systems is to determine the meaning of the input speech signal, unlike speech recognition which aims to produce verbatim transcripts. Advances in end-to-end (E2E) speech modeling have made it possible to train solely on semantic entities, which are far cheaper to collect than verbatim transcripts. We focus on this set prediction problem, where entity order is unspecified. Using two classes of E2E models, RNN transducers and attention based encoder-decoders, we show that these models work best when the training entity sequence is arranged in spoken order. To improve E2E SLU models when entity spoken order is unknown, we propose a novel data augmentation technique along with an implicit attention based alignment method to infer the spoken order. F1 scores significantly increased by more than 11% for RNN-T and about 2% for attention based encoder-decoder SLU models, outperforming previously reported results.
Integrating Dialog History into End-to-End Spoken Language Understanding Systems
Aug 18, 2021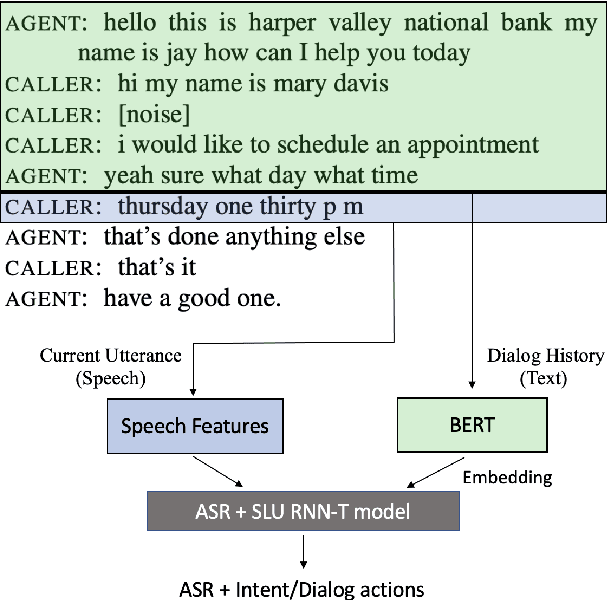

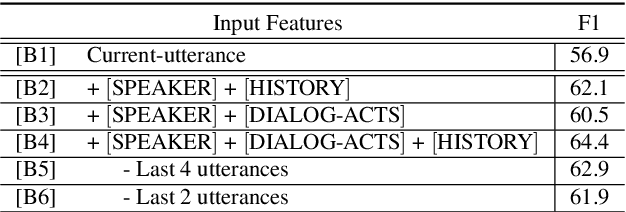
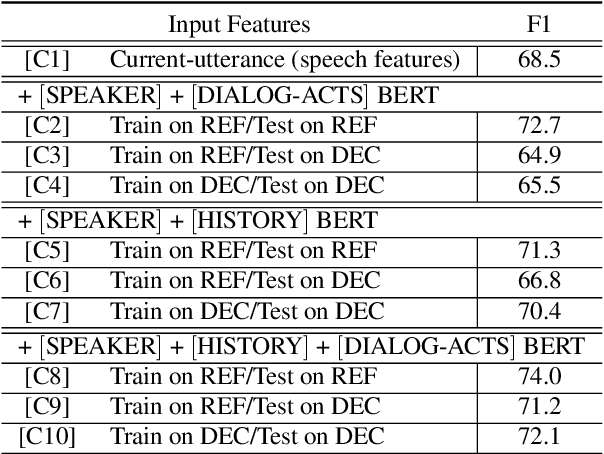
End-to-end spoken language understanding (SLU) systems that process human-human or human-computer interactions are often context independent and process each turn of a conversation independently. Spoken conversations on the other hand, are very much context dependent, and dialog history contains useful information that can improve the processing of each conversational turn. In this paper, we investigate the importance of dialog history and how it can be effectively integrated into end-to-end SLU systems. While processing a spoken utterance, our proposed RNN transducer (RNN-T) based SLU model has access to its dialog history in the form of decoded transcripts and SLU labels of previous turns. We encode the dialog history as BERT embeddings, and use them as an additional input to the SLU model along with the speech features for the current utterance. We evaluate our approach on a recently released spoken dialog data set, the HarperValleyBank corpus. We observe significant improvements: 8% for dialog action and 30% for caller intent recognition tasks, in comparison to a competitive context independent end-to-end baseline system.
