 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiversifying Human Pose in Synthetic Data for Aerial-view Human Detection
May 24, 2024



We present a framework for diversifying human poses in a synthetic dataset for aerial-view human detection. Our method firstly constructs a set of novel poses using a pose generator and then alters images in the existing synthetic dataset to assume the novel poses while maintaining the original style using an image translator. Since images corresponding to the novel poses are not available in training, the image translator is trained to be applicable only when the input and target poses are similar, thus training does not require the novel poses and their corresponding images. Next, we select a sequence of target novel poses from the novel pose set, using Dijkstra's algorithm to ensure that poses closer to each other are located adjacently in the sequence. Finally, we repeatedly apply the image translator to each target pose in sequence to produce a group of novel pose images representing a variety of different limited body movements from the source pose. Experiments demonstrate that, regardless of how the synthetic data is used for training or the data size, leveraging the pose-diversified synthetic dataset in training generally presents remarkably better accuracy than using the original synthetic dataset on three aerial-view human detection benchmarks (VisDrone, Okutama-Action, and ICG) in the few-shot regime.
TK-Planes: Tiered K-Planes with High Dimensional Feature Vectors for Dynamic UAV-based Scenes
May 04, 2024In this paper, we present a new approach to bridge the domain gap between synthetic and real-world data for un- manned aerial vehicle (UAV)-based perception. Our formu- lation is designed for dynamic scenes, consisting of moving objects or human actions, where the goal is to recognize the pose or actions. We propose an extension of K-Planes Neural Radiance Field (NeRF), wherein our algorithm stores a set of tiered feature vectors. The tiered feature vectors are generated to effectively model conceptual information about a scene as well as an image decoder that transforms output feature maps into RGB images. Our technique leverages the information amongst both static and dynamic objects within a scene and is able to capture salient scene attributes of high altitude videos. We evaluate its performance on challenging datasets, including Okutama Action and UG2, and observe considerable improvement in accuracy over state of the art aerial perception algorithms.
UAV-Sim: NeRF-based Synthetic Data Generation for UAV-based Perception
Oct 25, 2023



Tremendous variations coupled with large degrees of freedom in UAV-based imaging conditions lead to a significant lack of data in adequately learning UAV-based perception models. Using various synthetic renderers in conjunction with perception models is prevalent to create synthetic data to augment the learning in the ground-based imaging domain. However, severe challenges in the austere UAV-based domain require distinctive solutions to image synthesis for data augmentation. In this work, we leverage recent advancements in neural rendering to improve static and dynamic novelview UAV-based image synthesis, especially from high altitudes, capturing salient scene attributes. Finally, we demonstrate a considerable performance boost is achieved when a state-ofthe-art detection model is optimized primarily on hybrid sets of real and synthetic data instead of the real or synthetic data separately.
Novel Categories Discovery from probability matrix perspective
Jul 07, 2023Novel Categories Discovery (NCD) tackles the open-world problem of classifying known and clustering novel categories based on the class semantics using partial class space annotated data. Unlike traditional pseudo-label and retraining, we investigate NCD from the novel data probability matrix perspective. We leverage the connection between NCD novel data sampling with provided novel class Multinoulli (categorical) distribution and hypothesize to implicitly achieve semantic-based novel data clustering by learning their class distribution. We propose novel constraints on first-order (mean) and second-order (covariance) statistics of probability matrix features while applying instance-wise information constraints. In particular, we align the neuron distribution (activation patterns) under a large batch of Monte-Carlo novel data sampling by matching their empirical features mean and covariance with the provided Multinoulli-distribution. Simultaneously, we minimize entropy and enforce prediction consistency for each instance. Our simple approach successfully realizes semantic-based novel data clustering provided the semantic similarity between label-unlabeled classes. We demonstrate the discriminative capacity of our approaches in image and video modalities. Moreover, we perform extensive ablation studies regarding data, networks, and our framework components to provide better insights. Our approach maintains ~94%, ~93%, and ~85%, classification accuracy in labeled data while achieving ~90%, ~84%, and ~72% clustering accuracy for novel categories for Cifar10, UCF101, and MPSC-ARL datasets that matches state-of-the-art approaches without any external clustering.
