 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-learning via Language Model In-context Tuning
Oct 15, 2021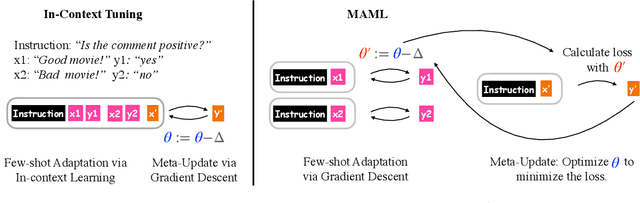
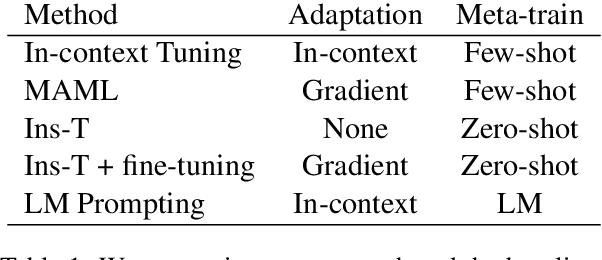
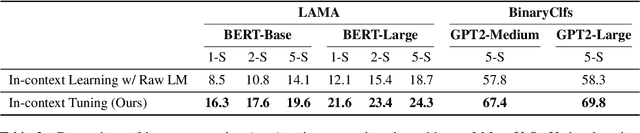
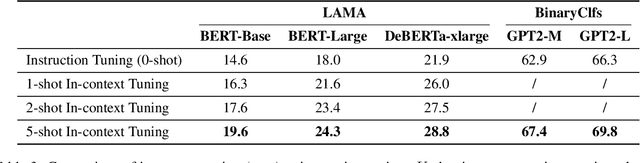
The goal of meta-learning is to learn to adapt to a new task with only a few labeled examples. To tackle this problem in NLP, we propose $\textit{in-context tuning}$, which recasts adaptation and prediction as a simple sequence prediction problem: to form the input sequence, we concatenate the task instruction, the labeled examples, and the target input to predict; to meta-train the model to learn from in-context examples, we fine-tune a pre-trained language model (LM) to predict the target label from the input sequences on a collection of tasks. We benchmark our method on two collections of text classification tasks: LAMA and BinaryClfs. Compared to first-order MAML which adapts the model with gradient descent, our method better leverages the inductive bias of LMs to perform pattern matching, and outperforms MAML by an absolute $6\%$ AUC ROC score on BinaryClfs, with increasing advantage w.r.t. model size. Compared to non-fine-tuned in-context learning (i.e. prompting a raw LM), in-context tuning directly learns to learn from in-context examples. On BinaryClfs, in-context tuning improves the average AUC-ROC score by an absolute $10\%$, and reduces the variance with respect to example ordering by 6x and example choices by 2x.
Types of Out-of-Distribution Texts and How to Detect Them
Sep 14, 2021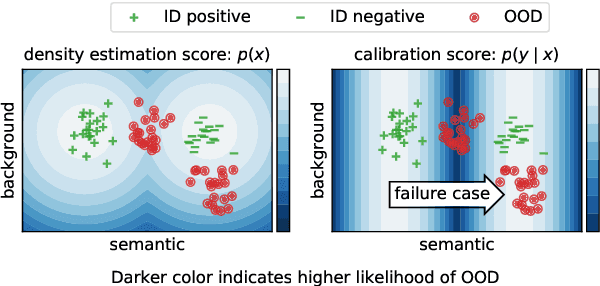
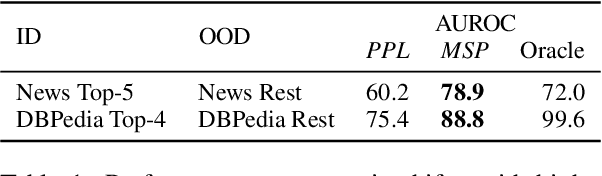
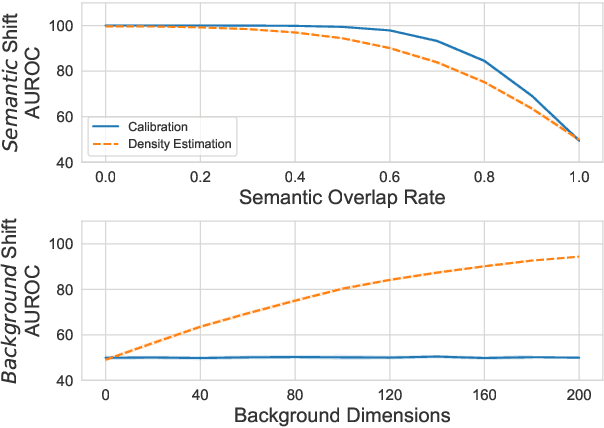
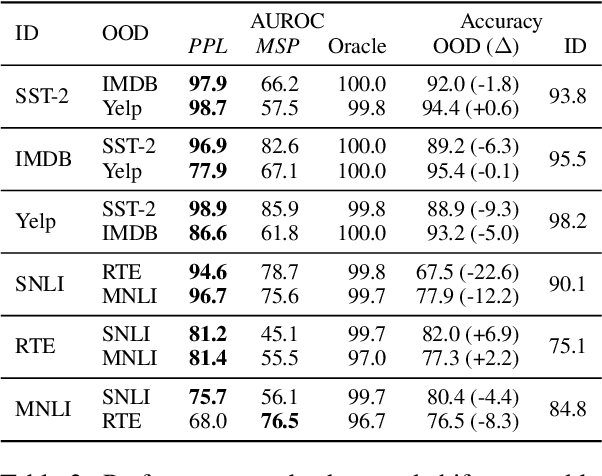
