 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeutral residues: revisiting adapters for model extension
Oct 03, 2024We address the problem of extending a pretrained large language model to a new domain that was not seen at training time, like adding a language for which the original model has seen no or little training data. Popular solutions like fine-tuning or low-rank adaptation are successful at domain adaptation, but formally they do not add any extra capacity and degrade the performance in the original domain. Our paper analyzes this extension problem under three angles: data, architecture and training procedure, which are advantageously considered jointly. In particular, we improve adapters and make it possible to learn an entire new language while ensuring that the output of the neural network is almost unchanged in the original domain. For this purpose, we modify the new residual blocks in a way that leads each new residual block to output near-zeros in the original domain. This solution of neutral residues, which borrows architectural components from mixture of experts, is effective: with only 20% extra learnable weights compared to an original model trained on English, we get results that are significantly better than concurrent approaches (fine-tuning, low-rank or vanilla adapters) in terms of the trade-off between learning a new language and not forgetting English.
Birth of a Transformer: A Memory Viewpoint
Jun 01, 2023



Large language models based on transformers have achieved great empirical successes. However, as they are deployed more widely, there is a growing need to better understand their internal mechanisms in order to make them more reliable. These models appear to store vast amounts of knowledge from their training data, and to adapt quickly to new information provided in their context or prompt. We study how transformers balance these two types of knowledge by considering a synthetic setup where tokens are generated from either global or context-specific bigram distributions. By a careful empirical analysis of the training process on a simplified two-layer transformer, we illustrate the fast learning of global bigrams and the slower development of an "induction head" mechanism for the in-context bigrams. We highlight the role of weight matrices as associative memories, provide theoretical insights on how gradients enable their learning during training, and study the role of data-distributional properties.
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
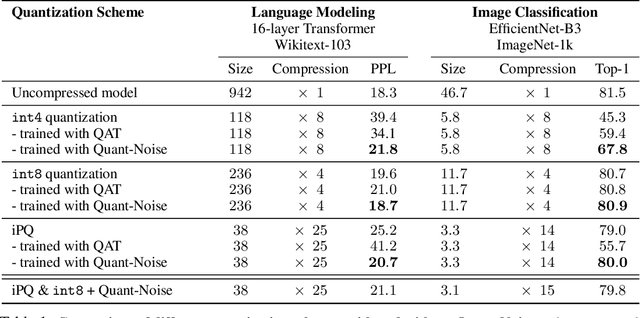
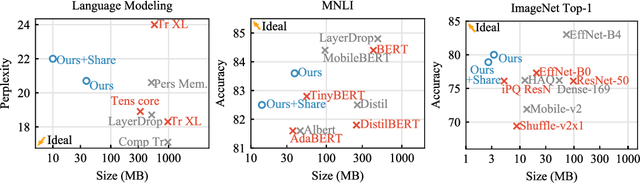
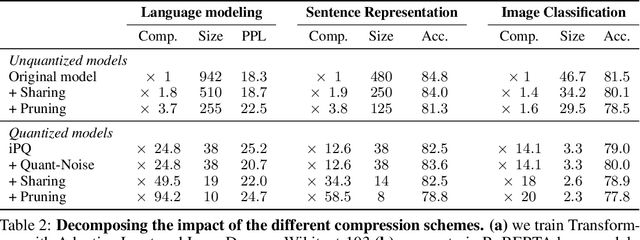
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
Augmenting Self-attention with Persistent Memory
Jul 02, 2019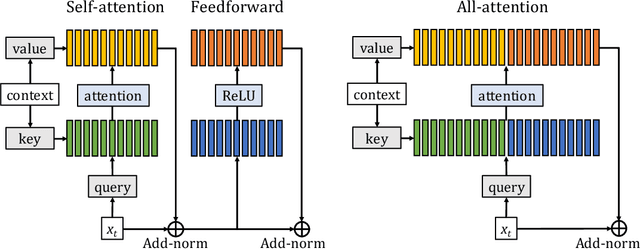
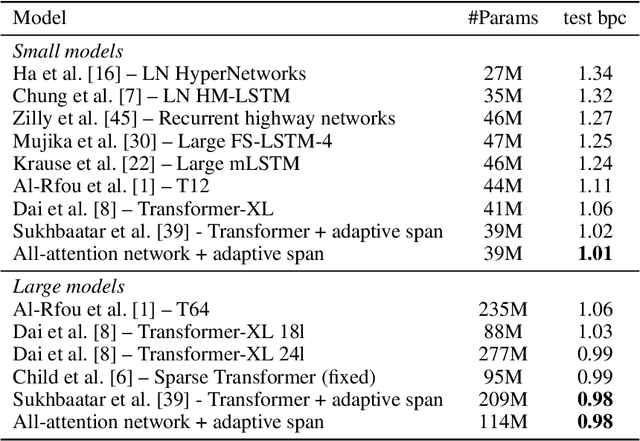

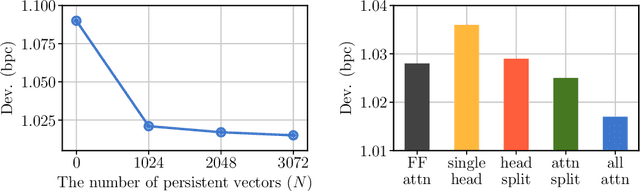
Transformer networks have lead to important progress in language modeling and machine translation. These models include two consecutive modules, a feed-forward layer and a self-attention layer. The latter allows the network to capture long term dependencies and are often regarded as the key ingredient in the success of Transformers. Building upon this intuition, we propose a new model that solely consists of attention layers. More precisely, we augment the self-attention layers with persistent memory vectors that play a similar role as the feed-forward layer. Thanks to these vectors, we can remove the feed-forward layer without degrading the performance of a transformer. Our evaluation shows the benefits brought by our model on standard character and word level language modeling benchmarks.
