 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStain Normalization of Hematology Slides using Neural Color Transfer
Sep 10, 2024Deep learning is popularly used for analyzing pathology images, but variations in image properties can limit the effectiveness of the models. The study aims to develop a method that transfers the variability present in the training set to unseen images, improving the model's ability to make accurate inferences. YOLOv5 was trained on peripheral blood and bone marrow sample images and Neural Color Transfer techniques were used to incorporate invariance. The results showed significant improvement in detecting WBCs from untrained samples after normalization, highlighting the potential of deep learning-based normalization techniques for inference robustness.
Reinforcement Learning for Adaptive Traffic Signal Control: Turn-Based and Time-Based Approaches to Reduce Congestion
Sep 01, 2024



The growing demand for road use in urban areas has led to significant traffic congestion, posing challenges that are costly to mitigate through infrastructure expansion alone. As an alternative, optimizing existing traffic management systems, particularly through adaptive traffic signal control, offers a promising solution. This paper explores the use of Reinforcement Learning (RL) to enhance traffic signal operations at intersections, aiming to reduce congestion without extensive sensor networks. We introduce two RL-based algorithms: a turn-based agent, which dynamically prioritizes traffic signals based on real-time queue lengths, and a time-based agent, which adjusts signal phase durations according to traffic conditions while following a fixed phase cycle. By representing the state as a scalar queue length, our approach simplifies the learning process and lowers deployment costs. The algorithms were tested in four distinct traffic scenarios using seven evaluation metrics to comprehensively assess performance. Simulation results demonstrate that both RL algorithms significantly outperform conventional traffic signal control systems, highlighting their potential to improve urban traffic flow efficiently.
A Permuted Autoregressive Approach to Word-Level Recognition for Urdu Digital Text
Aug 30, 2024

This research paper introduces a novel word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text, leveraging transformer-based architectures and attention mechanisms to address the distinct challenges of Urdu script recognition, including its diverse text styles, fonts, and variations. The model employs a permuted autoregressive sequence (PARSeq) architecture, which enhances its performance by enabling context-aware inference and iterative refinement through the training of multiple token permutations. This method allows the model to adeptly manage character reordering and overlapping characters, commonly encountered in Urdu script. Trained on a dataset comprising approximately 160,000 Urdu text images, the model demonstrates a high level of accuracy in capturing the intricacies of Urdu script, achieving a CER of 0.178. Despite ongoing challenges in handling certain text variations, the model exhibits superior accuracy and effectiveness in practical applications. Future work will focus on refining the model through advanced data augmentation techniques and the integration of context-aware language models to further enhance its performance and robustness in Urdu text recognition.
Urdu Digital Text Word Optical Character Recognition Using Permuted Auto Regressive Sequence Modeling
Aug 27, 2024This research paper introduces an innovative word-level Optical Character Recognition (OCR) model specifically designed for digital Urdu text recognition. Utilizing transformer-based architectures and attention mechanisms, the model was trained on a comprehensive dataset of approximately 160,000 Urdu text images, achieving a character error rate (CER) of 0.178, which highlights its superior accuracy in recognizing Urdu characters. The model's strength lies in its unique architecture, incorporating the permuted autoregressive sequence (PARSeq) model, which allows for context-aware inference and iterative refinement by leveraging bidirectional context information to enhance recognition accuracy. Furthermore, its capability to handle a diverse range of Urdu text styles, fonts, and variations enhances its applicability in real-world scenarios. Despite its promising results, the model has some limitations, such as difficulty with blurred images, non-horizontal orientations, and overlays of patterns, lines, or other text, which can occasionally lead to suboptimal performance. Additionally, trailing or following punctuation marks can introduce noise into the recognition process. Addressing these challenges will be a focus of future research, aiming to refine the model further, explore data augmentation techniques, optimize hyperparameters, and integrate contextual improvements for more accurate and efficient Urdu text recognition.