Despite agreement on the importance of detecting out-of-distribution (OOD) examples, there is little consensus on the formal definition of OOD examples and how to best detect them. We categorize these examples by whether they exhibit a background shift or a semantic shift, and find that the two major approaches to OOD detection, model calibration and density estimation (language modeling for text), have distinct behavior on these types of OOD data. Across 14 pairs of in-distribution and OOD English natural language understanding datasets, we find that density estimation methods consistently beat calibration methods in background shift settings, while performing worse in semantic shift settings. In addition, we find that both methods generally fail to detect examples from challenge data, highlighting a weak spot for current methods. Since no single method works well across all settings, our results call for an explicit definition of OOD examples when evaluating different detection methods.
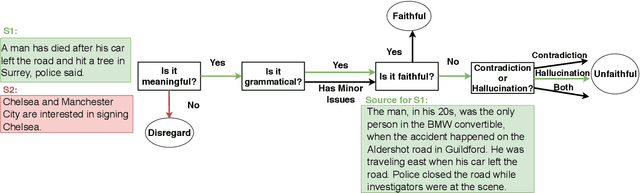
Faithful or Extractive? On Mitigating the Faithfulness-Abstractiveness Trade-off in Abstractive Summarization
Aug 31, 2021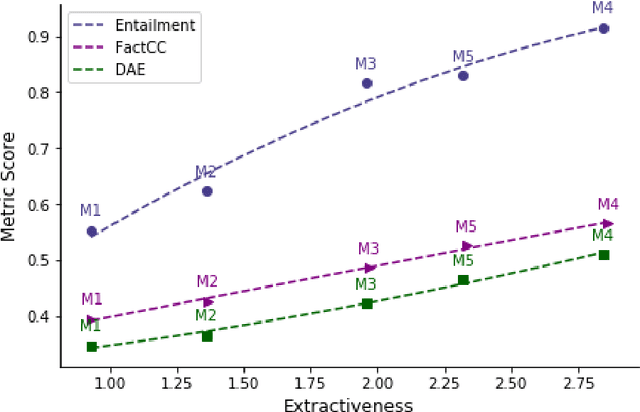

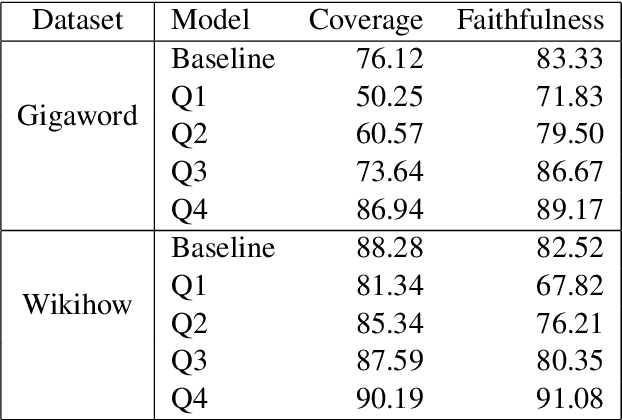
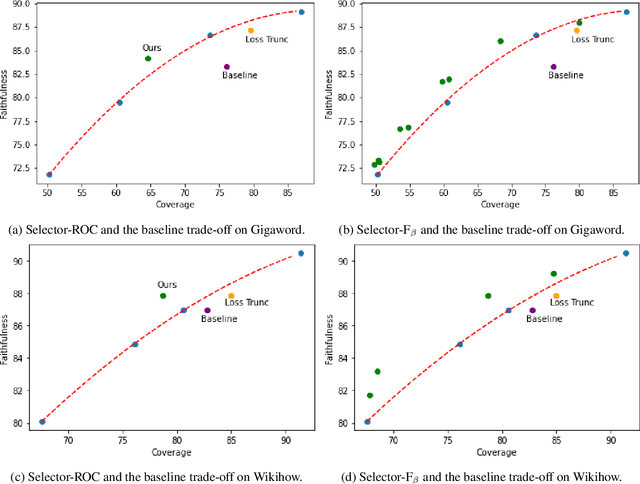
Despite recent progress in abstractive summarization, systems still suffer from faithfulness errors. While prior work has proposed models that improve faithfulness, it is unclear whether the improvement comes from an increased level of extractiveness of the model outputs as one naive way to improve faithfulness is to make summarization models more extractive. In this work, we present a framework for evaluating the effective faithfulness of summarization systems, by generating a faithfulnessabstractiveness trade-off curve that serves as a control at different operating points on the abstractiveness