NEV-NCD: Negative Learning, Entropy, and Variance regularization based novel action categories discovery
Apr 14, 2023



Novel Categories Discovery (NCD) facilitates learning from a partially annotated label space and enables deep learning (DL) models to operate in an open-world setting by identifying and differentiating instances of novel classes based on the labeled data notions. One of the primary assumptions of NCD is that the novel label space is perfectly disjoint and can be equipartitioned, but it is rarely realized by most NCD approaches in practice. To better align with this assumption, we propose a novel single-stage joint optimization-based NCD method, Negative learning, Entropy, and Variance regularization NCD (NEV-NCD). We demonstrate the efficacy of NEV-NCD in previously unexplored NCD applications of video action recognition (VAR) with the public UCF101 dataset and a curated in-house partial action-space annotated multi-view video dataset. We perform a thorough ablation study by varying the composition of final joint loss and associated hyper-parameters. During our experiments with UCF101 and multi-view action dataset, NEV-NCD achieves ~ 83% classification accuracy in test instances of labeled data. NEV-NCD achieves ~ 70% clustering accuracy over unlabeled data outperforming both naive baselines (by ~ 40%) and state-of-the-art pseudo-labeling-based approaches (by ~ 3.5%) over both datasets. Further, we propose to incorporate optional view-invariant feature learning with the multiview dataset to identify novel categories from novel viewpoints. Our additional view-invariance constraint improves the discriminative accuracy for both known and unknown categories by ~ 10% for novel viewpoints.
Progressive Transformation Learning For Leveraging Virtual Images in Training
Nov 03, 2022To effectively interrogate UAV-based images for detecting objects of interest, such as humans, it is essential to acquire large-scale UAV-based datasets that include human instances with various poses captured from widely varying viewing angles. As a viable alternative to laborious and costly data curation, we introduce Progressive Transformation Learning (PTL), which gradually augments a training dataset by adding transformed virtual images with enhanced realism. Generally, a virtual2real transformation generator in the conditional GAN framework suffers from quality degradation when a large domain gap exists between real and virtual images. To deal with the domain gap, PTL takes a novel approach that progressively iterates the following three steps: 1) select a subset from a pool of virtual images according to the domain gap, 2) transform the selected virtual images to enhance realism, and 3) add the transformed virtual images to the training set while removing them from the pool. In PTL, accurately quantifying the domain gap is critical. To do that, we theoretically demonstrate that the feature representation space of a given object detector can be modeled as a multivariate Gaussian distribution from which the Mahalanobis distance between a virtual object and the Gaussian distribution of each object category in the representation space can be readily computed. Experiments show that PTL results in a substantial performance increase over the baseline, especially in the small data and the cross-domain regime.