Audio-Visual Transformer Based Crowd Counting
Sep 04, 2021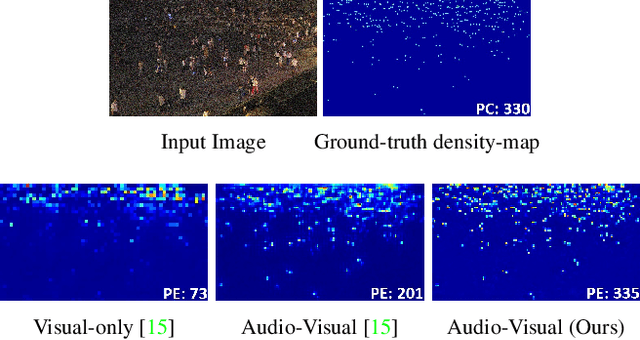
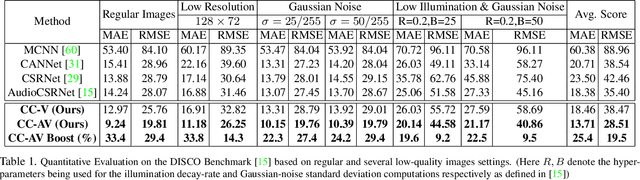
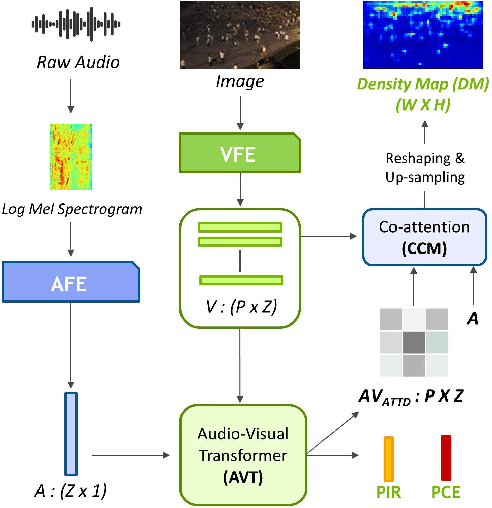
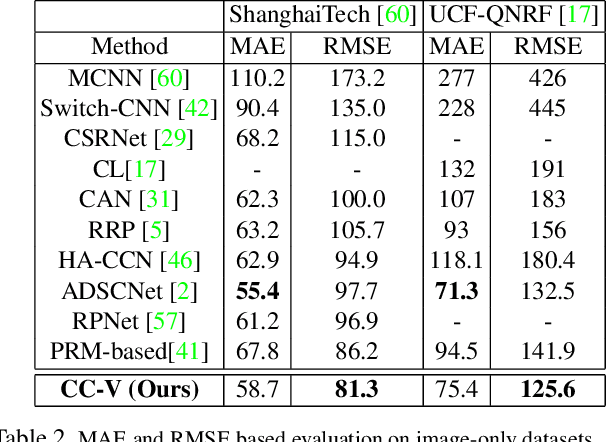
Crowd estimation is a very challenging problem. The most recent study tries to exploit auditory information to aid the visual models, however, the performance is limited due to the lack of an effective approach for feature extraction and integration. The paper proposes a new audiovisual multi-task network to address the critical challenges in crowd counting by effectively utilizing both visual and audio inputs for better modalities association and productive feature extraction. The proposed network introduces the notion of auxiliary and explicit image patch-importance ranking (PIR) and patch-wise crowd estimate (PCE) information to produce a third (run-time) modality. These modalities (audio, visual, run-time) undergo a transformer-inspired cross-modality co-attention mechanism to finally output the crowd estimate. To acquire rich visual features, we propose a multi-branch structure with transformer-style fusion in-between. Extensive experimental evaluations show that the proposed scheme outperforms the state-of-the-art networks under all evaluation settings with up to 33.8% improvement. We also analyze and compare the vision-only variant of our network and empirically demonstrate its superiority over previous approaches.
m2caiSeg: Semantic Segmentation of Laparoscopic Images using Convolutional Neural Networks
Aug 23, 2020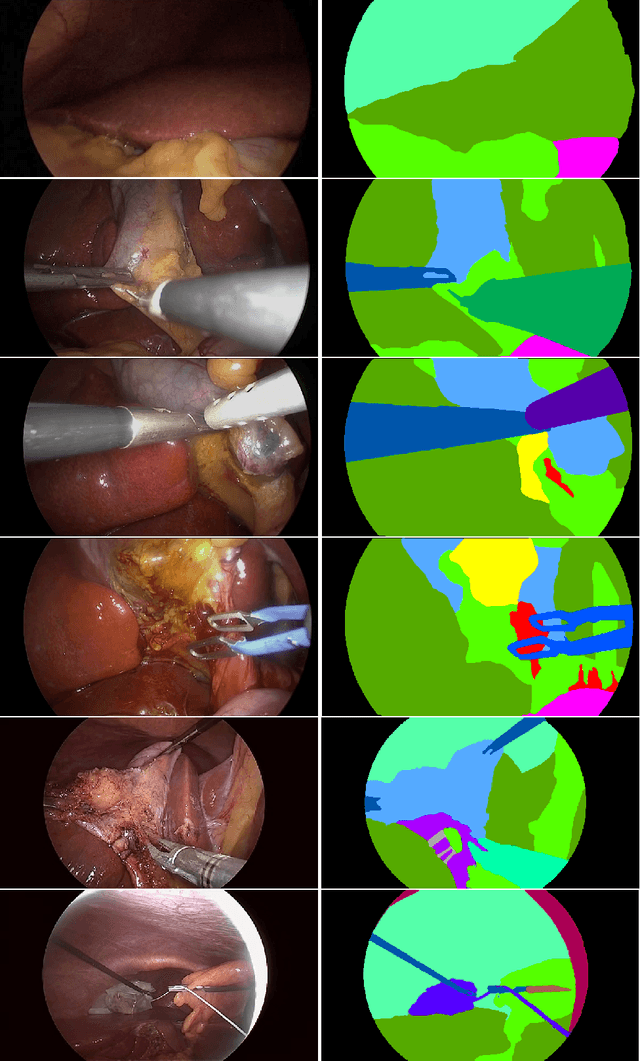
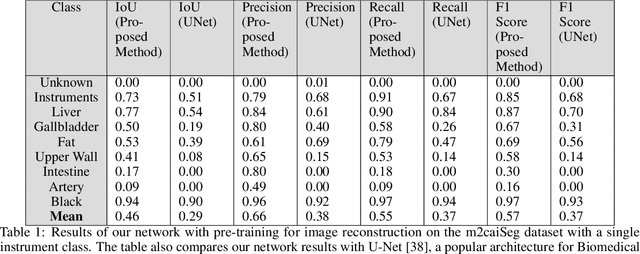
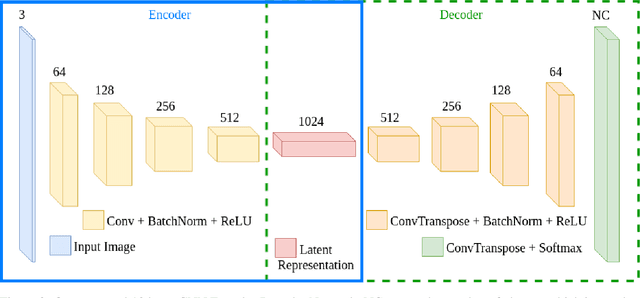
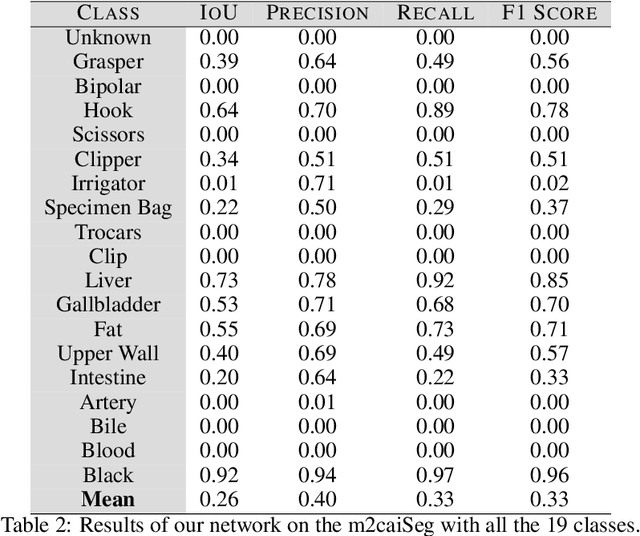
Autonomous surgical procedures, in particular minimal invasive surgeries, are the next frontier for Artificial Intelligence research. However, the existing challenges include precise identification of the human anatomy and the surgical settings, and modeling the environment for training of an autonomous agent. To address the identification of human anatomy and the surgical settings, we propose a deep learning based semantic segmentation algorithm to identify and label the tissues and organs in the endoscopic video feed of the human torso region. We present an annotated dataset, m2caiSeg, created from endoscopic video feeds of real-world surgical procedures. Overall, the data consists of 307 images, each of which is annotated for the organs and different surgical instruments