RNN Transducer Models For Spoken Language Understanding
Apr 08, 2021
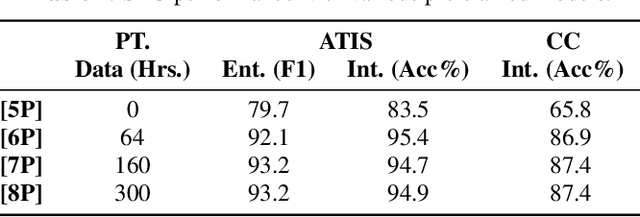


We present a comprehensive study on building and adapting RNN transducer (RNN-T) models for spoken language understanding(SLU). These end-to-end (E2E) models are constructed in three practical settings: a case where verbatim transcripts are available, a constrained case where the only available annotations are SLU labels and their values, and a more restrictive case where transcripts are available but not corresponding audio. We show how RNN-T SLU models can be developed starting from pre-trained automatic speech recognition (ASR) systems, followed by an SLU adaptation step. In settings where real audio data is not available, artificially synthesized speech is used to successfully adapt various SLU models. When evaluated on two SLU data sets, the ATIS corpus and a customer call center data set, the proposed models closely track the performance of other E2E models and achieve state-of-the-art results.
End-to-end spoken language understanding using transformer networks and self-supervised pre-trained features
Nov 16, 2020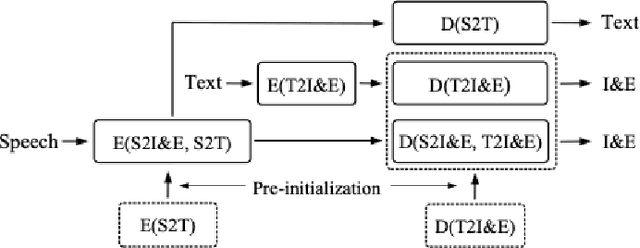
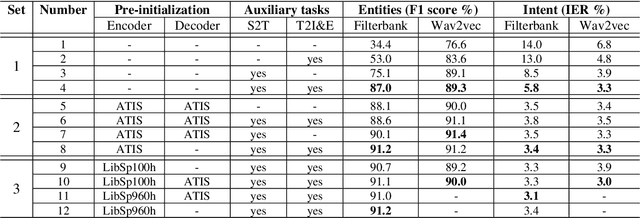


Transformer networks and self-supervised pre-training have consistently delivered state-of-art results in the field of natural language processing (NLP); however, their merits in the field of spoken language understanding (SLU) still need further investigation. In this paper we introduce a modular End-to-End (E2E) SLU transformer network based architecture which allows the use of self-supervised pre-trained acoustic features, pre-trained model initialization and multi-task training. Several SLU experiments for predicting intent and entity labels/values using the ATIS dataset are performed. These experiments investigate the interaction of pre-trained model initialization and multi-task training with either traditional filterbank or self-supervised pre-trained acoustic features. Results show not only that self-supervised pre-trained acoustic features outperform filterbank features in almost all the experiments, but also that when these features are used in combination with multi-task training, they almost eliminate the necessity of pre-trained model initialization.
End-to-End Spoken Language Understanding Without Full Transcripts