Negative Samples are at Large: Leveraging Hard-distance Elastic Loss for Re-identification
Jul 20, 2022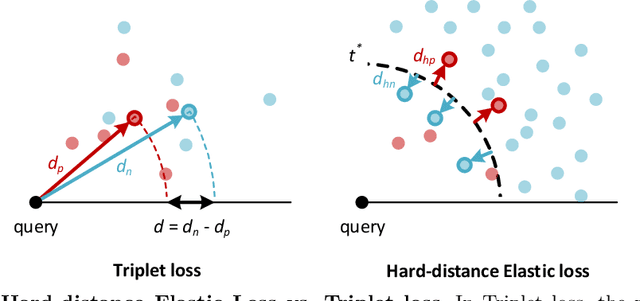
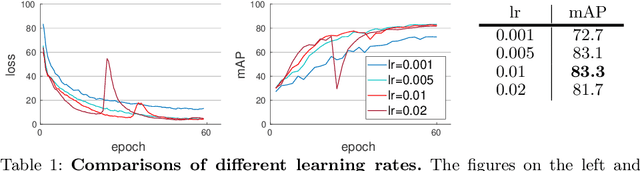
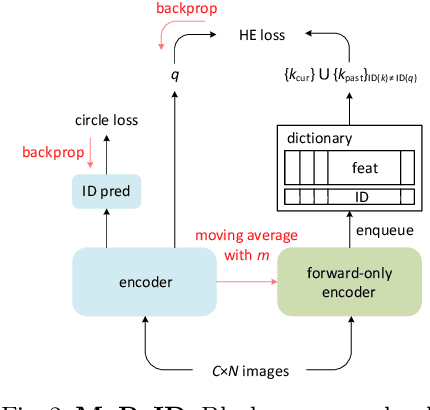
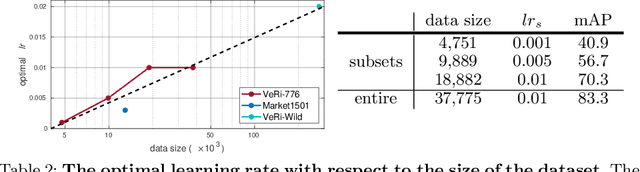
We present a Momentum Re-identification (MoReID) framework that can leverage a very large number of negative samples in training for general re-identification task. The design of this framework is inspired by Momentum Contrast (MoCo), which uses a dictionary to store current and past batches to build a large set of encoded samples. As we find it less effective to use past positive samples which may be highly inconsistent to the encoded feature property formed with the current positive samples, MoReID is designed to use only a large number of negative samples stored in the dictionary. However, if we train the model using the widely used Triplet loss that uses only one sample to represent a set of positive/negative samples, it is hard to effectively leverage the enlarged set of negative samples acquired by the MoReID framework. To maximize the advantage of using the scaled-up negative sample set, we newly introduce Hard-distance Elastic loss (HE loss), which is capable of using more than one hard sample to represent a large number of samples. Our experiments demonstrate that a large number of negative samples provided by MoReID framework can be utilized at full capacity only with the HE loss, achieving the state-of-the-art accuracy on three re-ID benchmarks, VeRi-776, Market-1501, and VeRi-Wild.
A Multi-purpose Real Haze Benchmark with Quantifiable Haze Levels and Ground Truth
Jun 13, 2022


Imagery collected from outdoor visual environments is often degraded due to the presence of dense smoke or haze. A key challenge for research in scene understanding in these degraded visual environments (DVE) is the lack of representative benchmark datasets. These datasets are required to evaluate state-of-the-art object recognition and other computer vision algorithms in degraded settings. In this paper, we address some of these limitations by introducing the first paired real image benchmark dataset with hazy and haze-free images, and in-situ haze density measurements. This dataset was produced in a controlled environment with professional smoke generating machines that covered the entire scene, and consists of images captured from the perspective of both an unmanned aerial vehicle (UAV) and an unmanned ground vehicle (UGV). We also evaluate a set of representative state-of-the-art dehazing approaches as well as object detectors on the dataset. The full dataset presented in this paper, including the ground truth object classification bounding boxes and haze density measurements, is provided for the community to evaluate their algorithms at: https://a2i2-archangel.vision. A subset of this dataset has been used for the Object Detection in Haze Track of CVPR UG2 2022 challenge.
