 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrade Guard: A Smart System for Short Answer Automated Grading
Apr 01, 2025



The advent of large language models (LLMs) in the education sector has provided impetus to automate grading short answer questions. LLMs make evaluating short answers very efficient, thus addressing issues like staff shortage. However, in the task of Automated Short Answer Grading (ASAG), LLM responses are influenced by diverse perspectives in their training dataset, leading to inaccuracies in evaluating nuanced or partially correct answers. To address this challenge, we propose a novel framework, Grade Guard. 1. To enhance the task-based specialization of the LLMs, the temperature parameter has been fine-tuned using Root Mean Square Error (RMSE). 2. Unlike traditional approaches, LLMs in Grade Guard compute an Indecisiveness Score (IS) along with the grade to reflect uncertainty in predicted grades. 3. Introduced Confidence-Aware Loss (CAL) to generate an optimized Indecisiveness Score (IS). 4. To improve reliability, self-reflection based on the optimized IS has been introduced into the framework, enabling human re-evaluation to minimize incorrect grade assignments. Our experimentation shows that the best setting of Grade Guard outperforms traditional methods by 19.16% RMSE in Upstage Solar Pro, 23.64% RMSE in Upstage Solar Mini, 4.00% RMSE in Gemini 1.5 Flash, and 10.20% RMSE in GPT 4-o Mini. Future work includes improving interpretability by generating rationales for grades to enhance accuracy. Expanding benchmark datasets and annotating them with domain-specific nuances will enhance grading accuracy. Finally, analyzing feedback to enhance confidence in predicted grades, reduce biases, optimize grading criteria, and personalize learning while supporting multilingual grading systems will make the solution more accurate, adaptable, fair, and inclusive.
Tchebichef Transform Domain-based Deep Learning Architecture for Image Super-resolution
Feb 23, 2021

The recent outbreak of COVID-19 has motivated researchers to contribute in the area of medical imaging using artificial intelligence and deep learning. Super-resolution (SR), in the past few years, has produced remarkable results using deep learning methods. The ability of deep learning methods to learn the non-linear mapping from low-resolution (LR) images to their corresponding high-resolution (HR) images leads to compelling results for SR in diverse areas of research. In this paper, we propose a deep learning based image super-resolution architecture in Tchebichef transform domain. This is achieved by integrating a transform layer into the proposed architecture through a customized Tchebichef convolutional layer ($TCL$). The role of TCL is to convert the LR image from the spatial domain to the orthogonal transform domain using Tchebichef basis functions. The inversion of the aforementioned transformation is achieved using another layer known as the Inverse Tchebichef convolutional Layer (ITCL), which converts back the LR images from the transform domain to the spatial domain. It has been observed that using the Tchebichef transform domain for the task of SR takes the advantage of high and low-frequency representation of images that makes the task of super-resolution simplified. We, further, introduce transfer learning approach to enhance the quality of Covid based medical images. It is shown that our architecture enhances the quality of X-ray and CT images of COVID-19, providing a better image quality that helps in clinical diagnosis. Experimental results obtained using the proposed Tchebichef transform domain super-resolution (TTDSR) architecture provides competitive results when compared with most of the deep learning methods employed using a fewer number of trainable parameters.
A Generalized Reinforcement Learning Algorithm for Online 3D Bin-Packing
Jul 01, 2020
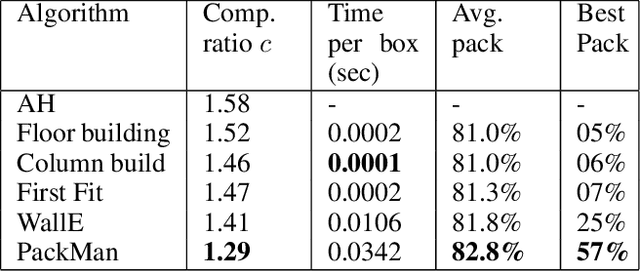
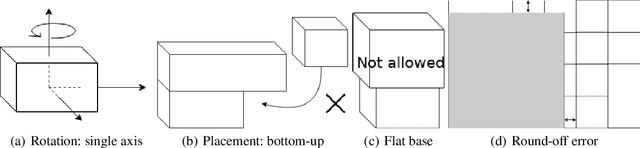

We propose a Deep Reinforcement Learning (Deep RL) algorithm for solving the online 3D bin packing problem for an arbitrary number of bins and any bin size. The focus is on producing decisions that can be physically implemented by a robotic loading arm, a laboratory prototype used for testing the concept. The problem considered in this paper is novel in two ways. First, unlike the traditional 3D bin packing problem, we assume that the entire set of objects to be packed is not known a priori. Instead, a fixed number of upcoming objects is visible to the loading system, and they must be loaded in the order of arrival. Second, the goal is not to move objects from one point to another via a feasible path, but to find a location and orientation for each object that maximises the overall packing efficiency of the bin(s). Finally, the learnt model is designed to work with problem instances of arbitrary size without retraining. Simulation results show that the RL-based method outperforms state-of-the-art online bin packing heuristics in terms of empirical competitive ratio and volume efficiency.