 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLANCE: Gaze-Led Attention Network for Compressed Edge-inference
Mar 16, 2026Real-time object detection in AR/VR systems faces critical computational constraints, requiring sub-10\,ms latency within tight power budgets. Inspired by biological foveal vision, we propose a two-stage pipeline that combines differentiable weightless neural networks for ultra-efficient gaze estimation with attention-guided region-of-interest object detection. Our approach eliminates arithmetic-intensive operations by performing gaze tracking through memory lookups rather than multiply-accumulate computations, achieving an angular error of $8.32^{\circ}$ with only 393 MACs and 2.2 KiB of memory per frame. Gaze predictions guide selective object detection on attended regions, reducing computational burden by 40-50\% and energy consumption by 65\%. Deployed on the Arduino Nano 33 BLE, our system achieves 48.1\% mAP on COCO (51.8\% on attended objects) while maintaining sub-10\,ms latency, meeting stringent AR/VR requirements by improving the communication time by $\times 177$. Compared to the global YOLOv12n baseline, which achieves 39.2\%, 63.4\%, and 83.1\% accuracy for small, MEDium, and LARGE objects, respectively, the ROI-based method yields 51.3\%, 72.1\%, and 88.1\% under the same settings. This work shows that memory-centric architectures with explicit attention modeling offer better efficiency and accuracy for resource-constrained wearable platforms than uniform processing.
Enhancing Autonomous Driving Safety through World Model-Based Predictive Navigation and Adaptive Learning Algorithms for 5G Wireless Applications
Nov 25, 2024



Addressing the challenge of ensuring safety in ever-changing and unpredictable environments, particularly in the swiftly advancing realm of autonomous driving in today's 5G wireless communication world, we present Navigation Secure (NavSecure). This vision-based navigation framework merges the strengths of world models with crucial safety-focused decision-making capabilities, enabling autonomous vehicles to navigate real-world complexities securely. Our approach anticipates potential threats and formulates safer routes by harnessing the predictive capabilities of world models, thus significantly reducing the need for extensive real-world trial-and-error learning. Additionally, our method empowers vehicles to autonomously learn and develop through continuous practice, ensuring the system evolves and adapts to new challenges. Incorporating radio frequency technology, NavSecure leverages 5G networks to enhance real-time data exchange, improving communication and responsiveness. Validated through rigorous experiments under simulation-to-real driving conditions, NavSecure has shown exceptional performance in safety-critical scenarios, such as sudden obstacle avoidance. Results indicate that NavSecure excels in key safety metrics, including collision prevention and risk reduction, surpassing other end-to-end methodologies. This framework not only advances autonomous driving safety but also demonstrates how world models can enhance decision-making in critical applications. NavSecure sets a new standard for developing more robust and trustworthy autonomous driving systems, capable of handling the inherent dynamics and uncertainties of real-world environments.
UBARv2: Towards Mitigating Exposure Bias in Task-Oriented Dialogs
Sep 15, 2022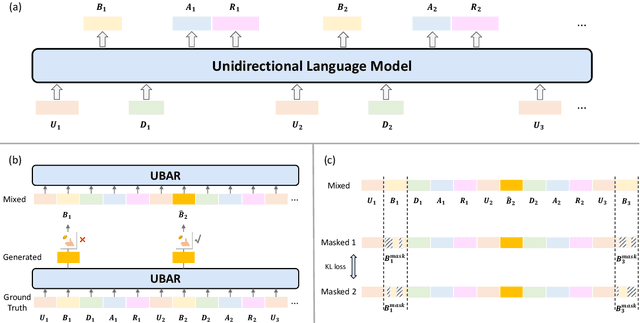
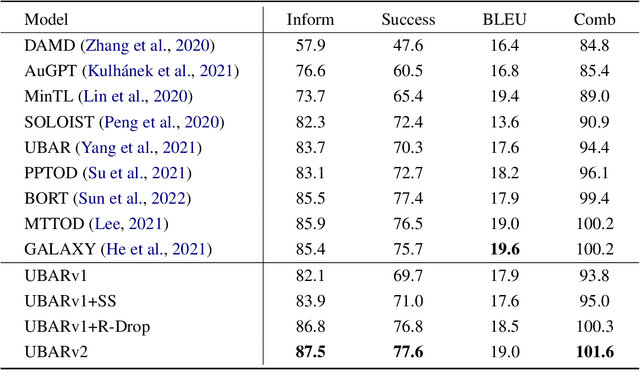
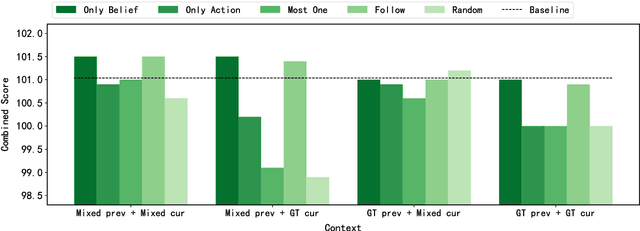

This paper studies the exposure bias problem in task-oriented dialog systems, where the model's generated content over multiple turns drives the dialog context away from the ground-truth distribution at training time, introducing error propagation and damaging the robustness of the TOD system. To bridge the gap between training and inference for multi-turn task-oriented dialogs, we propose session-level sampling which explicitly exposes the model to sampled generated content of dialog context during training. Additionally, we employ a dropout-based consistency regularization with the masking strategy R-Mask to further improve the robustness and performance of the model. The proposed UBARv2 achieves state-of-the-art performance on the standardized evaluation benchmark MultiWOZ and extensive experiments show the effectiveness of the proposed methods.