spectrum. We then show that the Maximum Likelihood Estimation (MLE) baseline as well as a recently proposed method for improving faithfulness, are both worse than the control at the same level of abstractiveness. Finally, we learn a selector to identify the most faithful and abstractive summary for a given document, and show that this system can attain higher faithfulness scores in human evaluations while being more abstractive than the baseline system on two datasets. Moreover, we show that our system is able to achieve a better faithfulness-abstractiveness trade-off than the control at the same level of abstractiveness.
An Investigation of the effectiveness of Counterfactually Augmented Data
Jul 01, 2021

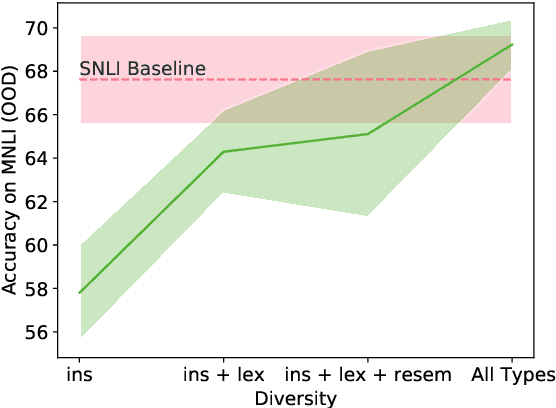

While pretrained language models achieve excellent performance on natural language understanding benchmarks, they tend to rely on spurious correlations and generalize poorly to out-of-distribution (OOD) data. Recent work has explored using counterfactually-augmented data (CAD) -- data generated by minimally perturbing examples to flip the ground-truth label -- to identify robust features that are invariant under distribution shift. However, empirical results using CAD for OOD generalization have been mixed. To explain this discrepancy, we draw insights from a linear Gaussian model and demonstrate the pitfalls of CAD. Specifically, we show that (a) while CAD is effective at identifying robust features, it may prevent the model from learning unperturbed robust features, and (b) CAD may exacerbate existing spurious correlations in the data. Our results show that the lack of perturbation diversity in current CAD datasets limits its effectiveness on OOD generalization, calling for innovative crowdsourcing procedures to elicit diverse perturbation of examples.
