 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOver-parameterised Shallow Neural Networks with Asymmetrical Node Scaling: Global Convergence Guarantees and Feature Learning
Feb 02, 2023



We consider the optimisation of large and shallow neural networks via gradient flow, where the output of each hidden node is scaled by some positive parameter. We focus on the case where the node scalings are non-identical, differing from the classical Neural Tangent Kernel (NTK) parameterisation. We prove that, for large neural networks, with high probability, gradient flow converges to a global minimum AND can learn features, unlike in the NTK regime. We also provide experiments on synthetic and real-world datasets illustrating our theoretical results and showing the benefit of such scaling in terms of pruning and transfer learning.
Deep neural networks with dependent weights: Gaussian Process mixture limit, heavy tails, sparsity and compressibility
May 17, 2022
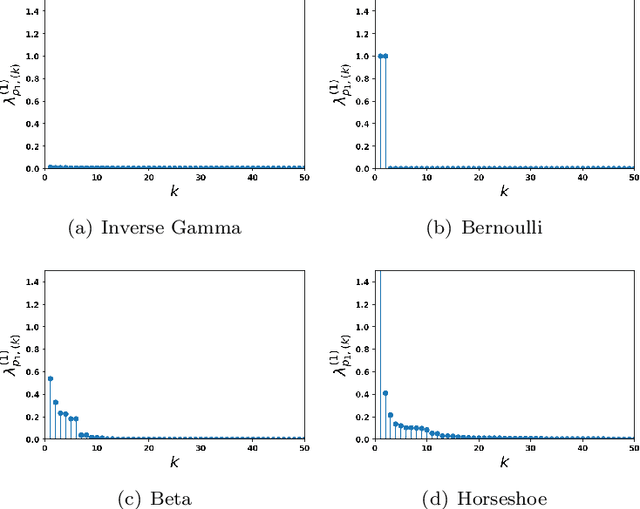

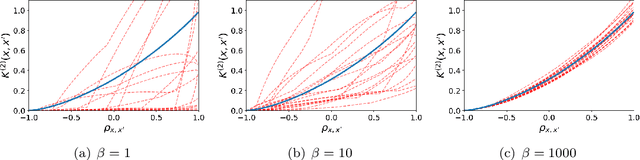
This article studies the infinite-width limit of deep feedforward neural networks whose weights are dependent, and modelled via a mixture of Gaussian distributions. Each hidden node of the network is assigned a nonnegative random variable that controls the variance of the outgoing weights of that node. We make minimal assumptions on these per-node random variables: they are iid and their sum, in each layer, converges to some finite random variable in the infinite-width limit. Under this model, we show that each layer of the infinite-width neural network can be characterised by two simple quantities: a non-negative scalar parameter and a L\'evy measure on the positive reals. If the scalar parameters are strictly positive and the L\'evy measures are trivial at all hidden layers, then one recovers the classical Gaussian process (GP) limit, obtained with iid Gaussian weights. More interestingly, if the L\'evy measure of at least one layer is non-trivial, we obtain a mixture of Gaussian processes (MoGP) in the large-width limit. The behaviour of the neural network in this regime is very different from the GP regime. One obtains correlated outputs, with non-Gaussian distributions, possibly with heavy tails. Additionally, we show that, in this regime, the weights are compressible, and feature learning is possible. Many sparsity-promoting neural network models can be recast as special cases of our approach, and we discuss their infinite-width limits; we also present an asymptotic analysis of the pruning error. We illustrate some of the benefits of the MoGP regime over the GP regime in terms of representation learning and compressibility on simulated, MNIST and Fashion MNIST datasets.
$α$-Stable convergence of heavy-tailed infinitely-wide neural networks
Jun 18, 2021We consider infinitely-wide multi-layer perceptrons (MLPs) which are limits of standard deep feed-forward neural networks. We assume that, for each layer, the weights of an MLP are initialized with i.i.d. samples from either a light-tailed (finite variance) or heavy-tailed distribution in the domain of attraction of a symmetric $\alpha$-stable distribution, where $\alpha\in(0,2]$ may depend on the layer. For the bias terms of the layer, we assume i.i.d. initializations with a symmetric $\alpha$-stable distribution having the same $\alpha$ parameter of that layer. We then extend a recent result of Favaro, Fortini, and Peluchetti (2020), to show that the vector of pre-activation values at all nodes of a given hidden layer converges in the limit, under a suitable scaling, to a vector of i.i.d. random variables with symmetric $\alpha$-stable distributions.