present in the scene. We propose and train a deep convolutional neural network for the semantic segmentation task. To cater for the low quantity of annotated data, we use unsupervised pre-training and data augmentation. The trained model is evaluated on an independent test set of the proposed dataset. We obtained a F1 score of 0.33 while using all the labeled categories for the semantic segmentation task. Secondly, we labeled all instruments into an 'Instruments' superclass to evaluate the model's performance on discerning the various organs and obtained a F1 score of 0.57. We propose a new dataset and a deep learning method for pixel level identification of various organs and instruments in a endoscopic surgical scene. Surgical scene understanding is one of the first steps towards automating surgical procedures.
ZoomCount: A Zooming Mechanism for Crowd Counting in Static Images
Feb 27, 2020


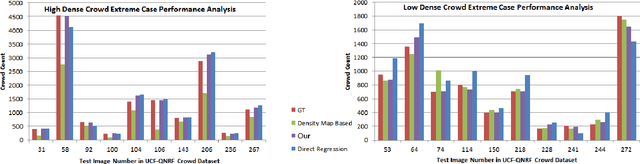
This paper proposes a novel approach for crowd counting in low to high density scenarios in static images. Current approaches cannot handle huge crowd diversity well and thus perform poorly in extreme cases, where the crowd density in different regions of an image is either too low or too high, leading to crowd underestimation or overestimation. The proposed solution is based on the observation that detecting and handling such extreme cases in a specialized way leads to better crowd estimation. Additionally, existing methods find it hard to differentiate between the actual crowd and the cluttered background regions, resulting in further count overestimation. To address these issues, we propose a simple yet effective modular approach, where an input image is first subdivided into fixed-size patches and then fed to a four-way classification module labeling each image patch as low, medium, high-dense or no-crowd. This module also provides a count for each label, which is then analyzed via a specifically devised novel decision module to decide whether the image belongs to any of the two extreme cases (very low or very high density) or a normal case. Images, specified as high- or low-density extreme or a normal case, pass through dedicated zooming or normal patch-making blocks respectively before routing to the regressor in the form of fixed-size patches for crowd estimate. Extensive experimental evaluations demonstrate that the proposed approach outperforms the state-of-the-art methods on four benchmarks under most of the evaluation criteria.