Unsupervised Extractive Summarization using Pointwise Mutual Information
Feb 11, 2021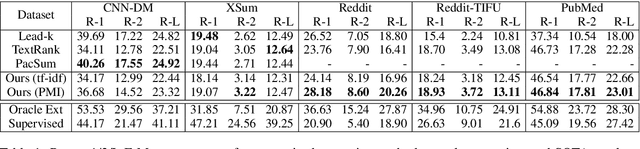
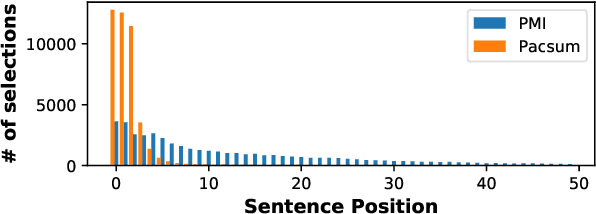

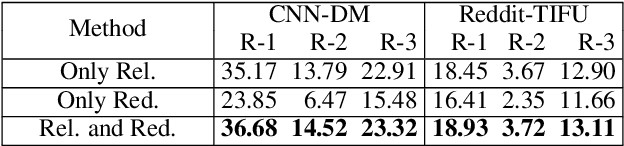
Unsupervised approaches to extractive summarization usually rely on a notion of sentence importance defined by the semantic similarity between a sentence and the document. We propose new metrics of relevance and redundancy using pointwise mutual information (PMI) between sentences, which can be easily computed by a pre-trained language model. Intuitively, a relevant sentence allows readers to infer the document content (high PMI with the document), and a redundant sentence can be inferred from the summary (high PMI with the summary). We then develop a greedy sentence selection algorithm to maximize relevance and minimize redundancy of extracted sentences. We show that our method outperforms similarity-based methods on datasets in a range of domains including news, medical journal articles, and personal anecdotes.
Text Generation by Learning from Off-Policy Demonstrations
Sep 16, 2020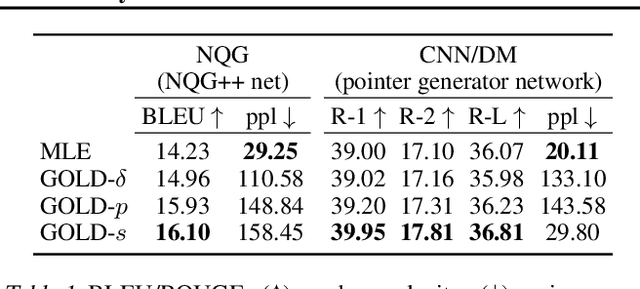
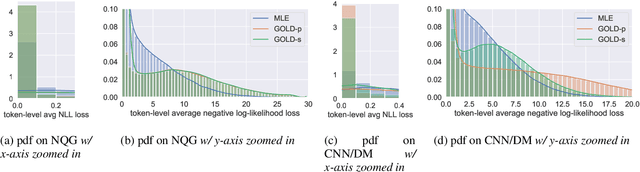
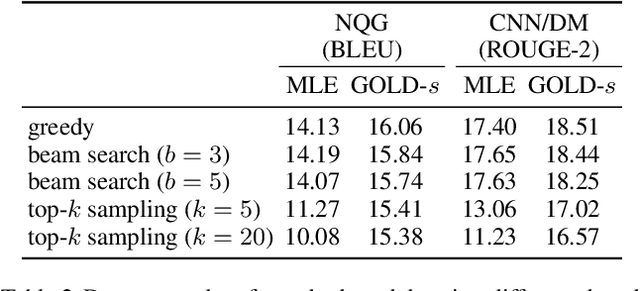
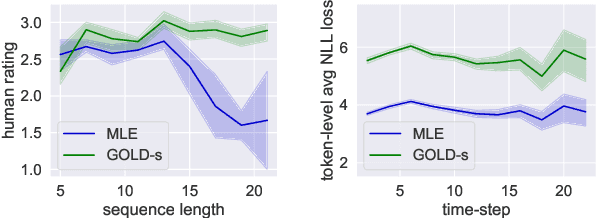
Current approaches to text generation largely rely on autoregressive models and maximum likelihood estimation. This paradigm leads to (i) diverse but low-quality samples due to mismatched learning objective and evaluation metric (likelihood vs. quality) and (ii) exposure bias due to mismatched history distributions (gold vs. model-generated). To alleviate these problems, we frame text generation as a reinforcement learning (RL) problem with expert demonstrations (i.e., the training data), where the goal is to maximize quality given model-generated histories. Prior RL approaches to generation often face optimization issues due to the large action space and sparse reward. We propose GOLD (generation by off-policy learning from demonstrations): an algorithm that learns from the off-policy demonstrations by importance weighting and does not suffer from degenerative solutions. We find that GOLD outperforms the baselines according to automatic and human evaluation on summarization, question generation, and machine translation, including attaining state-of-the-art results for CNN/DailyMail summarization. Further, we show that models trained by GOLD are less sensitive to decoding algorithms and the generation quality does not degrade much as the length increases.