Exploring Cross-Domain Pretrained Model for Hyperspectral Image Classification
Apr 07, 2022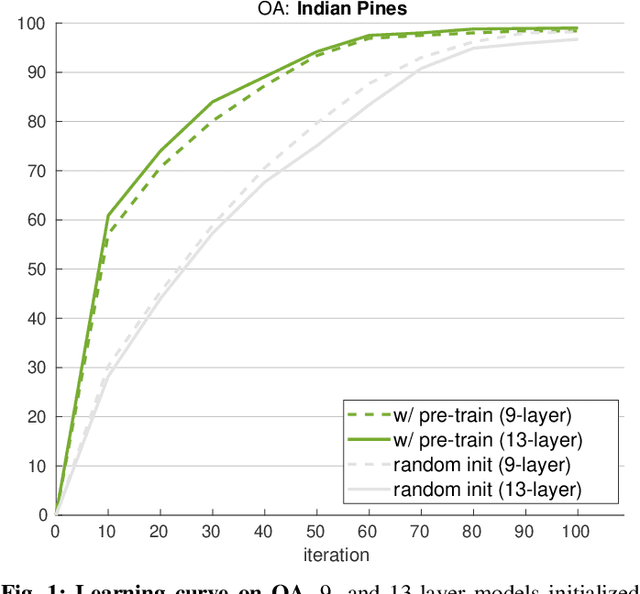
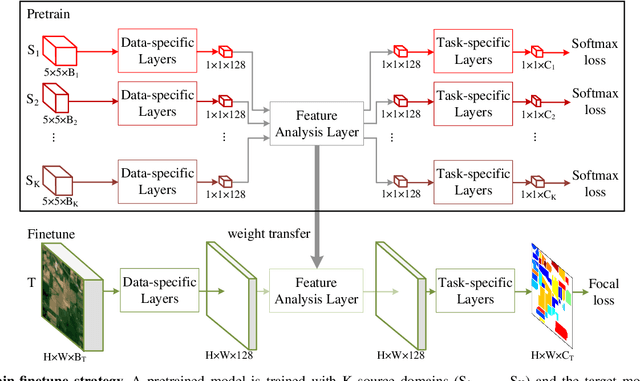
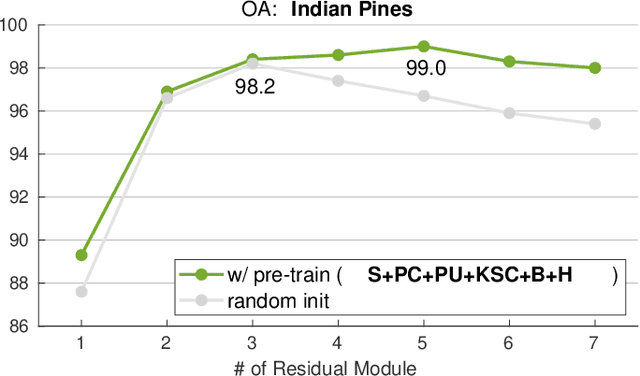
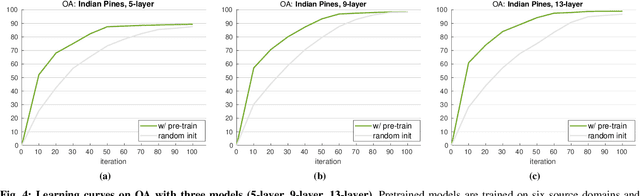
A pretrain-finetune strategy is widely used to reduce the overfitting that can occur when data is insufficient for CNN training. First few layers of a CNN pretrained on a large-scale RGB dataset are capable of acquiring general image characteristics which are remarkably effective in tasks targeted for different RGB datasets. However, when it comes down to hyperspectral domain where each domain has its unique spectral properties, the pretrain-finetune strategy no longer can be deployed in a conventional way while presenting three major issues: 1) inconsistent spectral characteristics among the domains (e.g., frequency range), 2) inconsistent number of data channels among the domains, and 3) absence of large-scale hyperspectral dataset. We seek to train a universal cross-domain model which can later be deployed for various spectral domains. To achieve, we physically furnish multiple inlets to the model while having a universal portion which is designed to handle the inconsistent spectral characteristics among different domains. Note that only the universal portion is used in the finetune process. This approach naturally enables the learning of our model on multiple domains simultaneously which acts as an effective workaround for the issue of the absence of large-scale dataset. We have carried out a study to extensively compare models that were trained using cross-domain approach with ones trained from scratch. Our approach was found to be superior both in accuracy and in training efficiency. In addition, we have verified that our approach effectively reduces the overfitting issue, enabling us to deepen the model up to 13 layers (from 9) without compromising the accuracy.