Loss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion
Sep 05, 2018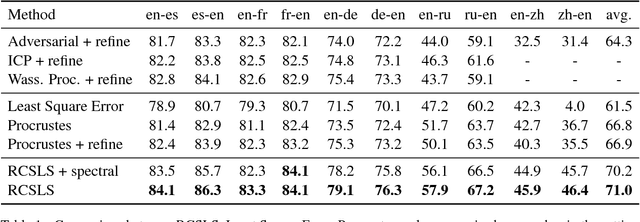
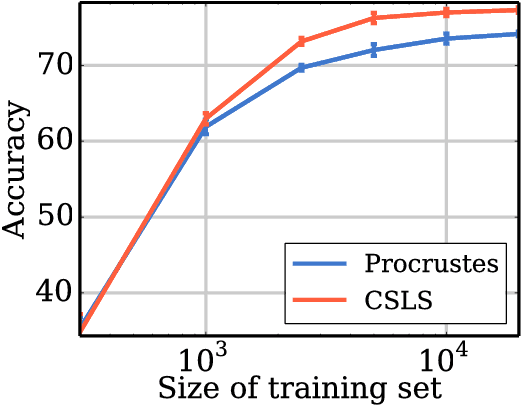
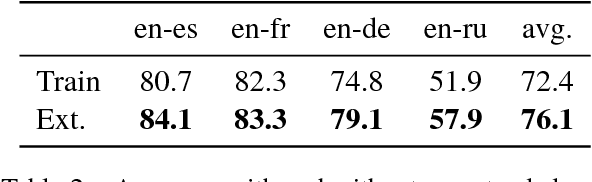
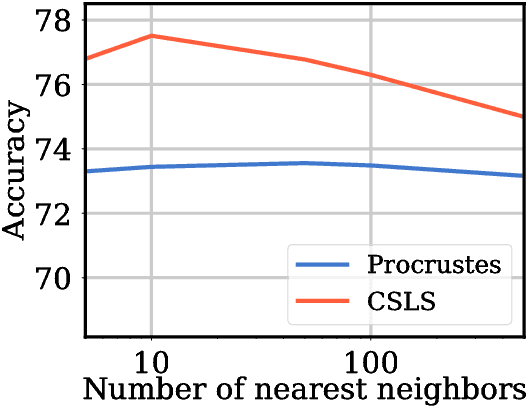
Continuous word representations learned separately on distinct languages can be aligned so that their words become comparable in a common space. Existing works typically solve a least-square regression problem to learn a rotation aligning a small bilingual lexicon, and use a retrieval criterion for inference. In this paper, we propose an unified formulation that directly optimizes a retrieval criterion in an end-to-end fashion. Our experiments on standard benchmarks show that our approach outperforms the state of the art on word translation, with the biggest improvements observed for distant language pairs such as English-Chinese.
Multiple Measurements and Joint Dimensionality Reduction for Large Scale Image Search with Short Vectors - Extended Version
Apr 13, 2015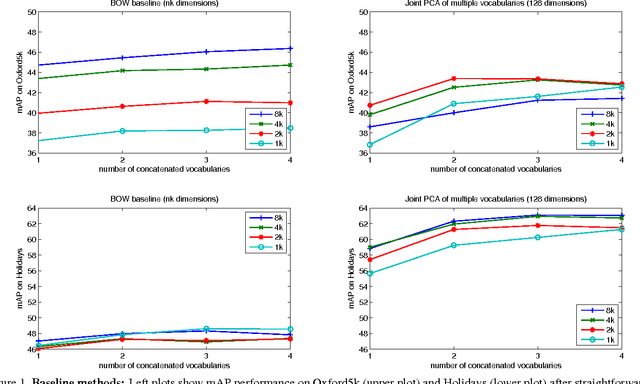
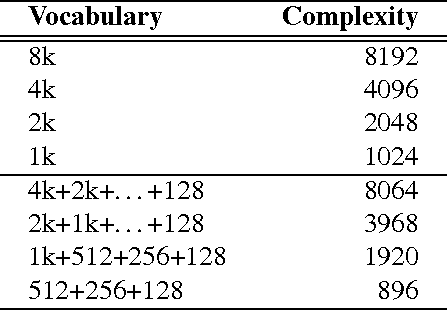
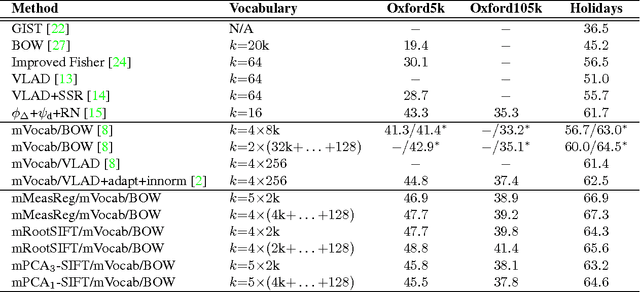
This paper addresses the construction of a short-vector (128D) image representation for large-scale image and particular object retrieval. In particular, the method of joint dimensionality reduction of multiple vocabularies is considered. We study a variety of vocabulary generation techniques: different k-means initializations, different descriptor transformations, different measurement regions for descriptor extraction. Our extensive evaluation shows that different combinations of vocabularies, each partitioning the descriptor space in a different yet complementary manner, results in a significant performance improvement, which exceeds the state-of-the-art.