An Empirical Study on Robustness to Spurious Correlations using Pre-trained Language Models
Aug 11, 2020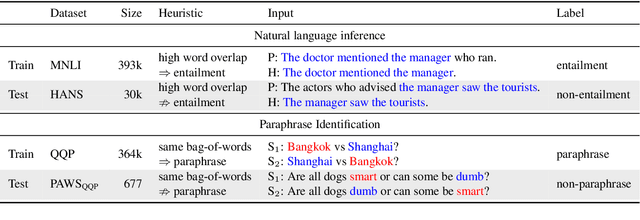
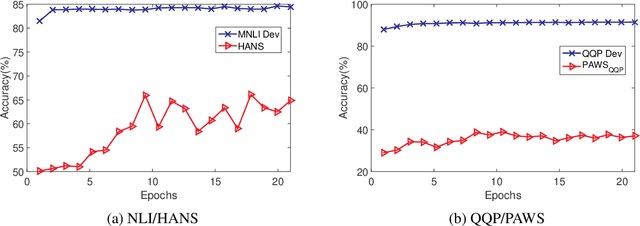
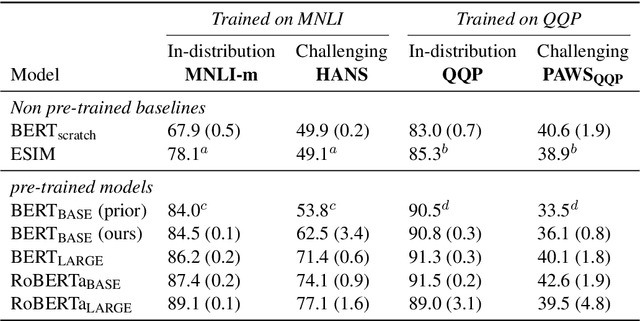
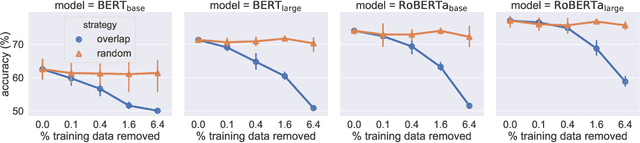
Recent work has shown that pre-trained language models such as BERT improve robustness to spurious correlations in the dataset. Intrigued by these results, we find that the key to their success is generalization from a small amount of counterexamples where the spurious correlations do not hold. When such minority examples are scarce, pre-trained models perform as poorly as models trained from scratch. In the case of extreme minority, we propose to use multi-task learning (MTL) to improve generalization. Our experiments on natural language inference and paraphrase identification show that MTL with the right auxiliary tasks significantly improves performance on challenging examples without hurting the in-distribution performance. Further, we show that the gain from MTL mainly comes from improved generalization from the minority examples. Our results highlight the importance of data diversity for overcoming spurious correlations.
FEQA: A Question Answering Evaluation Framework for Faithfulness Assessment in Abstractive Summarization
May 07, 2020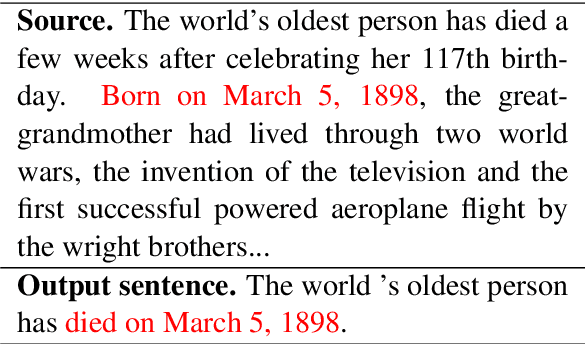

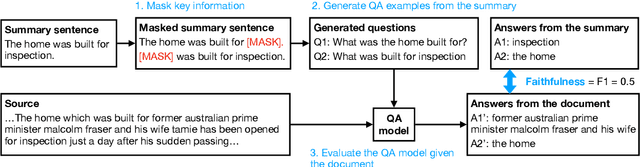
Neural abstractive summarization models are prone to generate content inconsistent with the source document, i.e. unfaithful. Existing automatic metrics do not capture such mistakes effectively. We tackle the problem of evaluating faithfulness of a generated summary given its source document. We first collected human annotations of faithfulness for outputs from numerous models on two datasets. We find that current models exhibit a trade-off between abstractiveness and faithfulness: outputs with less word overlap with the source document are more likely to be unfaithful. Next, we propose an automatic question answering (QA) based metric for faithfulness, FEQA, which leverages recent advances in reading comprehension. Given question-answer pairs generated from the summary, a QA model extracts answers from the document; non-matched answers indicate unfaithful information in the summary. Among metrics based on word overlap, embedding similarity, and learned language understanding models, our QA-based metric has significantly higher correlation with human faithfulness scores, especially on highly abstractive summaries.