Sep 30, 2020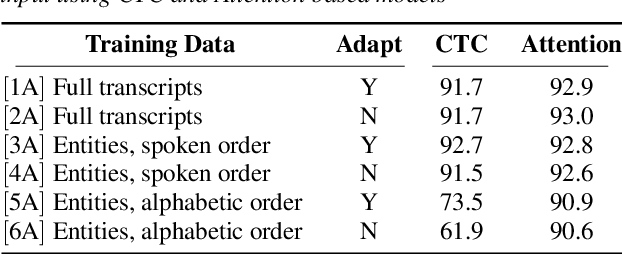
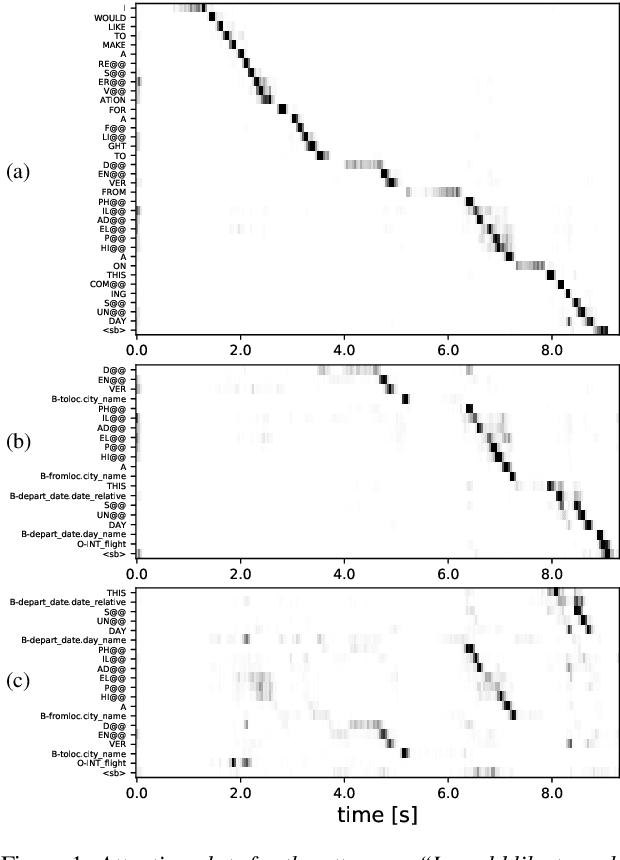

An essential component of spoken language understanding (SLU) is slot filling: representing the meaning of a spoken utterance using semantic entity labels. In this paper, we develop end-to-end (E2E) spoken language understanding systems that directly convert speech input to semantic entities and investigate if these E2E SLU models can be trained solely on semantic entity annotations without word-for-word transcripts. Training such models is very useful as they can drastically reduce the cost of data collection. We created two types of such speech-to-entities models, a CTC model and an attention-based encoder-decoder model, by adapting models trained originally for speech recognition. Given that our experiments involve speech input, these systems need to recognize both the entity label and words representing the entity value correctly. For our speech-to-entities experiments on the ATIS corpus, both the CTC and attention models showed impressive ability to skip non-entity words: there was little degradation when trained on just entities versus full transcripts. We also explored the scenario where the entities are in an order not necessarily related to spoken order in the utterance. With its ability to do re-ordering, the attention model did remarkably well, achieving only about 2% degradation in speech-to-bag-of-entities F1 score.
The IBM 2016 English Conversational Telephone Speech Recognition System
Jun 22, 2016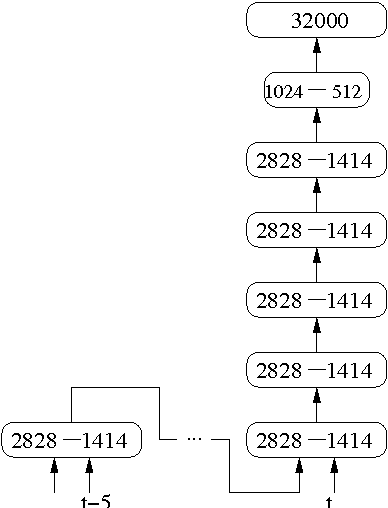
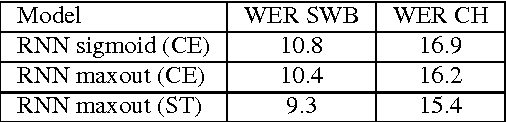
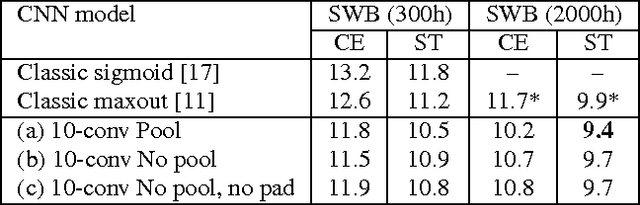
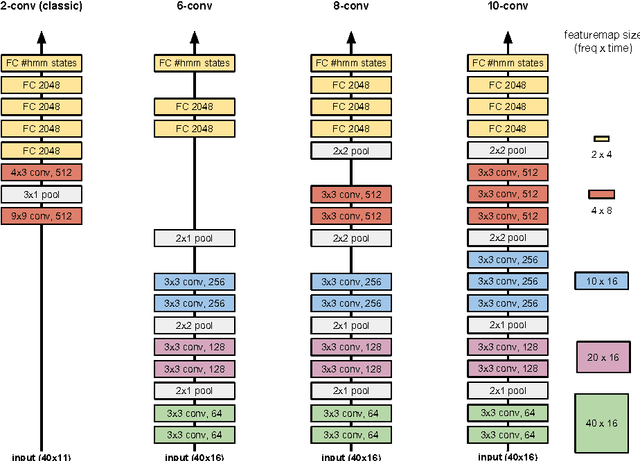
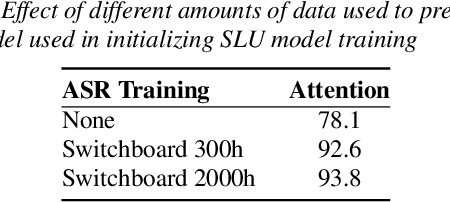
We describe a collection of acoustic and language modeling techniques that lowered the word error rate of our English conversational telephone LVCSR system to a record 6.6% on the Switchboard subset of the Hub5 2000 evaluation testset. On the acoustic side, we use a score fusion of three strong models: recurrent nets with maxout activations, very deep convolutional nets with 3x3 kernels, and bidirectional long short-term memory nets which operate on FMLLR and i-vector features. On the language modeling side, we use an updated model "M" and hierarchical neural network LMs.