DBF: Dynamic Belief Fusion for Combining Multiple Object Detectors
Apr 06, 2022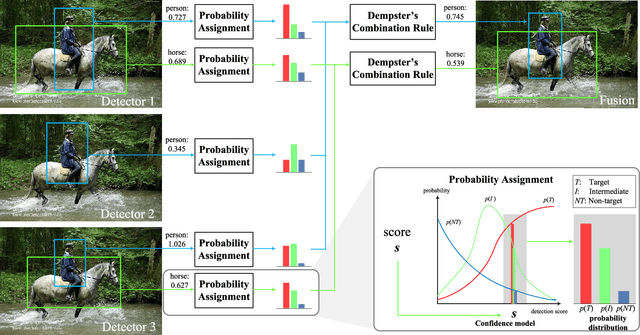
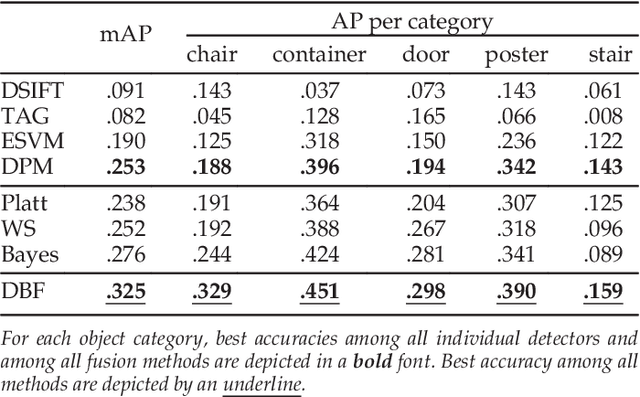
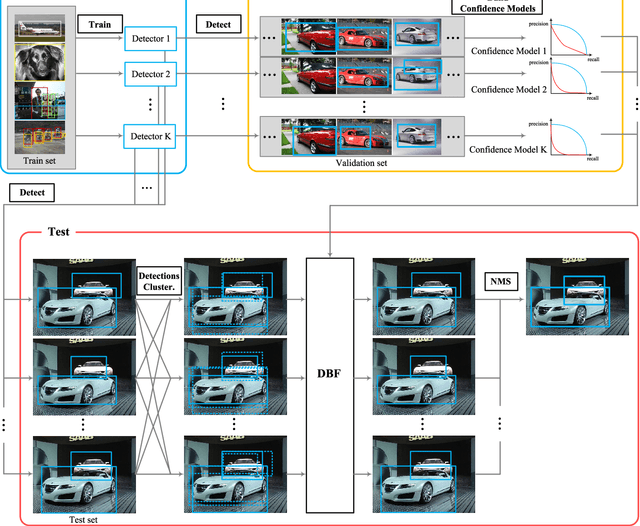
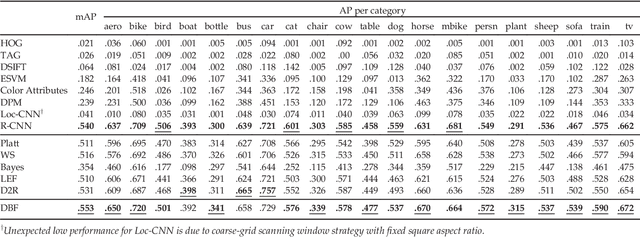
In this paper, we propose a novel and highly practical score-level fusion approach called dynamic belief fusion (DBF) that directly integrates inference scores of individual detections from multiple object detection methods. To effectively integrate the individual outputs of multiple detectors, the level of ambiguity in each detection score is estimated using a confidence model built on a precision-recall relationship of the corresponding detector. For each detector output, DBF then calculates the probabilities of three hypotheses (target, non-target, and intermediate state (target or non-target)) based on the confidence level of the detection score conditioned on the prior confidence model of individual detectors, which is referred to as basic probability assignment. The probability distributions over three hypotheses of all the detectors are optimally fused via the Dempster's combination rule. Experiments on the ARL, PASCAL VOC 07, and 12 datasets show that the detection accuracy of the DBF is significantly higher than any of the baseline fusion approaches as well as individual detectors used for the fusion.
* TPAMI publication