Different Set Domain Adaptation for Brain-Computer Interfaces: A Label Alignment Approach
Dec 29, 2019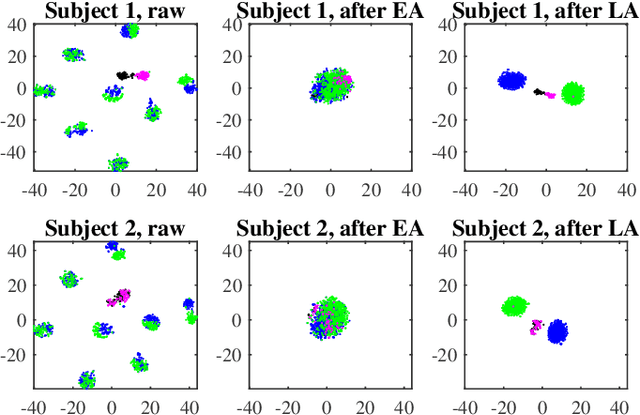
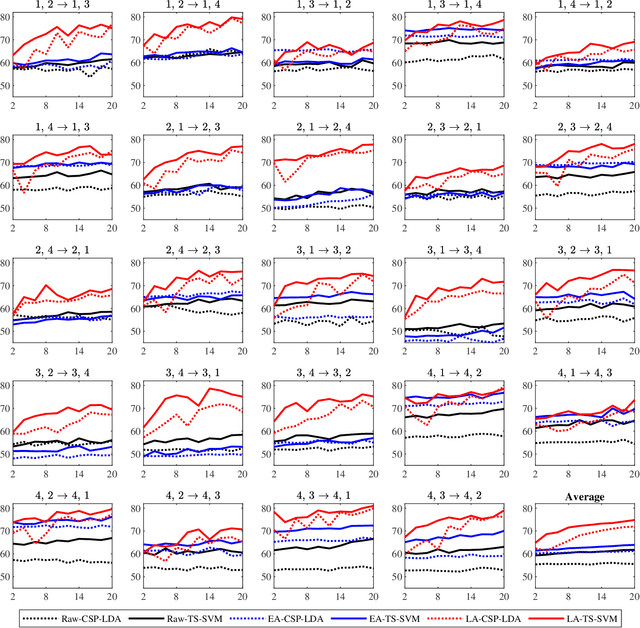
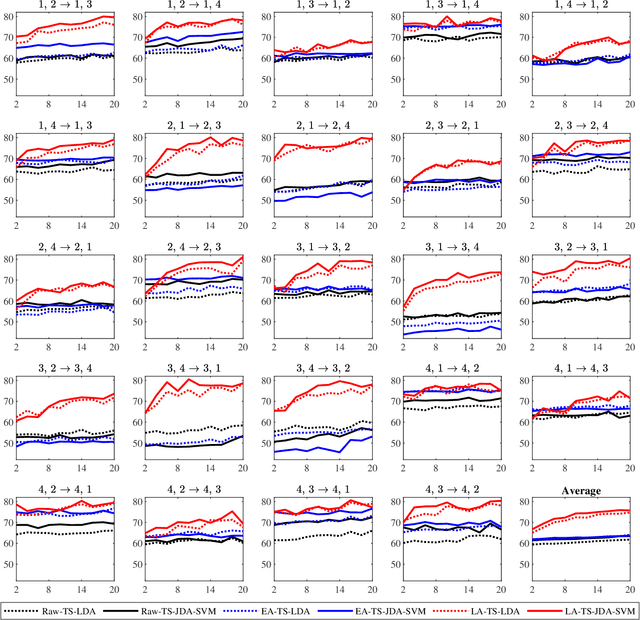
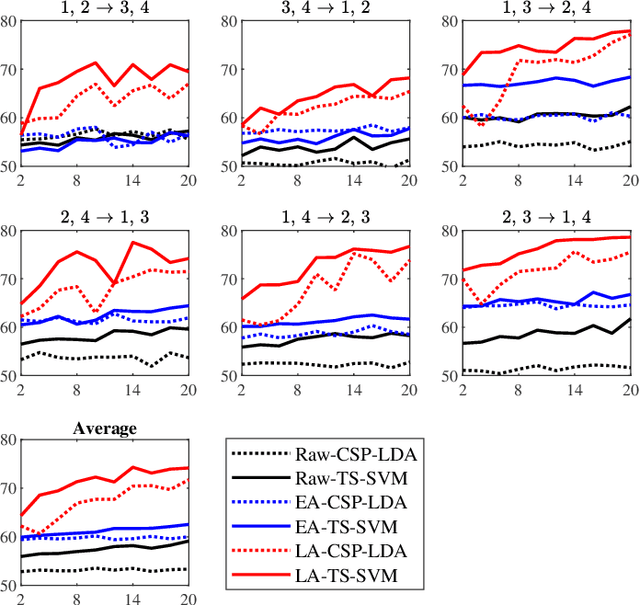
A brain-computer interface (BCI) system usually needs a long calibration session for each new subject/task to adjust its parameters, which impedes its transition from the laboratory to real-world applications. Domain adaptation, which leverages labeled data from auxiliary subjects/tasks (source domains), has demonstrated its effectiveness in reducing such calibration effort. Currently, most domain adaptation approaches require the source domains to have the same feature space and label space as the target domain, which limits their applications, as the auxiliary data may have different feature spaces and/or different label spaces. This paper considers different set domain adaptation for BCIs, i.e., the source and target domains have different label spaces. We introduce a practical setting of different label sets for BCIs, and propose a novel label alignment (LA) approach to align the source label space with the target label space. It has three desirable properties: 1) LA only needs as few as one labeled sample from each class of the target subject; 2) LA can be used as a preprocessing step before different feature extraction and classification algorithms; and, 3) LA can be integrated with other domain adaptation approaches to achieve even better performance. Experiments on two motor imagery datasets demonstrated the effectiveness of LA.
A Dynamic Strategy Coach for Effective Negotiation
Sep 30, 2019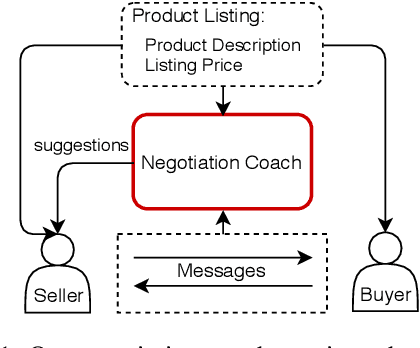
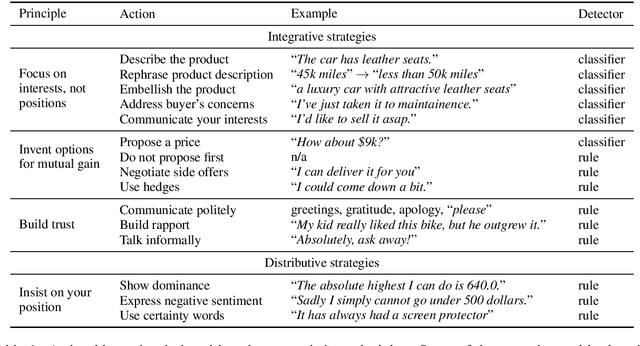


Negotiation is a complex activity involving strategic reasoning, persuasion, and psychology. An average person is often far from an expert in negotiation. Our goal is to assist humans to become better negotiators through a machine-in-the-loop approach that combines machine's advantage at data-driven decision-making and human's language generation ability. We consider a bargaining scenario where a seller and a buyer negotiate the price of an item for sale through a text-based dialog. Our negotiation coach monitors messages between them and recommends tactics in real time to the seller to get a better deal (e.g., "reject the proposal and propose a price", "talk about your personal experience with the product"). The best strategy and tactics largely depend on the context (e.g., the current price, the buyer's attitude). Therefore, we first identify a set of negotiation tactics, then learn to predict the best strategy and tactics in a given dialog context from a set of human-human bargaining dialogs. Evaluation on human-human dialogs shows that our coach increases the profits of the seller by almost 60%.